基于接口(工厂模式)三层架构的 winform 权限控制 初学winform程序,希望高手指点下。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于接口(工厂模式)三层架构的 winform 权限控制 初学winform程序,希望高手指点下。相关的知识,希望对你有一定的参考价值。
要源码学习,请发wyyale7@163.com谢谢了。代码好必有重谢。
目前只要winform的权限控制源码。如题。
自己瞎倒持弄出来了,分谁要?留言。给个asp.net无限级权限控制。嘿嘿
不知道你问的是不是这个权限问题。 参考技术B 我有你说的相关的mvc多层架构项目 但是是web的 不是winform的
需要的话你确认下 适合初学者 项目本身也是一个演示项目 仿百度词条的
web 和winform差别也不是很大啊 编程都是要思想不是要特定的代码 况且都是C#的追问
我用webform和MVC的思路在winform上试了,做不出来。winform很不灵活,程序界面上所有的东西都要用控件来完成。
追答我知道啊 但我那个项目没用多少JS方面的东西 也都是事件触发
追问发几个参考下吧。
追答好了
本回答被提问者采纳 参考技术C MVC你去网上搜索一下吧从接口抽象类到工厂模式再到JVM来总结一些问题
俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!
涉及到的知识点总结如下:
- 为什么使用接口?
- 接口和抽象类的区别
- 简单工厂模式总结
- Java中new和newInstance的区别
- Java的Class.forName(xxx);
- Java里创建对象的几个方式总结
- Java类加载机制总结
- Java WEB的三层架构和MVC的关系
- 工厂方法模式总结
- 抽象工厂模式总结
- 一道面试题的分析
- 一个服务提供者框架的学习
- 接口的另一常用法:策略模式
- 参考资料
先看这样一个场景:某个果园里现在有两种水果,一种是苹果,一种是香蕉,有客户想采摘园子里的水果,要求用get()方法表示即可,代码如下:
苹果类


public class Apple { public void get() { System.out.println("得到苹果"); } }
香蕉类
public class Banana { public void get() { System.out.println("得到香蕉"); } }
客户端
public static void one() { // 实例化一个apple Apple apple = new Apple(); // 实例化一个banana Banana banana = new Banana(); apple.get(); banana.get(); }
苹果和香蕉各自维持一个属于自己的get()方法,直接使用了new运算符进行实例化对象的操作,之后分别调用自己的get()方法,中规中矩的实现过程,很好,我们完成了客户的任务!
这时有了新的需求:我们需要用采摘到的水果做果汁,使用doJuice(对应的水果)方法表示,水果类的代码不变,客户端新加的其他代码如下:
private static void doJuice(Apple apple) { apple.get(); System.out.println("做成果汁"); } private static void doJuice(Banana banana) { banana.get(); System.out.println("做成果汁"); }
客户端
public static void oneA() { // 实例化一个apple Apple apple = new Apple(); // 实例化一个banana Banana banana = new Banana(); doJuice(apple); doJuice(banana); }
好了,貌似任务完成了,现在果园又引进了新品种的水果:橘子,西瓜,柿子,荔枝,葡萄,哈密瓜,火龙果,鸭梨……好了,还是要采摘这些水果然后做果汁!那么如果还是用之前的代码实现,试想一下,除了必须add的新水果类之外,在客户端里还要为每一个水果类型分别添加对应的doJuice(水果)方法,然而水果那么多……apple调用doJuice(apple)方法,orange调用对应的它做果汁的方法……少一个就不行!怎么改进呢?
好了,为了增加程序的灵活性,我们引进接口。修改为:
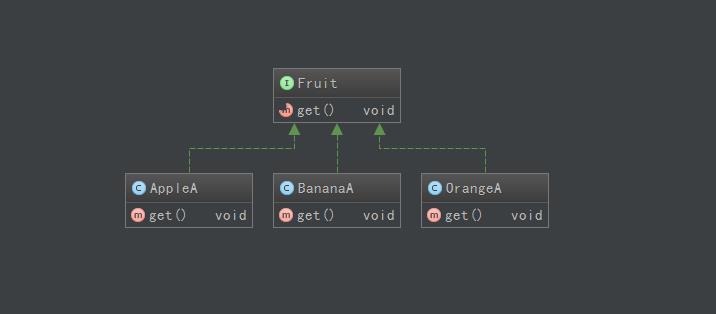
只需要一个方法即可:
private static void doJuiceB(Fruit fruit) { fruit.get(); System.out.println("做成果汁"); }
客户端
private static void two() { // 使用接口的引用指向子类的对象,向上转型过程,用到了多态 Fruit apple = new AppleA(); Fruit banana = new BananaA(); Fruit orange = new OrangeA(); doJuiceB(apple); doJuiceB(banana); doJuiceB(orange); }
事实上,想把各个水果都抽象化!我们可以选择抽象类或者接口去实现!而现在我们要创建不带任何方法定义和成员变量的抽象化的类,首选的应该是接口!
因为接口不仅仅是简单的抽象,它比对类型的抽象更进一步,是一种更纯粹的抽象过程!因为接口没有任何实现,没有任何和接口相关联的存储,因此也就无法阻止多个接口的组合(多继承)。而我们抽象的其实更是对采集水果这个动作的抽象,那么用接口表示最好不过了。客户端里使用了Java的多态机制,我们把任何一个水果类对象当参数传入到doJuice方法里都是可行的,也是正确的!因为每次调用都把对应的水果类向上转型为接口类型——Fruit,基于这个设计,使得Java程序员不用再为类似的场景做出多余的努力!这就是使用接口的核心原因之一!因为这会使得程序变得非常灵活!而且通过继承还能对接口进行扩展!也就是旧的接口去extends新的接口,从而扩展行为是可行的。使用接口的另一个原因是和抽象类类似——避免某个类被实例化,告诉编译器和程序员,这个类不需要实例化,我们只是为了对某些行为做出规范,大家想用就去遵守这个规则好了!
可以说,接口的作用就简单可以概括为两个,一是避免客户端去实例化某个类,二是向上转型的使用;
1、避免客户端去实例化(创建)该类的对象,我就是要告诉编译器,告诉其他程序员,我这个类只是为了做行为的规则用的,是为了规范大家对某个行为的使用,如果有其他类型的类要实现这个行为,好了,请你按照我的规则来!因为事实上,程序里某个行为不一定是一个类去实现,那就是有很多地方有用到,大家需要统一标准,甚至有的编程语言(Object-C)已经不把接口叫 interface,直接叫 protocol,统一标准的目的,是让大家都知道这个是做什么,但是不用知道怎么做,故这个类型不需要客户端去实例化!这一点和抽象类是一致的,更通俗的说接口就是个招牌,比如说看到这个图标:
 然后你就知道这是7-11便利店,这是类似于国内超市的地方,24小时营业的商店(绝大绝大多数),这个图标就是接口,我们远远的看到了这个接口,就知道这个店是711便利店(实现接口),好了这时候有人会问:那么为什么我们要去定义一个接口呢?这个店可以直接卖东西就得了呗(直接写实现方法),是的这个店可以直接卖东西的,不挂711牌子,那样我们就不能乍一看,或者看见店铺门就直接简单粗暴的知道这个店铺是24小时便利商店……要么我们沿着马路边走到每个店铺近前去观察,哪个是24小时营业的?(这就是反射),很显然这样一家家的问实在是非常麻烦(反射性能很差)。要么我们就记住,xxx路xxx号店铺是24小时营业的便利店哎!离着200米的xxxx号也是(硬编码),很显然这样我们要记住的很多东西(代码量剧增),而且如果有新的便利店开张,我们也不可能知道(不利于扩展)……也就是说店铺门前挂了这个招牌,我们不用进去问,甚至不用走到店铺门前,远远看一眼,看到了这个标志,就知道这个店铺是711便利店嘛,24小时营业的哦!
然后你就知道这是7-11便利店,这是类似于国内超市的地方,24小时营业的商店(绝大绝大多数),这个图标就是接口,我们远远的看到了这个接口,就知道这个店是711便利店(实现接口),好了这时候有人会问:那么为什么我们要去定义一个接口呢?这个店可以直接卖东西就得了呗(直接写实现方法),是的这个店可以直接卖东西的,不挂711牌子,那样我们就不能乍一看,或者看见店铺门就直接简单粗暴的知道这个店铺是24小时便利商店……要么我们沿着马路边走到每个店铺近前去观察,哪个是24小时营业的?(这就是反射),很显然这样一家家的问实在是非常麻烦(反射性能很差)。要么我们就记住,xxx路xxx号店铺是24小时营业的便利店哎!离着200米的xxxx号也是(硬编码),很显然这样我们要记住的很多东西(代码量剧增),而且如果有新的便利店开张,我们也不可能知道(不利于扩展)……也就是说店铺门前挂了这个招牌,我们不用进去问,甚至不用走到店铺门前,远远看一眼,看到了这个标志,就知道这个店铺是711便利店嘛,24小时营业的哦!

想要便利的话,就可以直接去……没有挂这个招牌,就算卖的东西和711一模一样,我们不进去问营业员就不会知道它的24小时营业特点!!!再举一个类似的例子,大家都知道吉祥馄饨,

接口也可以比喻为吉祥馄饨的连锁招牌,每个连锁店都有一样的馄饨菜单,一样的馄饨做法说明,一样的总部的馄饨配料……但是每个店铺实现的味道,每个店铺实现过程中的卫生情况……呵呵哒!大家就不知道了吧,只能直观的去看各个店铺的口碑(具体类对接口的不同实现),同样对上一个例子—711便利店来说,人们不需要去具体询问店员你们的店铺是24小时营业的便利店么?还是只是类似国内的小商店……人们只需要,也只能了解到711这个牌子的代表意思就足够了……映射到程序里,就是对具体的类来说,每一个方法是怎么实现的,调用者不知道,其实也不在乎!简单来说对调用者—它只需要知道接口的知识,也最多只能知道接口的知识,因此这是一个很好的抽象过程,和把不同层次的工作内容快速分离的过程!
好了,到这里也许又有了新的疑问!为啥看到一些人写的代码,或者一些项目的源代码里即使只有一个类需要使用接口,也去不厌其烦的定义接口!而且从业务上看,未来也不太可能有其他类用这个接口,那定义这个接口意义在哪里?
三个字:没卵用。
《Thinking in Java》一书说到“确定接口是理想选择,因而应该总是选择接口而不是具体的类,这其实是一个诱惑!因为对于创建类,几乎任何时候,都可以创建接口来代替!许多人都陷入了这个陷阱,在编写代码的时候,只要有那么一丝可能就去肆无忌惮的创建接口……貌似是因为需要使用不同的具体实现,实际上已经是过度优化,已经变成了一种草率的设计!任何抽象都应该以真正的需求出发。必要的时候,应该是重构接口而不是到处添加额外级别的间接性,并因此带来额外的复杂性,恰当的原则应该是:优先想到使用类,从类开始,如果接口的设计需求变得非常明确了,好的,进行重构吧!记住,接口虽然是一个很重要的工具,但是极其容易被滥用!”
哦了!也许还会有疑问!有人说:我觉得抽象类完全可以替代接口,接口能做的抽象类都可以,而且抽象类还能包括实现。这比接口更强大……到这里,先打住这个提问,别忘了—Java不支持多继承!如果只是使用抽象类则必须继承abstract class,而Java只允许单继承,所以仅在这一点上,接口存在就已经十分有意义了,它解决了Java不允许多继承的问题。哦了,也许还会有人问,说:假如有一天Java允许多继承了,那是不是接口就可以淘汰了? 就像C++允许多继承……所以C++里就没有接口……还是说Java的设计者有其他的考虑,即便Java允许多继承,接口依然有它的意义?我想打死这个问问题的人……
先让我们谈谈接口和抽象类的区别吧!接口和抽象类有什么区别?你选择使用接口和抽象类的依据是什么?
接口和抽象类的概念不一样。接口是对动作的抽象,抽象类是对类型的抽象。抽象类表示这个对象是什么。接口表示这个对象能做什么……比如人分男人,女人这两个类,他们的抽象类是人,这种继承关系说明他们都是人,而人都可以吃东西,然而事实上狗也可以吃东西,我们就可以把“吃东西”这个动作定义成一个接口,然后其他需要的类去实现它,从而具备吃的行为。所以,在高级语言上,合理的继承设计就是:一个类只能继承一个类(抽象类)(正如人不可能同时是生物和非生物),但是可以实现多个接口(吃饭接口、走路接口),这点是c++的缺陷。总结来说:
第一点. 接口是抽象类的更高一级的抽象,接口没有任何相关自身的存储,接口中所有的方法默认都是抽象的,默认都是public的,而抽象类只是声明方法的存在而不去实现它的类,需要public方法,则需要程序员指定访问权限。
第二点. 接口可以多继承,抽象类不行。
第三点. 接口定义方法,不能实现,而抽象类可以实现部分方法,也就是抽象类可以同时存在普通方法和抽象方法。
第四点. 接口中基本数据类型为public static, 而抽类象不是的。
一句话区分:当你关注一个事物的本质的时候,用抽象类;当你关注一个操作的时候,用接口。抽象类的功能要远超过接口,但是,定义抽象类的代价高。因为就高级语言来说(从实际设计上来说也是)每个类只能继承一个类。在这个类中,你必须继承或编写出其所有子类的所有共性。虽然接口在功能上会弱化许多,但是它只是针对某动作的描述。而且你可以在一个类中同时实现多个接口。在设计阶段会降低难度。
前面说了那么多,首先谈到接口可以避免其他人去实例化该类,它的出现只是为了给大家统一制定规则的!从而可以很好的隔离工作内容,或者说分离不同业务的分工,这有利于程序的扩展……谈到了这个:接口在开发过程中可以快速分离工作内容,比如上层业务的开发者在写顾客购买商品需要支付这个业务逻辑的时候需要一个功能,就是连接数据库去访问顾客的商城钱包,但是他的工作专注于实现业务逻辑,不想分开精力去做底层实现,那么他只需要先定义一个接口,去定义一个规范,然后就可以继续他的业务逻辑代码了,而底层业务(算法,数据库连接,数据存储等)实现者可以根据这个接口,做他自己具体的实现,上层调用者不需要也不应该去知道底层实现,他只需要了解到接口这一级别即可。这样通过使用接口就可以快速的分离工作内容,达到团队并行工作的目的。此外,如果规范是通过接口定义的,那么当你这个功能有多个实现时,你只要实现了这个接口,那么可以快速的替换具体实现,做到代码层面的完全可以分离。总结起来就一句话:接口或者规范可以在开发过程中做到工作内容的分离。团队的人,A写接口,B写实现,C写实现……B、C就不用写接口,B、C看到A的接口就知道我要具体去实现什么功能,供上层调用者A使用即可。而对于A来说,我不给你们统一规定好了,你们怎么知道该如何去实现哪些具体内容……比如同样是登陆操作,A不统一规定为login(xxx);那么很有可能C写一套登录实现叫loginA,B写一套登录实现叫denglu……具体到程序里,就会让人困惑……且无法快速的替换不同的实现过程。
更进一步,一个任务:A作为上层调用者,它需要一个算法方面的功能,但是A不需要去具体学习相关算法和实现,于是A就去写一个接口,而让B这个底层开发人员写实现,但是B恰恰今天不在公司,A明天要出差,任务后天就交工啦!那A今天必须把使用这个接口的代码写好,A写好接口,明天B把接口实现传个实例进来,任务ok,交工。故interface换个叫法就是contract,有点合同的意思。B实现了这个接口,代表B承诺能做某些事情。A需要一些能做某些事情的东西,于是A要求,必须实现了接口,才能被我调用。实际上也就是个“规范”。
再进一步,想之前的水果的例子:客户想把果园采摘的水果做出果汁,客户作为上层调用者,他只需要水果去做出果汁,而水果具体怎么得到的,他不需要也没必要关心,因为前面刚刚提到的,客户没有必要为了喝果汁还花代价去亲自采摘水果……之前的设计是客户端有一个传入接口类型参数的doJuice(Fruit fruit);方法,客户端调用该方法动态的去做出不同水果的果汁,而不久后,果园升级为果厂了,厂子规定:这个采摘水果的方法是计算据操控的,完全自动化,属于商业机密,有技术壁垒的,不想泄漏出去,下面是代码改进之后:
public class AppleC implements FruitC { @Override public void get() { System.out.println("苹果"); } }
public class BananaC implements FruitC { @Override public void get() { System.out.println("香蕉"); } }
public interface FruitC { void get(); }
现在我们把采集水果的代码单独放到一个类里,我们叫它工厂类
public class FruitFactory { public static FruitC getApple() { return new AppleC(); } public static FruitC getBanana() { return new BananaC(); } }
下面看客户端
private static void three() { FruitC apple = FruitFactory.getApple(); FruitC banana = FruitFactory.getBanana(); doJuice(apple); doJuice(banana); } private static void doJuice(FruitC fruit) { fruit.get(); System.out.println("做成果汁"); }
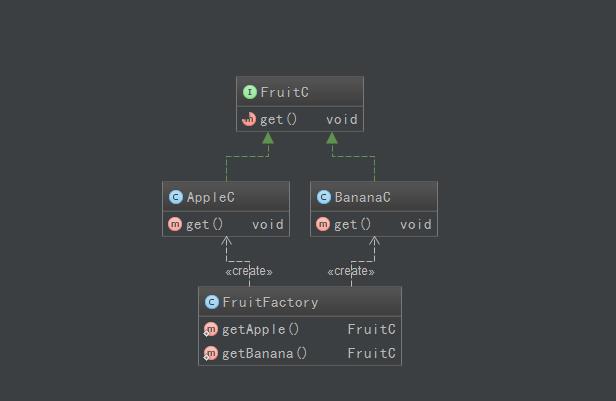
上面的设计,对于客户端来说,不再直接简单粗暴的new一个水果的实例,而是把生成水果的实例的过程放到一个单独的类,把这个实例化的过程隐藏了起来……我们叫它工厂类,这个设计也叫简单工厂模式——它解决的问题是如何去实例化一个合适的对象。简单工厂模式的核心思想就是:有一个专门的类来负责创建实例。具体来说,把产品看着是一系列的类的集合,这些类是由某个抽象类或者接口派生出来的一个对象树,而工厂类用来产生一个合适的对象来满足客户的要求,从而把对象的创建过程进行封装,如果简单工厂模式所涉及到的具体产品之间没有共同的逻辑,那么我们就可以使用接口来扮演抽象产品的角色,如果具体产品之间有逻辑上的联系,我们就把这些共同的东西提取出来,放在一个抽象类中,然后让具体产品继承抽象类,为实现更好复用的目的,共同的东西总是应该抽象出来的。在实际的的使用中,抽象产品和具体产品之间往往是多层次的产品结构,如图:
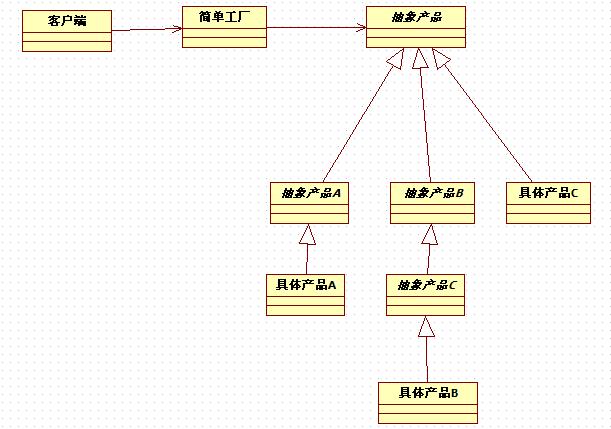
下面看看教科书的定义:简单工厂模式属于类的创建型模式,也叫静态工厂方法模式,通过专门定义一个类来负责创建其他类的实例,目的是为了隐藏具体类的对象的创建过程,既不耽误对象的创建,也隐藏了创建过程!被创建的实例通常都具有共同父类 。本例子里,苹果和香蕉都有一个共同的父类——水果,此时我们专门定义一个类,负责创建其他类的实例,这个类叫简单工厂类,它有三个角色:
1、工厂(Creator)角色 :简单工厂模式的核心,它负责实现创建所有实例的内部逻辑。工厂类可以被外界直接调用,创建所需的产品对象。
2、抽象产品(Product)角色: 简单工厂模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口,或者抽象类。
3.具体产品(Concrete Product)角色: 简单工厂模式所创建的具体实例对象,这些对象去继承或者实现抽象角色。
不过,细细体味下,在工厂类里,我们的设计是针对每一个水果都有一个对应的获取水果的操作,这是一种很粗糙的设计,我们还可以更好,就是把每个get方法抽象为一个公用的get方法!代码如下:同样是有水果接口和具体的水果
public class AppleD implements FruitD { @Override public void get() { System.out.println("苹果"); } }
public class BananaD implements FruitD { @Override public void get() { System.out.println("香蕉"); } }
public interface FruitD { void get(); }
下面是产生水果的简单工厂类
public class FruitFactoryFour { public static FruitD getFruit(String type) { if ("apple".equalsIgnoreCase(type)) { return new AppleD(); } else if ("banana".equalsIgnoreCase(type)) { return new BananaD(); } else { System.out.print("error!"); } return null; } }
这样稍微好了点儿,把每个水果对应的get方法抽象为一个公用的get方法,在这个get但是还不够!工厂类里的if判断来根据传入的参数去判断应该生成哪个水果的对象,并把这个对象返回(依然是向上转型的使用),客户端只需简单的进行调用即可。非常方便,也隐藏了具体产品的实例化过程,完美的完成了客户和水果厂的需求。可以充分的认为,简单工厂模式的核心是工厂类,这个类含有必要的逻辑判断(if-else),可以决定在什么时候创建哪一个类的实例,而调用者则可以免除直接创建对象的责任。简单工厂模式通过这种做法实现了对责任的分割,当系统引入新的产品的时候无需修改调用者!!!无需修改调用者!!!无需修改调用者!!!
举个真实的例子:java.text.DateFormat类

“DateFormat 是Java的日期/时间格式化子类的抽象类,它以与语言无关的方式格式化并解析日期或时间。日期/时间格式化子类(如 SimpleDateFormat)允许进行格式化(也就是日期 -> 文本)、解析(文本-> 日期)和标准化。将日期表示为 Date 对象,或者表示为从 GMT(格林尼治标准时间)1970 年 1 月 1 日 00:00:00 这一刻开始的毫秒数。DateFormat 提供了很多类方法,以获得基于默认或给定语言环境和多种格式化风格的默认日期/时间 Formatter。格式化风格包括 FULL、LONG、MEDIUM 和 SHORT。方法描述中提供了使用这些风格的更多细节和示例。DateFormat 可帮助进行格式化并解析任何语言环境的日期。对于月、星期,甚至日历格式(阴历和阳历),其代码可完全与语言环境的约定无关。且格外说下,日期格式不是同步的,建议为每个线程创建独立的格式实例。如果多个线程同时访问一个格式,则它必须保持外部同步。”不过,还是先关注这个类的简单工厂设计模式的使用,如下源码,只留了静态工厂方法:
public abstract class DateFormat extends Format { public final static DateFormat getTimeInstance() { return get(DEFAULT, 0, 1, Locale.getDefault(Locale.Category.FORMAT)); } public final static DateFormat getTimeInstance(int style) { return get(style, 0, 1, Locale.getDefault(Locale.Category.FORMAT)); } public final static DateFormat getTimeInstance(int style, Locale aLocale) { return get(style, 0, 1, aLocale); } public final static DateFormat getDateInstance() { return get(0, DEFAULT, 2, Locale.getDefault(Locale.Category.FORMAT)); } public final static DateFormat getDateInstance(int style) { return get(0, style, 2, Locale.getDefault(Locale.Category.FORMAT)); } public final static DateFormat getDateInstance(int style, Locale aLocale) { return get(0, style, 2, aLocale); } public final static DateFormat getDateTimeInstance() { return get(DEFAULT, DEFAULT, 3, Locale.getDefault(Locale.Category.FORMAT)); } public final static DateFormat getDateTimeInstance(int dateStyle, int timeStyle) { return get(timeStyle, dateStyle, 3, Locale.getDefault(Locale.Category.FORMAT)); } public final static DateFormat getDateTimeInstance(int dateStyle, int timeStyle, Locale aLocale) { return get(timeStyle, dateStyle, 3, aLocale); } public final static DateFormat getInstance() { return getDateTimeInstance(SHORT, SHORT); } }
随便看一个方法,比如
public final static DateFormat getTimeInstance(int style) { return get(style, 0, 1, Locale.getDefault(Locale.Category.FORMAT)); }
简单工厂模式的影子,方法里面根据恰当的时候传入的参数,返回对应的对象……如果要格式化一个当前语言环境下的日期,可使用某个静态工厂方法:
myString = DateFormat.getDateInstance().format(myDate);
要格式化不同语言环境的日期,可在 getDateInstance() 的调用中指定它。
DateFormat df = DateFormat.getDateInstance(DateFormat.LONG, Locale.FRANCE);
使用 getDateInstance 来获取该国家/地区的标准日期格式。另外还提供了一些其他静态工厂方法。使用 getTimeInstance 可获取该国家/地区的时间格式。使用 getDateTimeInstance 可获取日期和时间格式。可以将不同选项传入这些工厂方法,以控制结果的长度(从 SHORT 到 MEDIUM 到 LONG 再到 FULL)。确切的结果取决于语言环境,但是通常:
- SHORT 完全为数字,如 12.13.52 或 3:30pm
- MEDIUM 较长,如 Jan 12, 1952
- LONG 更长,如 January 12, 1952 或 3:30:32pm
- FULL 是完全指定,如 Tuesday、April 12、1952 AD 或 3:30:42pm PST。
以上……可以去看JDK文档和源代码,不再赘述。
简单工厂模式的优缺点分析:
优点:工厂类是整个模式的关键所在。它包含必要的判断逻辑,能够根据外界给定的信息,决定究竟应该创建哪个具体类的对象。用户在使用时可以直接根据工厂类去创建所需的实例,而无需了解这些对象是如何创建以及如何组织的。有利于整个软件体系结构的优化。
缺点:由于工厂类集中了所有实例的创建逻辑,这就直接导致一旦这个工厂出了问题,所有的客户端都会受到牵连;而且由于简单工厂模式的产品室基于一个共同的抽象类或者接口,这样一来,但产品的种类增加的时候,即有不同的产品接口或者抽象类的时候,工厂类就需要判断何时创建何种种类的产品,这就和创建何种种类产品的产品相互混淆在了一起,违背了单一职责,导致系统丧失灵活性和可维护性。而且更重要的是,简单工厂模式违背了“开放封闭原则”,就是违背了“系统对扩展开放,对修改关闭”的原则,因为当我新增加一个产品的时候必须修改工厂类,相应的工厂类就需要重新编译一遍。
一句话:虽然简单工厂模式分离产品的创建者和消费者,有利于软件系统结构的优化,但是由于一切逻辑都集中在一个工厂类中,导致了没有很高的内聚性,同时也违背了“开放封闭原则”。另外,简单工厂模式的方法一般都是静态的,而静态工厂方法是无法让子类继承的,因此,简单工厂模式无法形成基于基类的继承树结构。
其实说句实话,到了这里,其实又要想了,不要过度的优化,不要为了使用设计模式而使用设计模式!!!如果是业务比较简单的场景,这样的简单工厂模式还是非常好用的!不过无论如何,这样繁琐的if-else判断还是不太好,一旦判断条件稍微多了点儿,那么多的if-else写起来就非常繁琐,即使业务量少也不是最好的!那怎么办呢?别忘了Java的反射机制!我们继续变化:
一样的接口和对应水果的实现类
public interface FruitE { void get(); } public class BananaE implements FruitE { @Override public void get() { System.out.println("香蕉"); } } public class AppleE implements FruitE { @Override public void get() { System.out.println("苹果"); } }
新的工厂类
public class FruitFactoryFive { public static FruitE getFruit(String type) throws ClassNotFoundException, IllegalAccessException, InstantiationException { Class fruit = Class.forName(type); return (FruitE) fruit.newInstance(); } }
通过传入的对应水果的参数,通过Java的反射机制来动态的生成实例。在客户端这样调用:
private static void five() throws IllegalAccessException, InstantiationException, ClassNotFoundException { FruitE apple = FruitFactoryFive.getFruit("simpleFactory.five.AppleE"); FruitE banana = FruitFactoryFive.getFruit("simpleFactory.five.BananaE"); apple.get(); banana.get(); }
必须注意:传入的字符串,必须是对应实现类的全名(带包路径的类全称),否则报错“java.lang.ClassNotFoundException: ”。我们发现工厂类的实现非常简便和灵活了,使用Java的反射机制省去判断的步骤,比之前的繁琐而重复的if-else判断要好点儿了,工厂的扩展性很强!但是依然不完美,客户端缺少调用的灵活性,客户端必须传入严格对应类名的字符串,甚至还要包含完整的包名,才能实例化对应的类……稍微差一点儿都会失败。故还是前面说的,简单的业务,一般使用if-else的方式,不用考虑大小写,传入字符串即可,而稍微复杂点儿的,可以变为反射的方式实现,而反射实现工厂类,对于客户端又显得调用上比较不方便,那么这样岂不是很纠结了……
别急,先看看这样的一个问题:为什么有时候用newInstance方法实例化对象,而不是new关键字呢?两个方式有什么区别呢?
相同点:两种方式都可以创建一个类的实例。
不同点:newInstance是通过反射创建对象的,在创建一个类的对象的时候,你可以对该类一无所知,一些开源框架,比如Spring内部,大都是通过反射来创建实例的,当然这种方法创建对象的时候必须拥有该类的句柄,甚至必要的时候还要有相关的权限设置(比如无参构造函数是私有的),而句柄是可以动态载入的,实际上JVM内部也是这样加载类的。该方法创建对象的时候,只会调用该类的无参构造方法,不会调用其他的有参构造方法,new关键字的后面接类名参数,是最常见的创建实例的方式,但是必须要知道一个明确的类才能使用。用new这个关键字的话,是首先调用new指令创建一个对象,然后调用构造方法来初始化这个对象,比如这样一句代码:
AppleE appleE = new AppleE();
反编译的字节码文件:
// access flags 0x9 public static main([Ljava/lang/String;)V throws java/lang/IllegalAccessException java/lang/ClassNotFoundException java/lang/InstantiationException L0 LINENUMBER 27 L0 NEW simpleFactory/five/AppleE DUP INVOKESPECIAL simpleFactory/five/AppleE.<init> ()V ASTORE 1
看到先调用new指令生成一个对象
NEW simpleFactory/five/AppleE
然后调用dup指令复制对象的引用,最后调用Object的构造方法进行对象的初始化。
INVOKESPECIAL simpleFactory/five/AppleE.<init> ()V
要明确,对于newInstance,newInstance 不是关键字,newInstance 是java反射框架中类对象(Class)创建新对象的方法,方法签名:Object java.lang.Class.newInstance();如:
Class clazz = String.class; Object newInstance = clazz.newInstance();
newInstance() 方法其实经常见于工厂设计模式中,在该模式中,工厂类的该方法返回一个工厂bean。如:
Factory factory = new Factory(); Object obj = factory.newInstance();
严格意义上来讲,new和newInstance这两者没有可比较性,因为一个是Java的关键字,有明确的用法和定义。一个是经常使用,但非标准的方法名称。但是事实上,用newInstance与用new是有区别的,前面说了,区别在于创建对象的方式不一样,前者是使用类加载机制,那么为什么会有这两种创建对象的方式?
这个就要从可伸缩、可扩展,可重用等软件思想上解释了。Java中工厂模式经常使用newInstance来创建对象,因此从为什么要使用工厂模式上也可以找到具体答案。 例如:
Class c = Class.forName(“A”);
factory = (AInterface)c.newInstance();
AInterface是A类实现的接口,详细的拆分一下:
String className = "A"; Class c = Class.forName(className); factory = (AInterface)c.newInstance();
进一步,如果下面这样写:
String className = readXMl();//从xml 配置文件中获得A类的句柄 Class c = Class.forName(className); factory = (AInterface)c.newInstance();
上面代码,利用配置文件就消灭了A类名称,优点:无论A类怎么变化,上述代码不变,甚至可以更换A的兄弟类B , C , D....等,只要他们继承Ainterface就可以。
从jvm的角度看,我们使用new的时候,这个要new的类可以没有被虚拟机加载,但是使用newInstance时候,就必须保证:
1、这个类已经被加载。
2、这个类已经连接了。
而完成上面两个步骤的正是Class的静态方法forName,这个静态方法调用了启动类加载器(就是加载java API的那个加载器)。有上面jvm上的理解,那么我们可以这样说,newInstance实际上是把new这个方式分解为两步,即首先调用class的加载方法加载某个类,然后实例化,这样分步的好处是显而易见的,我们可以在调用Class的静态加载方法forName时获得更好的灵活性,提供给了我们降耦的手段。
既然提到了类的加载机制和Java的反射框架,那么就顺势总结下:
先看一个新问题,Java中创建(实例化)对象的五种方式?
Java中使用new和Class.forName()在类被加载的时候有什么区别?两者是否一样?
前面看到了简单工厂模式作为一个最基本和最简单的设计模式,却有着非常广泛的应用,再看一个例子:JDBC操作数据库。
JDBC是SUN公司提供的一套数据库编程接口API,它利用Java语言提供简单、一致的方式来访问各种关系型数据库。Java程序通过JDBC可以执行SQL语句,对获取的数据进行处理,并将变化了的数据存回数据库,因此JDBC是Java应用程序与各种关系数据进行对话的一种机制。用JDBC进行数据库访问时,要使用数据库厂商提供的驱动程序接口与数据库管理系统进行数据交互。客户端要使用使用数据时,只需要和工厂进行交互即可,这就导致操作步骤得到极大的简化,操作步骤按照顺序依次为:
1、注册并加载数据库驱动,一般使用Class.forName();
2、创建与数据库的链接Connection对象;
3、创建SQL语句对象preparedStatement(sql);
4、提交SQL语句,根据实际情况使用executeQuery()或者executeUpdate();
5、显示相应的结果;
6、关闭数据库;
如图:
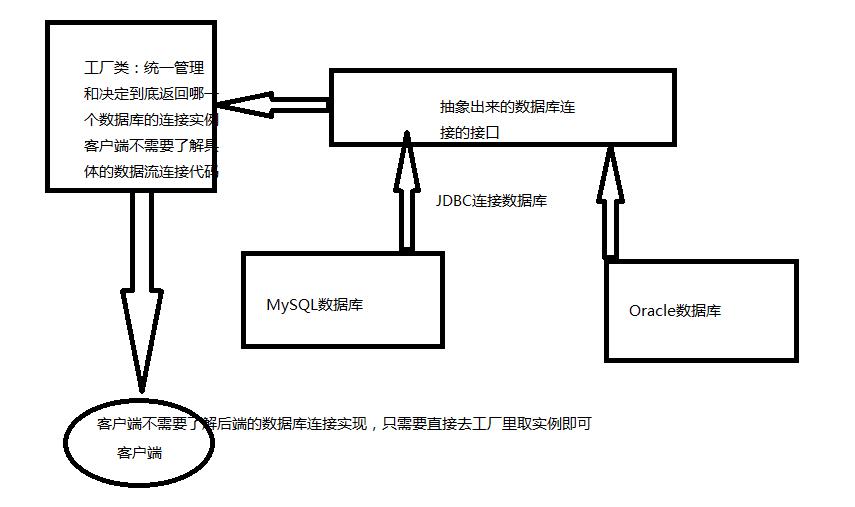
通用的类图如下:
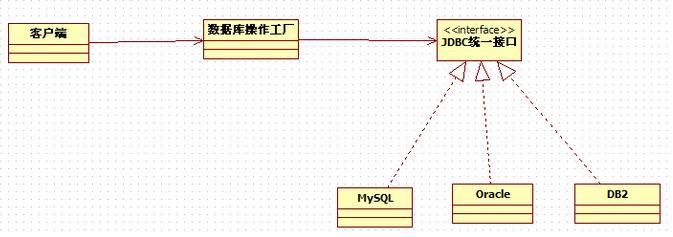
说白了就是在JavaEE 的 dao 层应用了简单工厂模式。
这里插一句,我又想起了以前学习JavaEE的一些疑问:Java web 中dao 层和service层都使用接口,是否是为使用接口而使用接口?
其实我个人认为,一些程序员确实没有搞懂为什么用接口,以至于逢类就要有接口!一些业务不复杂的场景下,真的没有必要这样做呢!但是心里要明白:前面都说了很多例子和理论了,不过学习就是不断重复,归纳的过程,再重复一下,引用网上:使用接口是为了调用与实现解耦,带来的好处是可以各干各的了,带来的坏处是从一个概念变成了两个概念,增加了系统的复杂度。衡量一下在具体场景中是弊大于利还是利大于弊,就可以做选择了。当然,在大部分场景下,还
以上是关于基于接口(工厂模式)三层架构的 winform 权限控制 初学winform程序,希望高手指点下。的主要内容,如果未能解决你的问题,请参考以下文章