Dense Passage Retrieval for Open-Domain Question Answering
Posted Facico
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dense Passage Retrieval for Open-Domain Question Answering相关的知识,希望对你有一定的参考价值。
Dense Passage Retrieval for Open-Domain Question Answering
段落检索是open domian QA的重要问题
- 传统方法是使用稀疏向量空间模型,如TF-IDF或BM25
- 本文重点研究室是密集向量空间模型,密集表示采用简单的双层编码器框架,同时采用了非常少的问题和段落对
传统检索器的问题
- 传统检索器不能很好匹配语义关系,只能关键词匹配
- 而密集向量检索器通过语义训练,可以更好捕获语义信息
Dense Passage Retriever(DPR)
要在M个文档中找到top-k个相关的段落
-
DPR采用多种编码器EQ,将输入段落映射到d维向量,并匹配与问题最接近的k个段落
-
问题和段落的编码器使用两个不同的BERT,[CLS]作为输出
-
问题和段落相似性度量,使用精度较高的点积(类似BERT[Rep]的方法)
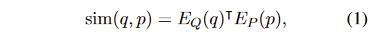
-
推理时,将段落编码器应用所有段落,使用开源器FAISS来进行问题相关的段落检索。最后找到top-k最相关的段落
训练部分
采用一个正例段落,n个负例段落的方式训练
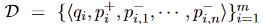
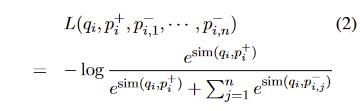
- 负例选择
- 1、随机选择
- 2、BM25获取top-n段落,去除正确答案
- 3、其他问题对应的正确段落
最后实验证明(2+3),采用其他n-1个问题对应的正确段落+一个BM25获取的top1段落进行组合,时间复杂度低,精度高
-
batch内负例方法
- 每个batch有B个问题,每个问题有对应的段落,构建B*B矩阵,则i≠j时是负例,i=j时是正例
- 这种方法是训练一个孪生网络结构的(如dual encoder)的有效策略,能极大提高训练实例的数量
-
有些数据集没有正例段落,或者正例段落不匹配
- 用BM25获取top-100的段落中排名靠前,且含有答案的段落作为(替换)正例段落;如果都没有则丢弃
实验
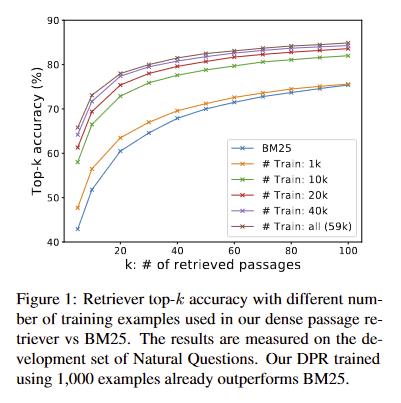
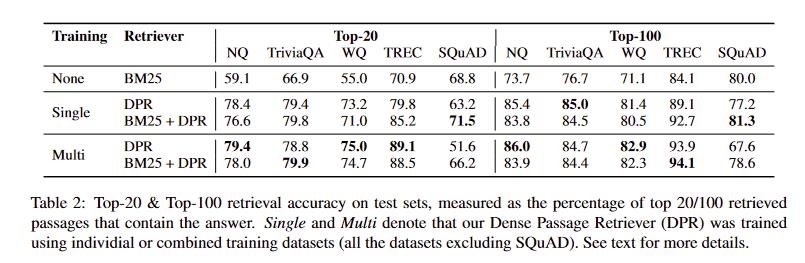
- 上面两个图都能看到DPR带来的提升,且混合数据集训练比单一数据集结果要好
- SQuAD因为question和passage存在较多重合的token,BM25效果较好
in-batch negative training
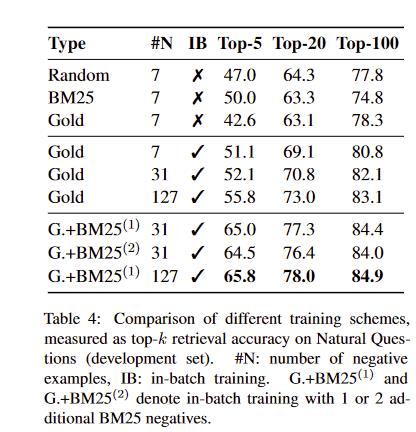
31+32 表示batch=32时,每个训练question除了原有31条In-batch negative,另外增加32条难度较大的负样本
- 这部分负样本是利用BM25,从passages中获取与每个训练question最相关、但不含answer的passage
- 可以看到增加难度较大负样本效果提升
泛化性更好
DPR比BM23泛化性更好
时间效率
- DPR要提前计算embedding,并用FAISS索引,耗时大,但是处理完可以离线并行处理
- 若提前有了上面的计算和索引,借助FAISS,DPR后续检索很高效,速度大致是BM25/Lucene的40倍
总结
- 1、DPR证明了这种检索方式提供更多的语义行,使用dual-encoder,利用预训练模型进行finetune,充分利用了预训练模型的海量知识
- 2、明显提升在线的处理速度,但预处理海量的passage的embedding是难点
- 3、用in-batch negative采样负样本,并用MB25增加难度较大的负样本,提升性能
以上是关于Dense Passage Retrieval for Open-Domain Question Answering的主要内容,如果未能解决你的问题,请参考以下文章