应该如何彻底解决UTF8编码转换成GB2312编码问题?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了应该如何彻底解决UTF8编码转换成GB2312编码问题?相关的知识,希望对你有一定的参考价值。
我需要将从人家网站传来的的UTF8编码的字符转换成GB2312,用函数转换确实可行,但这个UTF8转GB2312编码的函数,运行起来感觉非常消耗资源,有时甚至会造成死机。
在不修改服务器设置的前提下,我应该如何解决这个问题呢?有没有抛弃函数的转换办法,或者谁能提供一个更高效的函数?
请有过这方面的高手指点,非常感谢。
UTF8转GB2312的原函数如下(好像网上的都是这个函数):
<%
function UTF2GB(UTFStr)
for Dig=1 to len(UTFStr)
if mid(UTFStr,Dig,1)="%" then
if len(UTFStr) >= Dig+8 then
GBStr=GBStr & ConvChinese(mid(UTFStr,Dig,9))
Dig=Dig+8
else
GBStr=GBStr & mid(UTFStr,Dig,1)
end if
else
GBStr=GBStr & mid(UTFStr,Dig,1)
end if
next
UTF2GB=GBStr
end function
function ConvChinese(x)
A=split(mid(x,2),"%")
i=0
j=0
for i=0 to ubound(A)
A(i)=c16to2(A(i))
next
for i=0 to ubound(A)-1
DigS=instr(A(i),"0")
Unicode=""
for j=1 to DigS-1
if j=1 then
A(i)=right(A(i),len(A(i))-DigS)
Unicode=Unicode & A(i)
else
i=i+1
A(i)=right(A(i),len(A(i))-2)
Unicode=Unicode & A(i)
end if
next
if len(c2to16(Unicode))=4 then
ConvChinese=ConvChinese & chrw(int("&H" & c2to16(Unicode)))
else
ConvChinese=ConvChinese & chr(int("&H" & c2to16(Unicode)))
end if
next
end function
function c2to16(x)
i=1
for i=1 to len(x) step 4
c2to16=c2to16 & hex(c2to10(mid(x,i,4)))
next
end function
function c2to10(x)
c2to10=0
if x="0" then exit function
i=0
for i= 0 to len(x) -1
if mid(x,len(x)-i,1)="1" then c2to10=c2to10+2^(i)
next
end function
function c16to2(x)
i=0
for i=1 to len(trim(x))
tempstr= c10to2(cint(int("&h" & mid(x,i,1))))
do while len(tempstr)<4
tempstr="0" & tempstr
loop
c16to2=c16to2 & tempstr
next
end function
function c10to2(x)
mysign=sgn(x)
x=abs(x)
DigS=1
do
if x<2^DigS then
exit do
else
DigS=DigS+1
end if
loop
tempnum=x
i=0
for i=DigS to 1 step-1
if tempnum>=2^(i-1) then
tempnum=tempnum-2^(i-1)
c10to2=c10to2 & "1"
else
c10to2=c10to2 & "0"
end if
next
if mysign=-1 then c10to2="-" & c10to2
end function
%>
求最高效的编程解决方案,最好能详细说明。
默认字符集由 latin1 变为 utf8mb4。想起以前整理过字符集转换文档,升级到 MySQL 8.0 后大概率会有字符集转换的需求,在此正好分享一下。
当时的需求背景是:
部分系统使用的字符集是 utf8,但 utf8 最多只能存 3 字节长度的字符,不能存放 4 字节的生僻字或者表情符号,因此打算迁移到 utf8mb4。
迁移方案一1. 准备新的数据库实例,修改以下参数:[mysqld]## Character Settingsinit_connect='SET NAMES utf8mb4'#连接建立时执行设置的语句,对super权限用户无效character-set-server = utf8mb4collation-server = utf8mb4_general_ci#设置服务端校验规则,如果字符串需要区分大小写,设置为utf8mb4_binskip-character-set-client-handshake#忽略应用连接自己设置的字符编码,保持与全局设置一致## Innodb Settingsinnodb_file_format = Barracudainnodb_file_format_max = Barracudainnodb_file_per_table = 1innodb_large_prefix = ON#允许索引的最大字节数为3072(不开启则最大为767字节,对于类似varchar(255)字段的索引会有问题,因为255*4大于767)
2. 停止应用,观察,确认不再有数据写入
可通过 show master status 观察 GTID 或者 binlog position,没有变化则没有写入。
3. 导出数据
先导出表结构:mysqldump -u -p --no-data --default-character-set=utf8mb4 --single-transaction --set-gtid-purged=OFF --databases testdb > /backup/testdb.sql
后导出数据:mysqldump -u -p --no-create-info --master-data=2 --flush-logs --routines --events --triggers --default-character-set=utf8mb4 --single-transaction --set-gtid-purged=OFF --database testdb > /backup/testdata.sql
4. 修改建表语句
修改导出的表结构文件,将表、列定义中的 utf8 改为 utf8mb4
5. 导入数据
先导入表结构:mysql -u -p testdb < /backup/testdb.sql
后导入数据:mysql -u -p testdb < /backup/testdata.sql
6. 建用户
查出旧环境的数据库用户,在新数据库中创建
7. 修改新数据库端口,启动应用进行测试
关闭旧数据库,修改新数据库端口重启,启动应用 参考技术A 你要实现转换, 我给你写点我的经验吧.
<%
public String convert(String str)
String result="";
try
result=new String(str.getBytes("UTF-8"),"gb2312");
catch (Exception ex)
System.out.println(ex.getMessage());
return result;
%>
然后在下面就可以String names=this.convert((String) ses.getAttribute("name"));
进行转换了;
我一般都是这样转换的.
你也可以改一下.用Static方法. 搞到另一个类里面,方便调用;本回答被提问者采纳 参考技术B
GB2312的范围比GBK少很多,也就是说所涵盖的中文字符会比GBK格式的少,一旦遇到没办法识别的繁体字或者特殊符号就会乱码。
所以一般来说我会选GBK格式来写页面。至于UTF-8嘛,一般我写java的时候才会用到,这种一般适用于大型系统,或者跨语言系统,跨服务器等情况下使用。也就是说国外的ie浏览器也可以直接浏览到中文,而不需要安装中文语言支持包。
主要是看你的使用范围,还有就是数据库支持那种编码,这个要跟你数据库的编码对应上来,否则一样会存在乱码的情况。
以上就是建议,望采纳!
用记事本打开你的源文件,然后选择另存为.在弹出的对话框中的"编码"选择"UTF-8",保存即可]
如果文件多,可用editplus(一个写程序常用的文本编辑器).一次性打开多个文件,打开时有个选项是"以XXX方式打开"(大概是这样的文字内容),选择UTF8-方式.然后另存为就行了.
快给分. 参考技术D Response.CharSet("GB2312")
使用这种方式直接输出呢?
彻底搞懂编码 GBK 和 UTF8
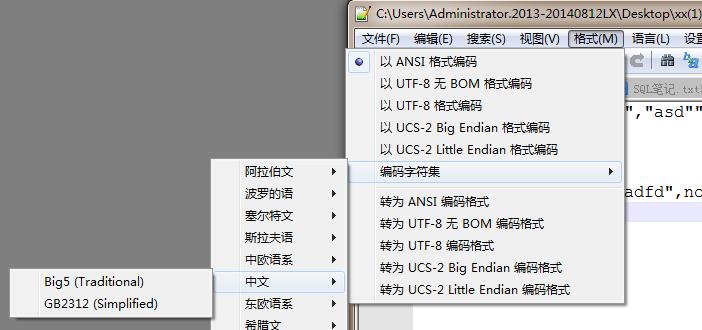
首先来看一下常用的编码有哪些,截图自Notepad++。其中ANSI在中国大陆即为GBK(以前是GB2312),最常用的是 GBK 和 UTF8无BOM 编码格式。后面三个都是有BOM头的文本格式,UCS-2即为人们常说的Unicode编码,又分为大端、小端。
所谓BOM头(Byte Order Mark)就是文本文件中开始的几个并不表示任何字符的字节,用二进制编辑器(如bz.exe)就能看到了。
- UTF8的BOM头为 0xEF 0xBB 0xBF
- Unicode大端模式为 0xFE 0xFF
- Unicode小端模式为 0xFF 0xFE
何为GBK,何为GB2312,与区位码有何渊源?
区位码是早些年(1980)中国制定的一个编码标准,如果有玩过小霸王学习机的话,应该会记得有个叫做“区位”的输入法(没记错的话是按F4选择)。就是打四个数字然后就出来汉字了,什么原理呢。请看下面的区位码表,每一个字符都有对应一个编号。其中前两位为“区”,后两位为“位”,中文汉字的编号区号是从16开始的,位号从1开始。前面的区号有一些符号、数字、字母、注音符号(台)、制表符、日文等等。
而GB2312编码就是基于区位码的,用双字节编码表示中文和中文符号。一般编码方式是:0xA0+区号,0xA0+位号。如下表中的 “安”,区位号是1618(十进制),那么“安”字的GB2312编码就是 0xA0+16 0xA0+18 也就是 0xB0 0xB2 。根据区位码表,GB2312的汉字编码范围是0xB0A1~0xF7FE


可能大家注意到了,区位码里有英文和数字,按道理说是不是也应该是双字节的呢。而一般情况下,我们见到的英文和数字是单字节的,以ASCII编码,也就是说现代的GBK编码是兼容ASCII编码的。比如一个数字2,对应的二进制是0x32,而不是 0xA3 0xB2。那么问题来了,0xA3 0xB2 又对应到什么呢?还是2(笑)。注意看了,这里的2跟2是不是有点不太一样?!确实是不一样的。这里的双字节2是全角的二,ASCII的2是半角的二,一般输入法里的切换全角半角就是这里不同。
如果留意过早些年的手机(功能机),会发现人名中常见的“燊”字是打不出来的。为什么呢?因为早期的区位码表里面并没有这些字,也就是说早期的GB2312也是没有这些字的。到后来的GBK(1995)才补充了大量的汉字进去,当然现在的安卓苹果应该都是GBK字库了。再看看这些补充的汉字的字节码 燊 0x9F 0xF6 。和前面说到的GB2312不同,有的字的编码比 0xA0 0xA0 还小,难道新补充的区位号还能是负的??其实不然,这次的补充只补充了计算机编码表,并没有补充区位码表。也就是说区位码表并没有更新,用区位码打字法还是打不出这些字,而网上的反向区位码表查询也只是按照GBK的编码计算,并不代表字与区位号完全对应。时代的发展,区位码表早已经是进入博物馆的东西了。
Big5是与GB2312同时期的一种台湾地区繁体字的编码格式。后来GBK编码的制定,把Big5用的繁体字也包含进来(但编码不兼容),还增加了一些其它的中文字符。细心的朋友可能还会发现,台湾香港用的繁体字(如KTV里的字幕)跟大陆用的繁体字还有点笔画上的不一样,其实这跟编码无关,是字体的不同,大陆一般用的是宋体楷体黑体,港澳台常用的是明体(鸟哥Linux私房菜用的是新細明體)。GBK总体编码范围为0x8140~0xFEFE,首字节在 0x81~0xFE 之间,尾字节在 0x40~0xFE 之间,剔除 xx7F 一条线。详细编码表可以参考这个列表。微软Windows安排给GBK的code page(代码页)是CP936,所以有时候看到编码格式是CP936,其实就是GBK的意思。2000年和2005年,国家又先后两次发布了GB18030编码标准,兼容GBK,新增四字节的编码,但比较少见。
同一个编码文件里,怎么区分ASCII和中文编码呢?从ASCII表我们知道标准ASCII只有128个字符,0~127即0x00~0x7F(0111 1111)。所以区分的方法就是,高字节的最高位为0则为ASCII,为1则为中文。
UTF8编码 与 Unicode编码
GBK是中国标准,只在中国使用,并没有表示大多数其它国家的编码;而各国又陆续推出各自的编码标准,互不兼容,非常不利于全球化发展。于是后来国际组织发行了一个全球统一编码表,把全球各国文字都统一在一个编码标准里,名为Unicode。很多人都很疑惑,到底UTF8与Unicode两者有什么关系?如果要类比的话,UTF8相当于GB2312,Unicode相当于区位码表,不同的是它们之间的编号范围和转换公式。那什么是原始的Unicode编码呢?如果你用过PHP的话,json_encode函数默认会把中文编码成为Unicode,比如“首发于博客园”就会转码成“\\u9996\\u53d1\\u4e8e\\u535a\\u5ba2\\u56ed”。可以看到每个字都变成了 \\uXXXX 的形式,这个就是文字的对应Unicode编码,\\u表示Unicode的意思,网上也有用U+表示unicode。现行的Unicode编码标准里,绝大多数程序语言只支持双字节。英文字母、标点也收纳在Unicode编码中。有兴趣的可以在站长工具里尝试“中文转Unicode”,可以得到你输入文字的Unicode编码。
因为英文字符也全部使用双字节,存储成本和流量会大大地增加,所以Unicode编码大多数情况并没有被原始地使用,而是被转换编码成UTF8。下表就是其转换公式:

第一种:Unicode从 0x0000 到 0x007F 范围的,是不是有点熟悉?对,其实就是标准ASCII码里面的内容,所以直接去掉前面那个字节 0x00,使用其第二个字节(与ASCII码相同)作为其编码,即为单字节UTF8。
第二种:Unicode从 0x0080 到 0x07FF 范围的,转换成双字节UTF8。
第三种:Unicode从 0x8000 到 0xFFFF 范围的,转换成三字节UTF8,一般中文都是在这个范围里。
第四种:超过双字节的Unicode目前还没有广泛支持,仅见emoji表情在此范围。
例如“博”字的Unicode编码是\\u535a。0x535A在0x0800~0xFFFF之间,所以用3字节模板 1110yyyy 10yyyyxx 10xxxxxx。将535A写成二进制是:0101 0011 0101 1010,高八位分别代替y,低八位分别代替x,得到 11100101 10001101 10011010,也就是 0xE58D9A ,这就是博字的UTF8编码。
前面提到,GBK的编码里英文字符有全角和半角之分,全角为GBK的标准编码过的双字节2,半角为ASCII的单字节2。那现在UTF8是全部用一个公式,理论上只有半角的2的,怎么支持全角的2呢?哈哈,结果是Unicode为中国特色的全角英文字符也单独分配了编码,简单粗暴。比如全角的2的Unicode编码是 \\uFF12,转换到UTF8就是 0xEFBC92。
文章开头有说到 UCS-2,其实UCS-2就是原始的双字节Unicode编码,用二进制编辑器打开UCS-2大端模式的文本文件,从左往右看,看到的就是每个字符的Unicode编码了。至于什么是大端小端,就是字节的存放顺序不同,这一般是嵌入式编程的范畴。
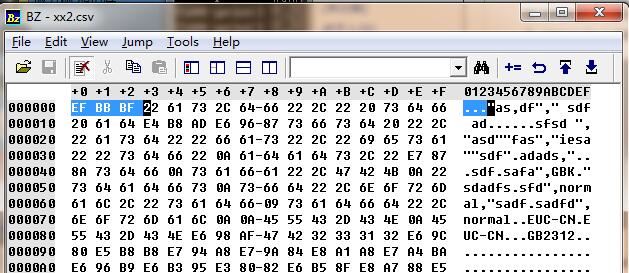
如何区分一个文本是无BOM的UTF8还是GBK
前面说到的几种编码,其中有的是有BOM头的,可以直接根据BOM头区分出其编码。有两个是没有BOM头的,UTF8和GBK,那么两者怎么区分呢?答案是,只能按大量的编码分析来区分。目前识别准确率很高的有:Notepad++等一些常用的IDE,PHP的mb_系列函数,python的chardet库及其它语言衍生版如jchardet,jschardet 等(请自行github)。
那么这些库是怎么区分这些编码的呢?那就是词库,你会看到库的源码里有大量的数组,其实就是对应一个编码里的常见词组编码组合。同样的文件字节流在一个词组库里的匹配程度越高,就越有可能是该编码,判断的准确率就越大。而文件中的中文越少越零散,判断的准确率就越低。
关于ASCII
文中多次提及ASCII编码,其实这应该是每个程序员都非常熟悉、认真了解的东西。对于嵌入式开发的人来说,应该能随时在字符与ASCII码中转换,就像十六进制与二进制之间的转换一样。标准ASCII是128个,范围是0x00~0x7F (0000 0000~0111 0000) ,最高位为0。也有一个扩展ASCII码规则,把最高位也用上了,变成256个,但是这个扩展标准争议很大,没有得到推广,应该以后不会得到推广。因为无论是GBK还是UTF8,如果ASCII字符编码最高位能为1都会造成混乱无法解析。
以GBK为例,如果ASCII的字符最高位也能是1,那么是应该截取一个解析为ASCII呢?还是截取两个解析为中文字符?这根本无法判断。UTF8也是同理,遇到 0xxx 开头则截取一个(即为标准ASCII), 遇到 110x 开头则截取两个,遇到 1110 开头则截取三个,如果ASCII包含1开头的,则无法确定何时截取多少个。
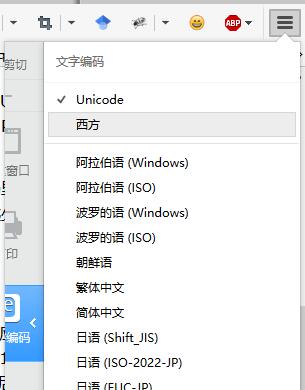
在哪里还能一睹扩展ASCII的真容呢?其实很简单,只要把网页的meta改成ASCII就行了 <meta charset="ASCII" /> 。又或者浏览器的编码选择“西方”,即可见到与平常所见不同的乱码。(截图为火狐)
以上是关于应该如何彻底解决UTF8编码转换成GB2312编码问题?的主要内容,如果未能解决你的问题,请参考以下文章