翻译翻译什么TMD叫EXPLAIN
Posted 一条coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译翻译什么TMD叫EXPLAIN相关的知识,希望对你有一定的参考价值。
翻译翻译什么TMD叫EXPLAIN
你给翻译翻译,什么叫惊喜,什么他妈的叫惊喜!
——《让子弹飞》
哈喽,大家好,我是一条,一个梦想弃码从文的程序员!
先跟大家补一个元旦快乐!新年新气象,答应大家好久的sql优化内容也该提上日程。
其实网上有很多写的很好的sql优化文章,全面细致,但是都遗漏了一个问题,只教了大家怎么治病,没教怎么看病,这就好比一个饱读医书的大夫,病人往这一坐,望闻问切全都不会,一身的本事不知道该用哪个?
急死个人了。
所以今天就聊聊怎么看病,也就是如何看mysql的执行计划。
本文会以讲带练并附上总结,所以稍微有些长,一次看不完可以点击右上角三个点,然后点击浮窗稍后再看,将公众号设为星标也可以更快速的找到一条。
EXPLAIN
当客户端发送给服务端一条sql语句后,并不是拿过来就执行的,而是先经过优化器选取最优的方案,比如表的读取顺序,索引实际是否被使用,表之间的引用等。
而优化后的执行方案就称之为执行计划。
EXPLAIN的作用就是查看执行计划,使用起来非常简单,无论是select insert update delete,都是只需要在前面加explain。
-- items : 商品主数据表
explain select * from items;
执行后的结果如下(为方便查看,使用树形结构展示):
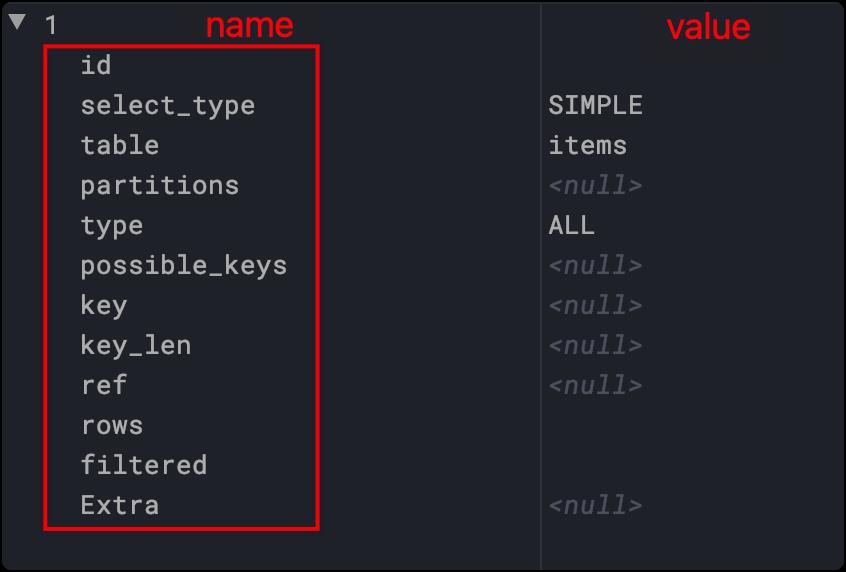
左面就是执行计划的列名,我们的学习的关键就是要知道每列的含义。
右面是对应的值,在实际开发中通过分析值来诊断sql语句的问题。
看懂执行计划
id
select的执行顺序,怎么理解呢?看下面的sql:
explain
select *
from items_img
where item_id =
(select id from items where item_name like '蛋糕');
共有两个查询,哪个先执行呢,可以通过id来判断:
- id 越大,优先级越高,越先执行。
- id相同的情况下执行顺序是由上到下。
验证一下:
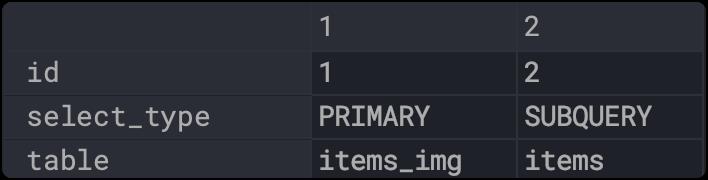
可以看到id=2,对应items表,先执行。
select_type
观察刚才的输出结果,发现子查询的select_type值是不一样的,分别是什么意思呢?
顾名思义,应该是查询类型的意思,我们只要知道了某个小查询的select_type属性,就知道了这个小查询在整个大查询中扮演了一个什么角色。
PRIMARY是指查询中包含子查询,并且该查询位于最外层,而SUBQUERY翻译过来就是子查询。上面的SIMPLE则是最普通,最简单的查询。
还有一些其他的值如下:
DERIVED: 表示在from中包含子查询UNION: 对于包含UNION或者UNION ALL的大查询来说,除了最外层的查询会被标记为PRIMARY,其余都会被标记为UNION。UNION RESULT: 表示UNION查询中的临时表。MATERIALIZED:IN或EXISTS后的查询。
补充说明:
MATERIALIZED翻译过来是物化的意思,即将子查询结果集中的记录保存到临时表的过程。临时表称之为物化表。正因为物化表中的记录都建立了索引(基于内存的物化表有哈希索引,基于磁盘的有B+树索引),通过索引执行
IN语句判断某个操作数在不在子查询结果集中变得非常快,从而提升了子查询语句的性能。
table
这个无需多说,表明这一行的数据是关于哪个表。
partitions
这里先介绍一下分区表的概念,和我们常说的分库分表不同。
分区表是指将数据文件在磁盘上进行分区,将一个大文件分成多个小文件。可以优化查询性能,特别是对于count查询可以并发统计,还可以通过指定分区快速删除废弃数据。
分区类型:
RANGE分区:根据给定一个连续的区间进行分区。在删除旧数据时特别有用。LIST分区:根据具体数值分区。假设某商品销售在华东,华中,华北三个战区,按照战区分区,在where查询时只需要指定分区即可。HASH分区:根据对固定整数取模来分区,这就要求数据分布比较平均。Hash分区也存在与传统Hash分表一样的问题,可扩展性差。MySQL也提供了一个类似于一致性Hash的分区方法-线性Hash分区,只需要在定义分区时添加LINEAR关键字。KEY分区:与Hash分区很相似,只是Hash函数不同。
看一个创建分区表的示例:
-- 创建user表
create table user_partitions (
id int auto_increment,
name varchar(12),
primary key(id)
)
-- 按照id分区,id<100 p0分区,其他p1分区
partition by range(id)(
partition p0 values less than(100),
partition p1 values less than maxvalue
);
回到执行计划,partitions这列表明数据在哪个分区。
type
代表访问类型,即如何查找数据,结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery> range > index>all
可以只记住简化版的:
system > const > eq_ref > ref > range > index>all
生产环境一般需要达到ref或range 级别。依次给大家介绍下:
system:表中只有一行记录(等于系统表),平时基本不会出现。
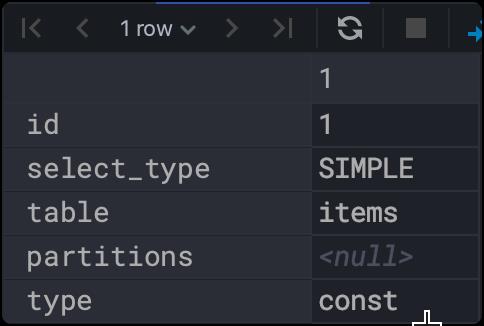
const:通过索引一次就找到了。
示例:
explain
select * from items where id = 'bingan-1001';
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。
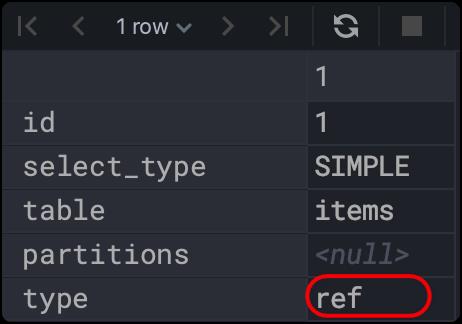
ref:非唯一索引扫描,返回匹配某个单独值的所有行。
首先商品表给销量建一个索引,但不是唯一索引。

sql如下:
explain
select * from items where sell_counts = 3308;
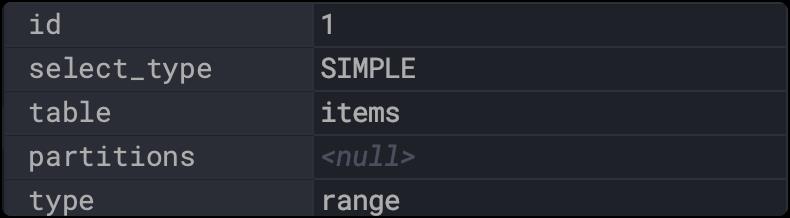
range:只检索给定范围的行。
还是销量这列,sql如下:
explain
select * from items where sell_counts between 3000 and 10000;
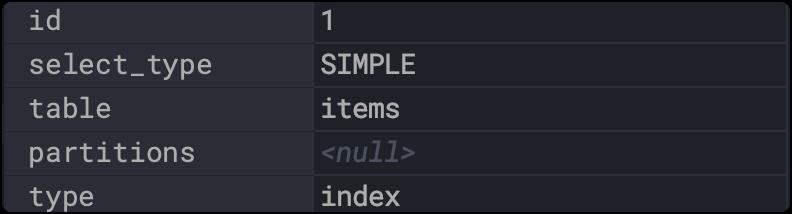
index:当查询的结果全为索引列的时候。
explain
select id,sell_counts from items;
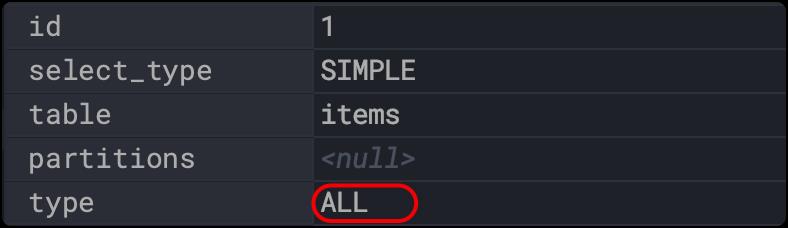
all:全表扫描
explain
select * from items where sell_counts;
null:是不是没想到还会有空的时候,空的意思是我都不需要查表,只需要查索引就能搞定,比如:
explain select min(id) from items;
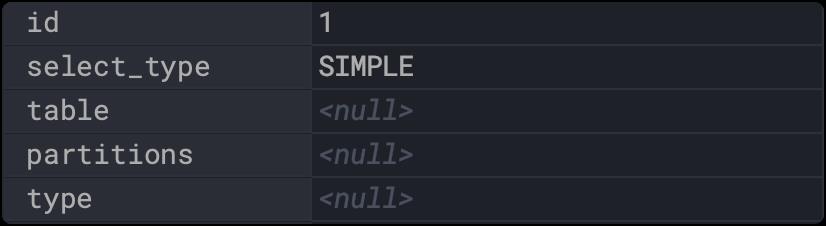
table也是空,说明只查了索引。
possible_keys
翻译一下就是可能用到的key,但不一定真正会用到,有可能是因为MySQL认为有更合适的索引,也可能因为数据量较少,MySQL认为索引对此查询帮助不大,选择了全表查询。
如果想强制使用或不使用某个索引,可以在查询中使用 force index、ignore index。
key
真正用到的索引。
通过对比possible_keys和key,可以观察所建的索引书否被使用,即索引是否合理,从而进行优化。
索引不是建的越多越好,可能使用的索引越多,查询优化器计算查询成本时就得花费更长时间,所以如果可以的话,尽量删除那些用不到的索引。
对于线上已经存在大量数据的表,不要轻易增加索引,因为会增大数据库的压力。
key_len
表示索引使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
看一个案例:
新建一个联合索引

执行如下sql
explain
select * from items where sell_counts=300;
看一下结果
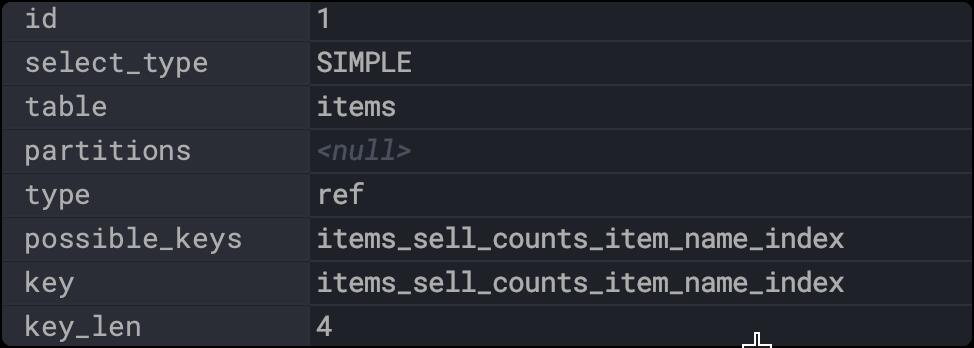
显然是用到了联合索引,但是具体用到那一列呢,发现ken_len是4,正好是一个int类型的长度,也是就只使用了sell_counts这列。
修改一下sql
explain
select * from items where sell_counts=300 and item_name='好吃蛋糕甜点蒸蛋糕';
执行结果

索引不变,ken_len变为134,怎么来的呢?
需要先看一下item_name的长度是32。
还需要知道字符编码是是什么?show variables like 'character%';
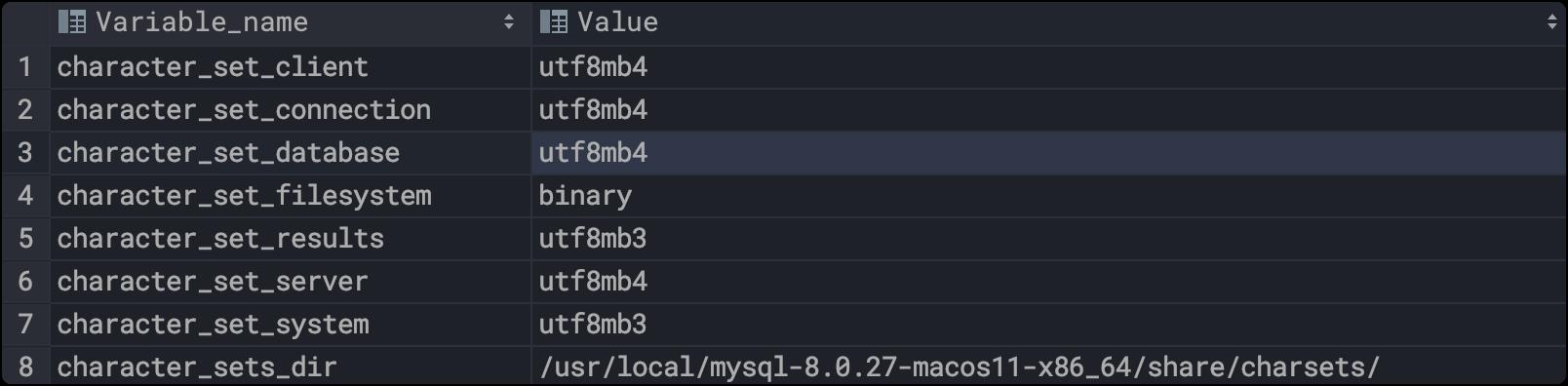
utf8mb4是个啥呢,简单说就是它才是MySQL中真正的utf8,而MySQL中的utf8是一种“专属的编码”,它能够编码的Unicode字符并不多。
这其实MySQL的一个bug,utf8mb4是用来修复的。
言归正传,用字段长度*编码占字节=总的字节数。即32*4=128。(latin1占用一个字节,gbk占用两个字节,utf-8 占用三个字节)。
但是这还每完,因为varchar是可变长度的,还需要两位存储真正的长度。这样加上int的四个字节,刚好134,由此推断出用到了sell_conts和item_name两列(128+2+4=134)。
另外由于字符串是可以存储空值的,所以还需要一个标志位来存储是否为空,但是在本例中,item_name是非空列,所以不再加一。

ref
展示与索引列作等值匹配的值是什么,比如一个常数或者是某个列。
explain
select * from items i where id = 'cake-1001';
这样是一个常数

explain
select * from items i left join category c
on c.id = i.cat_id;
这样是一个列

rows
大致所需要读取的行数。
如果查询优化器决定使用全表扫描的方式对某个表执行查询时,代表预计需要扫描的行数。
如果使用索引来执行查询时,就代表预计扫描的索引记录行数。
explain
select * from items i where sell_counts > 100;

filtered
通过表条件过滤出的行数的百分比估计值。

Extra
顾名思义,Extra列是用来说明一些额外信息的,我们可以通过这些额外信息来更准确的理解MySQL到底将如何执行给定的查询语句,也是很重要的一列。主要有以下值:
Using index:查询的列被索引覆盖,也就是使用了覆盖索引,会很快。Using where:表明使用了 where 过滤。Using where Using index:查询的列被索引覆盖,但是不是索引的前导列(第一列)。NULL:查询的列未被索引覆盖,并且where筛选条件是索引的前导列。即用到了索引,但还不够,需要回表(先拿到id,通过id再查一遍)Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围Using temporary:用到了临时表,比如去重,分组。Using filesort:排序列未创建索引。Using join buffer (Block Nested Loop):关联查询时,当被驱动表没有索引时,MySQL一般会为其分配一块名叫join buffer的内存块来加快查询速度,也就是我们所讲的基于块的嵌套循环算法。
explain
select * from items i left join category c
on c.name = i.item_name;

还会有比如No tables used(没有from子句)等等。
总结
ok,EXPLAIN的所有列就已经聊完了,小结一下:
| 列名 | 含义 |
|---|---|
| id | 执行顺序 |
| select_type | 查询类型 |
| table | 用到的表 |
| partitions | 用到的分区 |
| type | 访问类型 |
| possible_keys | 可能用到的索引 |
| key | 真实用到的索引 |
| key_len | 索引用到的字节数 |
| ref | 与索引列匹配的值 |
| rows | 估计扫描的行数 |
| filtered | 筛选比 |
| Extra | 额外补充信息 |
最后
至此,成为一个江湖郎中已经不是问题,想成为sql优化的名医,还需要看下一节的移花接木之法。敬请期待!
点在看!点在看!还TMD是点在看!
以上是关于翻译翻译什么TMD叫EXPLAIN的主要内容,如果未能解决你的问题,请参考以下文章