Apache Impala(五) Impala数据导入方式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Impala(五) Impala数据导入方式相关的知识,希望对你有一定的参考价值。
参考技术A 首先创建一个表:准备数据 user.txt 并上传到 hdfs 的 /user/impala 路径下去
加载数据
查询加载的数据
如果查询不不到数据,那么需要刷新一遍数据表。
这种方式非常类似于 RDBMS 的数据插入方式。
插入一张表的数据来自于后面的 select 查询语句返回的结果。
建表的字段个数、类型、数据来自于后续的 select 查询语句。
还在MapReduce?真正的并行计算引擎——Apache Impala你需要了解这些
目录
Impala简介
Impala核心概念和架构
Impala部署要求
Impala如何执行查询
Impala接入控制与查询排队
Impala schema设计原则
1
Impala简介
1
介绍
Apache Impala是一个Open Source的MPP(大规模并行处理)SQL查询引擎,它可以基于存储在Apache Hadoop集群上的数据使用SQL语言来进行查询、处理。可以说,它是Google F1的开源版本。Apache Impala项目与2012年10月首次发布,公开其beta测试版本,在2013年5月时,一些企业开始投入到生产环境中使用。
通过Impala可以将可扩展的并行数据库技术引入到Hadoop中,用户可以直接对存储在HDFS、或者是HBase中的数据实现低延迟的交互式SQL查询,无需把数据迁移到其他地方,或者转换为其他类型的数据。Impala可以和Hadoop集成在一起,和MapReduce、Hive、Pig一样,可以使用相同的数据格式、元数据、安全控制以及资源管理器。
Impala和Hive可以很好地兼容在一起,支持Hive的MetaStore、SQL语法(Hive SQL)、ODBC驱动以及提供有友好的用户界面(Hue)。Impala的出现并不是要取代批处理基于MapReduce的框架,例如:Hive。基于MapReduce构建的Hive以及其他框架适合长期运行的批处理作业,例如:涉及到ETL的批处理作业。
2
发展历程
2013年初,Impala开始支持Parquet面向列的存储格式
2013年底,AWS开始支持Impala
2014年初,MapR添加对Impala的支持
2015年,开始支持Kudu。Cloudera将Impala捐献给Apache软件基金会
2017年11月15日,Apache Impala顺利毕业,称为Apache的顶级项目(TLP)。以前是Cloudera Impala,现在称之为Apache Impala。
3
Apache Impala的特点
提供数据科学家、数据分析师熟悉的SQL语法
能够查询Hadoop中的大规模数据
可以在集群环境中进行分布式查询
无需导入导出就可以实现在不同组件之间共享数据,例如:用Pig写数据、用Hive进行ETL、再用Impala进行查询。Impala可以读取、写入Hive的表中,可以使用Impala来基于Hive存储在Hadoop上的数据
一套系统实现大规模数据的分析和处理
支持HDFS和HBase存储
可以读取Hadoop上的多种文件格式,包括文本格式、LZO、Sequence File、Avro、RC File、Parquet等。
支持Hadoop安全认证(Kerberos身份认证)
支持Apachen Sentry的细粒度、基于角色的权限控制
可以基于Hive元数据、ODBC、JDBC、和SQL语法
4
Apache Impala如何和Hadoop集成
Impala解决方案由以下组件组成:
客户端
Hive MetaStore
Impala
HBase和HDFS
客户端
包括了Hue、ODBC、JDBC、以及Impala Shell,都可以和Impala交互。
Hive MetaStore
Hive MetaStore存储了Impala的可用元数据信息。通过MetaStore,Impala可以知道哪些数据库是可用的,数据库、表的结构是什么。当进行create、drop、alter schema对象、或者通过Impala SQL将数据加载到表时,元数据的更改都会通过Impala 1.2引入的catalog service自动广播到所有的Impala节点。
Impala
Impala进程运行在DataNode上,进程可以相互协调并执行查询。每个Impala的进程实例都可以从Impala客户端上接收、计划、协调查询。查询在Impala节点之间分布式地执行,Impala节点相当于是一个worker,并行地执行部分数据的查询。
HBase和HDFS
HBase和HDFS存储了Impala要查询的数据。
Apache Impala查询数据流程
客户端通过ODBC或者JDBC将SQL语句发送给Impala。每一个客户端都可以连接到集群中任意的Impalad。而连接的Impalad将成为本次查询的协调器(Coordinator)。
Impala解析SQL查询,并进行分析,以确定Impalad实例要在整个集群上执行哪些任务,并以最优地效率执行。
每个Impalad实例访问HDFS或者HBase上的数据。
每个Impalad实例将处理后的数据返回给用于协调的Impalad(Coordinator),Coordinator Impalad再将数据结果发送给客户端。
2
Impala核心概念和架构
1
Impala Server组件
Impalad(Impala守护进程)
Impala守护进程(Daemon)是Impala的核心组件,即Impalad进程。
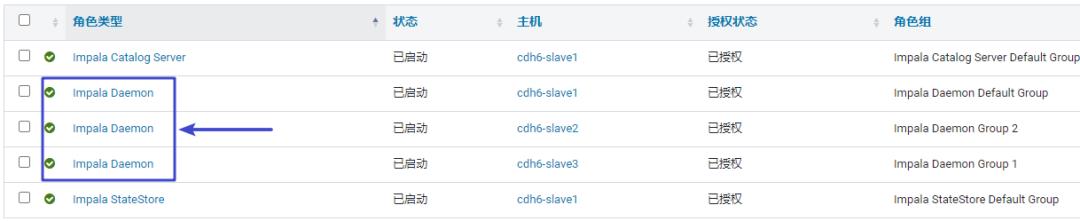
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/impala/sbin-retail/impalad --flagfile=/var/run/cloudera-scm-agent/process/223-impala-IMPALAD/impala-conf/impalad_flagsImpala守护进程的职责为:
读取和写入数据文件
从impala-shell、Hue、JDBC、ODBC接收命令(SQL)
在集群中执行并行查询
将执行查询的中间结果返回给Coordinator
Impala守护进程可以和HDFS部署在一起,也可以将Impala单独部署在计算集群中,从HDFS、S3远程读取数据。
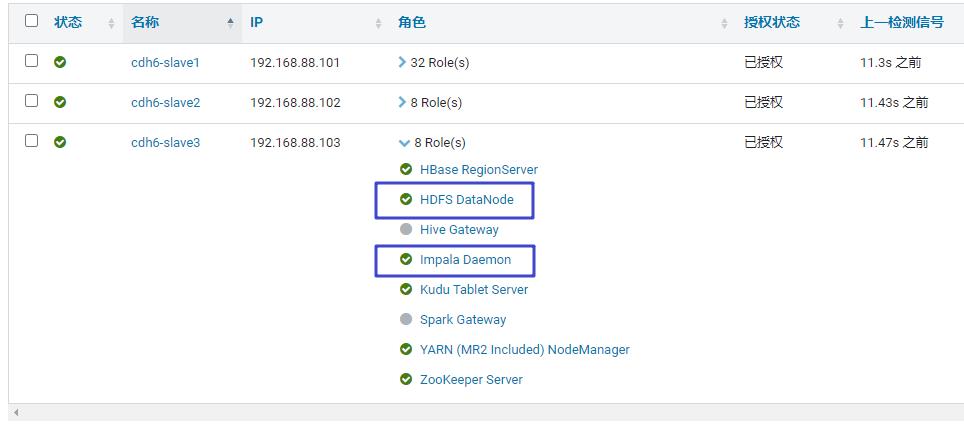
可以看到,小猴的集群是把DataNode和Impalad部署在一起的。
Impald一直会与StateStore保持通信,用于确定哪些Impalad是work的,能够接受查询任务。当集群中的任意一个Impalad创建、修改、删除任何类型的对象时,Impalad会接收到Catalog守护进程的广播消息,以提高元数据的刷新、失效。在1.2之前,在不同的Impalad之间协调元数据是需要使用DDL的。而在2.9以上版本,我们还可以自己来控制哪些节点充当查询协调角色、哪些节点充当执行器,以提高应对高并发负载的扩展性。
Statestored(Impala状态存储)
Statestored WebUI:
我们看到,在Impala节点上,还有一个名为Impala StateStore角色。StateStore会检查集群中所有Impalad的运行状态,并状态信息不断地发送给每一个Impalad。一个Impala集群中,只需要有一个这样的角色即可。如果因为硬件故障、网络错误、软件问题或者其他原因导致某个Impalad脱机,StateStore会通知所有的Impalad,这样将来Impalad就不会将查询分配给脱机的Impalad了。
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/impala/sbin-retail/statestored --flagfile=/var/run/cloudera-scm-agent/process/224-impala-STATESTORE/impala-conf/state_store_flagsStateStore对整个集群的运行不是至关重要的,因为StateStore主要就是出现问题的时候,能够提供有效通知。并且向Coordinator广播元数据。就算StateStore没有运行,Impalad会继续工作、分配查询。但如果StateStore脱机,元数据有可能会出现不一致的情况。如果StateStore脱机,那么DDL语句会执行失败。负载均衡、高可用一般都是针对Impalad,而StateStore和Catalogd没有特别的要求,它们不会导致数据丢失。
如果这两个进程出现故障不可用,可以停掉Impala服务,然后将Imapal StateStore和Catalogd删除,再其他的节点上分配这两个角色,重启Impala就可以了。
Catalogd(Impala Catalog服务)
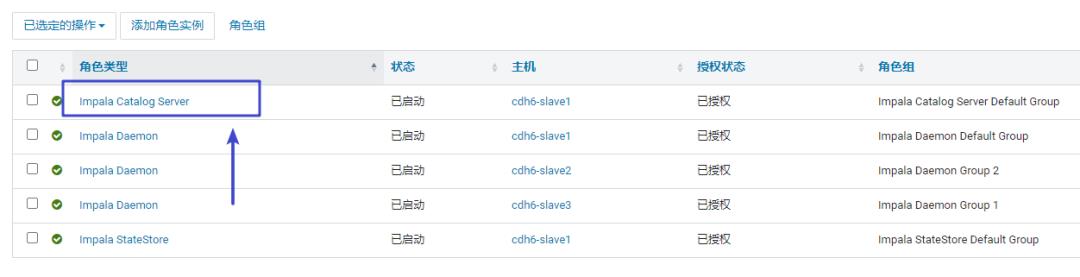
Catalogd的WebUI
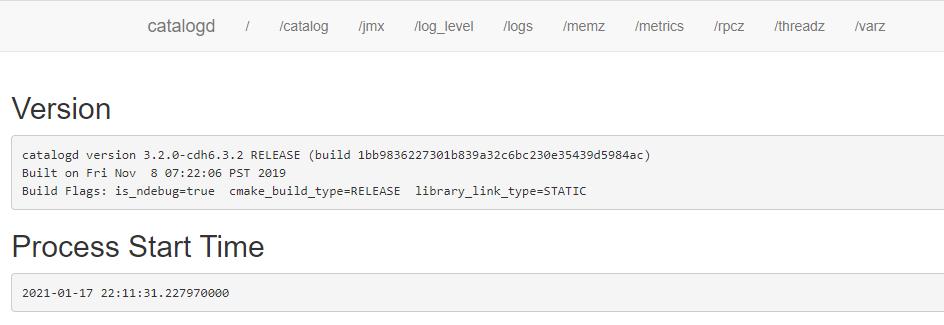
在Impala集群中,还有一个角色叫Impala Catalog Server。
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/impala/sbin-retail/catalogd --flagfile=/var/run/cloudera-scm-agent/process/222-impala-CATALOGSERVER/impala-conf/catalogserver_flagsCatalogd会将所有元数据的更改同步到所有的Impalad。和Statestored一样,一个集群中只需要一个Catalogd就可以了。一般把StateStored和Catalogd部署在一台服务器上,DDL的请求是通过Statestored然后分发的。
当通过Impala执行DDL语句来更改元数据时,Catalogd可以有效避免去执行每个Impalad上的元数据刷新或者失效。如果我们是通过Hive更改了元数据,那么就需要在每个Impalad上去刷新和失效相关元数据,然后再执行查询。所以尽量基于Impala来去更改元数据。
2
开发Impala应用
Impala的核心开发语言是SQL。但支持使用Java或者其他开发语言来和Impala进行交互,例如:一些BI工具可以基于JDBC和ODBC接口来和Impala交互。而一些专业的处理,可以用Java和C++编写UDF来补充Impala SQL的内置函数。
Impala SQL方言
Impala SQL和Hive SQL是高度兼容的,这对于熟悉HiveSQL的同学是非常友好的。
SELECT语句,支持WHERE、GROUP BY、ORDER BY和WITH。聚合、连接、处理字段、数字、日期等内置函数、聚合函数、子查询、比较运算符,都是和标准SQL一样的。
支持Hive分区表,在Impala中也可以指定一列、或者多列作为分区。
Impala 1.2+可以使用UDF在SELECT和INSERT SELECT中执行自定义的比较、转换逻辑
Impala SQL和Hive SQL一样,主要forcus在查询。包含较少的DML,没有UPDATE或者DELETE语句。过时的数据可以被INSERT OVERWRITE或者是把分区DROP掉等。
Impala SQL通过INSERT来创建数据,通过INSERT来从其他表中批量加载数据。支持INSERT INTO和INSERT OVERWRITE。INSERT INTO是追加新的数据到现有数据,而INSERT OVERWRITE相当于是先TRUNCATE、然后再INSERT。
Impala是兼容Hive的,可以通过Hive、HDFS将数据引入进来,然后通过Impala执行实时查询。
Hadoop和Impala专注于对大规模数据集进行数据仓库式的操作。
Impala读取的数据可能不太规则或者可预测,建表的时候无需指定字符串的长度,和Hive一样,可以将字符串列类型定义为String。
Impala编程接口
可以通过以下方式来连接Impala,并向Impalad提交查询:
1、impala shell
[root@cdh6-slave1 ~]# impala-shellStarting Impala Shell without Kerberos authenticationOpened TCP connection to cdh6-slave1:21000Connected to cdh6-slave1:21000Server version: impalad version 3.2.0-cdh6.3.2 RELEASE (build 1bb9836227301b839a32c6bc230e35439d5984ac)***********************************************************************************Welcome to the Impala shell.(Impala Shell v3.2.0-cdh6.3.2 (1bb9836) built on Fri Nov 8 07:22:06 PST 2019)Run the PROFILE command after a query has finished to see a comprehensive summaryof all the performance and diagnostic information that Impala gathered for thatquery. Be warned, it can be very long!***********************************************************************************[cdh6-slave1:21000] default> show databases;Query: show databases+------------------+----------------------------------------------+| name | comment |+------------------+----------------------------------------------+| _impala_builtins | System database for Impala builtin functions || default | Default Hive database |+------------------+----------------------------------------------+Fetched 2 row(s) in 0.20s
2、JDBC/ODBC
3、HUE Web UI
3
Impala如何融合到Hadoop生态
Impala可以和Hadoop生态的很多组件整合使用,可以基于Impala处理数据,也可以用它来生成数据。可以把Impala放在ETL或者ELT中过程中。
和Hive集成
Impala主要目标就是让SQL-on-Hadoop操作更快、更高效,提高用户的体验。Impala可以利用Hive来执行长时间运行、面向批处理的SQL查询。
Impala将表的元数据存储在MySQL或者Postgres中,这个库也就是Hive存放元数据的地方。只要是Impala所支持的数据类型、文件格式、压缩编码器,Impala就可以访问Hive中创建的表。
Impala的元数据和Metastore
Impala的所有元数据保存在一个中央数据库中。例如:MySQL。它还会跟踪HDFS块的位置。对于一些数据量很大、包含很多分区的表,检索表的元数据会比较耗时,有可能需要花费几分钟时间,所以每个Impalad都会缓存所有的元数据,加速查询。如果元数据更新了,Impalad可以接收Statestored的广播,更新元数据。所有的DDL和DML语句,都会自动更新元数据。
Impala与HDFS
Impala使用HDFS作为它的主要存储。并依靠HDFS的冗余来保证数据的容错性。也可以使用HDFS上支持的文件格式和压缩编解码器,Impala表中的数据就是HDFS中的数据文件。
Impala与HBase
HBase是HDFS的替代方案,也可以作为Impala的存储介质。Impala可以基于HBase建立表结构,映射到HBase中的数据,然后通过Impala查询HBase中的数据,还可以将Impala的表和HBase的表联结在一起查询。
4
Impala集群架构
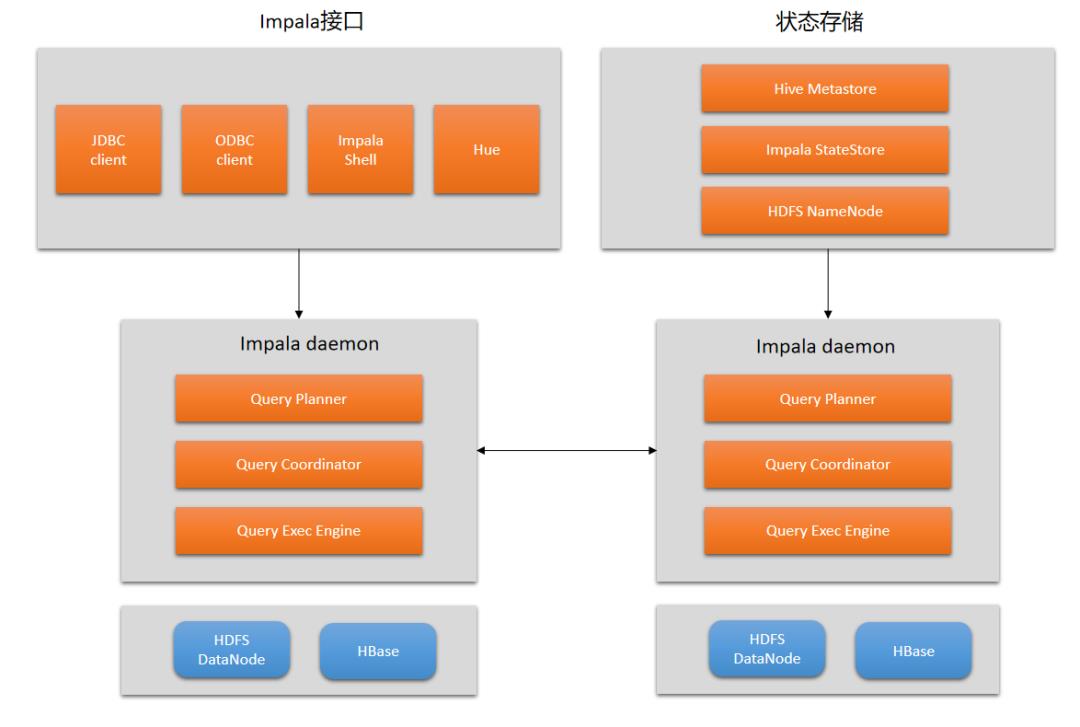
但计算引擎要处理数据时,都避免不了需要读取元数据。例如:MapReduce需要从NameNode中读取要独立的文件中有几个block、block的location在哪儿。Spark还有Flink的driver也一样,需要读取外部存储的元数据。而Impala的StateStore中就存储了外部数据源的元数据。
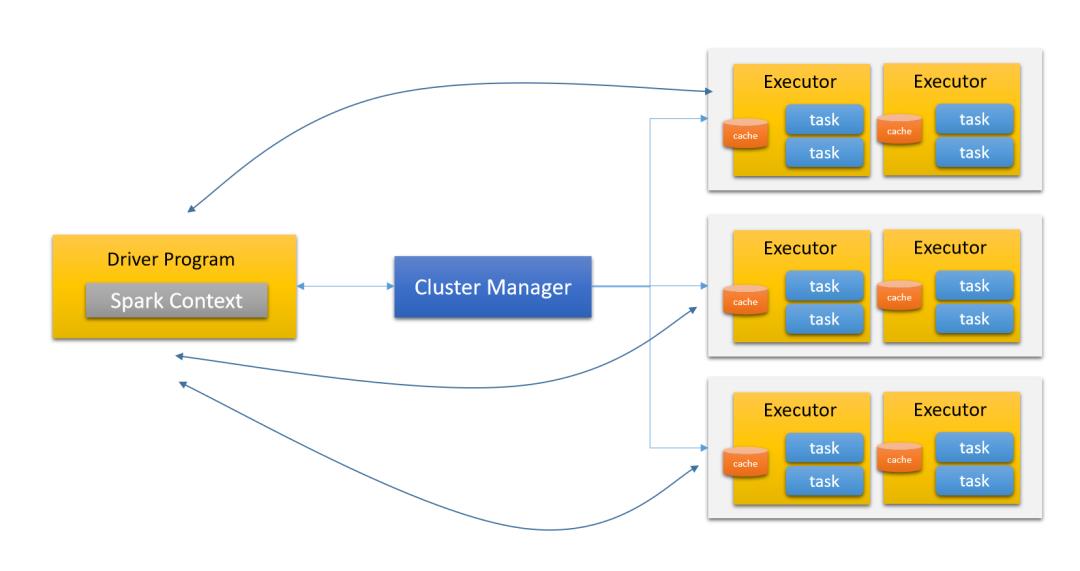
我们也可以看到Impalad和其他的计算引擎不一样的。像MapReduce程序、Spark程序、Flink程序都需要有一个资源管理器组件。看一下MR、Spark、Flink的架构:
MapReduce on YARN架构
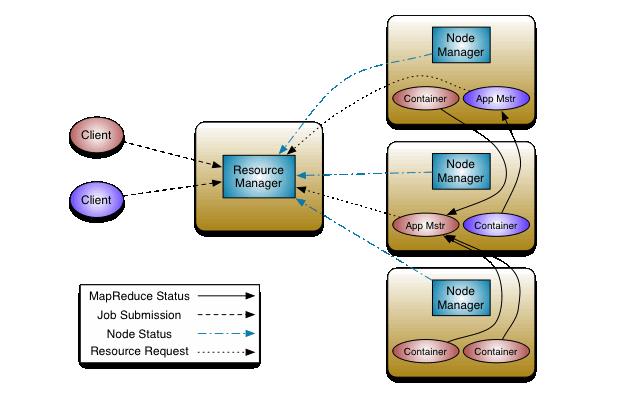
Spark架构
Flink架构
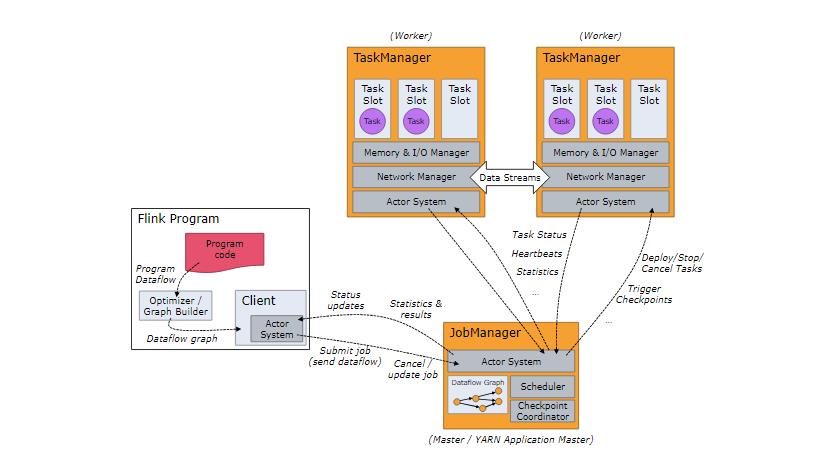
是不是感觉这几种架构非常类似?不管是跑batch作业、跑stream作业,也不管是DSL、还是SQL,都是基于这样的一个模型。因为,他们都是基于MapReduce模型实现的处理引擎。这种处理引擎的作业有个特点,就是适合长时间运行的作业,任务都是一个一个调度的。作业也作业之间的隔离性做得很好。
肯定没有人说,Impala是一个MapReduce引擎,大家更愿意说Impala是一个MPP引擎。Impala的每一个Impalad都有Query Planner、Query Exec Engine,任务是以并行地方式同时执行,最后再合并处理。所以,Impala才是真正意义上的并行计算引擎。
我们知道,YARN有自己的管理器,Resource Manager中就会有一个scheduler,它可以按照指定的策略来进行任务的调度与分配。那问题来了:即使是Impala,客户端肯定会源源不断到、并发地往Impala集群中提交Query,Impala如何分配资源呢?
3
Impala部署要求
1
Hive Metastore和相关配置
Impala可以和Hive中的数据进行交互,并使用和Hive一样的架构来跟踪元数据。例如:表、列。Impala必须要有以下组件:
MySQL或者PostgreSQL,作为Hive和Impala的元数据库。应该始终提供一个Hive的MetaStore,而不是直接连接到MySQL和PostgreSQL操作元数据。
Hive(可选),虽然Impala必须要有Hive的Metastore,但我们可以安装Hive来加载数据文件到某些格式的表中。Hive可以不和Impala安装在一起,Impala只要能够访问到Hive的Metastore即可。
2
Java运行环境
尽管Impala主要是用C++语言编写的,但它要使用Java来和Hadooop的相关组件通信。
Impala支持的是Oracle JVM。其他的JVM可能会存在问题,Impalad无法启动。Impalad是通过JAVA_HOME来查找Java运行环境。
所有Impalad的Java依赖都打包在impala-dependencies中。
3
网络要求
4
硬件要求
为Impala集群的每个节点配置一致的内存,否则,内存比较小的那个节点容易成为瓶颈,从而影响性能。官方推荐的最优Join性能硬件要求:
CPU
使用较新的,支持SSSE3指令集的CPU
内存
建议使用128GB或者更多的内存,最好是256G以上。如果执行查询时,中间结果如果超过了Impala可用的内存,将会将这部分数据写入到磁盘中,这会导致大量的查询时间。因为聚合、汇总结果数据往往比原始数据小得多,所以Impala可以查询、关联的数据量要远大于单个节点的内存的。
Catalog Server的堆内存
建议4GB以上,最好是8GB以上。这样能够存储的表、分区的元数据就更多。
存储
建议使用具有12个或者更多硬盘的DataNode,I/O的速度是Impala性能的直接影响因素。我们也应该确保有足够的存储空间来存储Impala计算后的结果数据。
4
Impala如何执行查询
1
执行流程
client向Impalad的Coordinator发送SQL语句。
Impalad中的Query Plan Java进程解释、分析查询SQL语句,并生成执行计划。不同的操作对应不同的PlanNode(执行计划节点),例如:SelectNode、ScanNode、SortNode、AggregationNode、HashJoinNode等。
Impalad Query Plan继续会将执行计划树分为多个阶段,而每个PlanFragement由多个Impalad并行执行。进行阶段划分后Query Plan将PlanFragments返回给Coordinator。
Impalad Coordinator从元数据库、NameNode,获取与本次查询相关的所有数据。
Coordinator进行任务初始化,将查询任务分配给要查询和存储的所有DataNode。
Query Exec Engine通过流技术交换中间结果数据。
Coordinator汇总每个Impalad上的数据,然后发送给客户端。
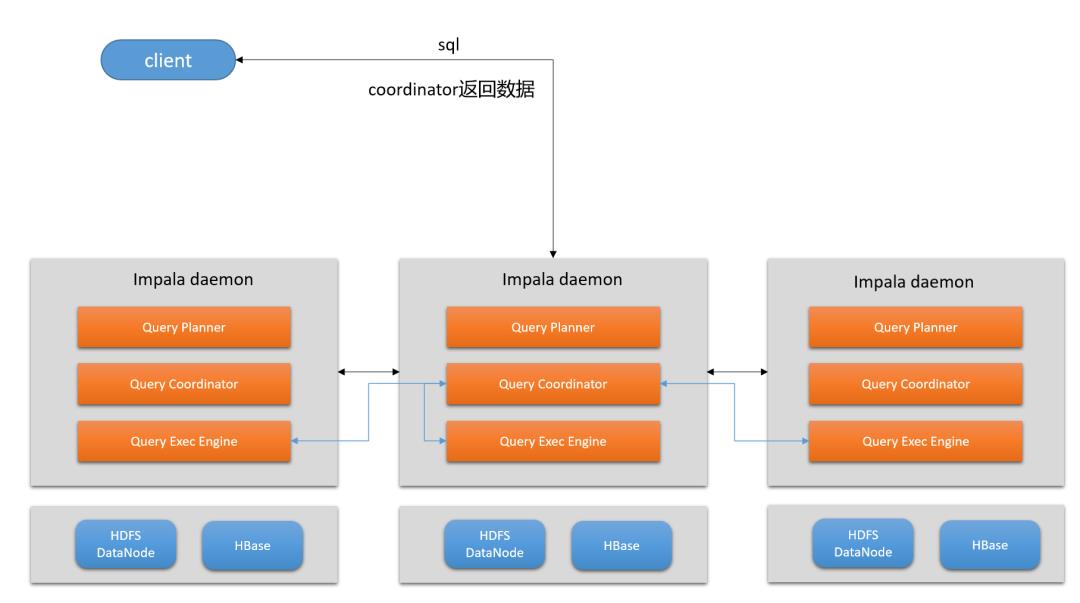
2
Impala执行计划
1、准备数据
先在Hive中创建用于测试的表:
create database if not exists test;/* 创建众筹项目表 */create table if not exists test.ks_project(id string, name string, category string, main_category string, currency string, deadline timestamp, goal decimal(20,2), launched timestamp, pledged decimal(20,2), state string, backers bigint, country string)partitioned by (dt String)comment '众筹项目表'ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES ("SEPARATORCHAR" = ",","QUOTECHAR" = ""","ESCAPECHAR" = """)stored as TEXTFILE;/* 查看数据库中表 */show tables in test;-- [cdh6-slave1:21000] default> show tables in test;-- Query: show tables in test-- +------------+-- | name |-- +------------+-- | ks_project |-- +------------+-- Fetched 1 row(s) in 0.00s创建分区:/* 添加201612分区 */alter table test.ks_project add if not exists partition(dt = '201612');/* 添加201801分区 */alter table test.ks_project add if not exists partition(dt = '201801');/* 查看分区 */show partitions test.ks_project;

上传测试数据到分区位置:
[root@cdh6-slave1 ~]# ll总用量 102088-rw-------. 1 root root 1349 1月 16 23:55 anaconda-ks.cfg-rw-r--r-- 1 root root 46500324 1月 23 13:34 ks-projects-201612.csv-rw-r--r-- 1 root root 58030359 1月 23 13:34 ks-projects-201801.csv# 上传数据到分区文件夹hdfs dfs -put ks-projects-201612.csv hdfs://cdh6-slave1:8020/user/hive/warehouse/test.db/ks_project/dt=201612hdfs dfs -put ks-projects-201801.csv hdfs://cdh6-slave1:8020/user/hive/warehouse/test.db/ks_project/dt=201801# 查看hdfs上的数据[root@cdh6-slave1 ~]# hdfs dfs -ls -R hdfs://cdh6-slave1:8020/user/hive/warehouse/test.db/ks_projectdrwxrwx--x - impala supergroup 0 2021-01-23 13:35 hdfs://cdh6-slave1:8020/user/hive/warehouse/test.db/ks_project/dt=201612-rw-r--r-- 3 root supergroup 46500324 2021-01-23 13:35 hdfs://cdh6-slave1:8020/user/hive/warehouse/test.db/ks_project/dt=201612/ks-projects-201612.csvdrwxrwx--x - impala supergroup 0 2021-01-23 13:35 hdfs://cdh6-slave1:8020/user/hive/warehouse/test.db/ks_project/dt=201801-rw-r--r-- 3 root supergroup 58030359 2021-01-23 13:35 hdfs://cdh6-slave1:8020/user/hive/warehouse/test.db/ks_project/dt=201801/ks-projects-201801.csv
Hive中查询数据:
/* 刷新元数据 */refresh test.ks_project;/* 检查数据的映射情况 */select * from test.ks_project where dt='201612' limit 5;在Impala中构建基于�01分隔符的表,并加载数据:/* 创建众筹项目表 */create table if not exists test.ks_project_delimited_001(id string, name string, category string, main_category string, currency string, deadline timestamp, goal decimal(20,2), launched timestamp, pledged decimal(20,2), state string, backers bigint, country string)partitioned by (dt String)stored as TEXTFILE;insert overwrite table test.ks_project_delimited_001 partition(dt = '201612')selectid, name, category, main_category, currency, deadline, goal, launched, pledged, state, backers, countryfromtest.ks_projectwhere dt = '201612';
编写分析语句:
/* 统计2016年12月众筹的项目总金额 */select sum(goal) from test.ks_project where dt = '201612';[] default> select sum(goal) from test.ks_project where dt = '201612';Query: select sum(goal) from test.ks_project where dt = '201612'Query submitted at: 2021-01-23 13:40:23 (Coordinator: http://cdh6-slave1:25000)Query progress can be monitored at: http://cdh6-slave1:25000/query_plan?query_id=be4589c25907ef42:677b4b0e00000000
2、查看执行计划
根据执行计划中的内容,我们可以判断查询是否能够有效地执行。如果有问题,我们就需要调整查询语句,或者调整表的schema、或者是添加hint来让JOIN更加有效、引入 子查询、或者更改连接表的顺序、添加分区、或者提前收集统计信息等等。
[cdh6-slave1:21000] default> explain select sum(goal) from test.ks_project where dt = '201612';Query: explain select sum(goal) from test.ks_project where dt = '201612'+------------------------------------------------------------------------------------+| Explain String |+------------------------------------------------------------------------------------+| Max Per-Host Resource Reservation: Memory=8.00MB Threads=3 || Per-Host Resource Estimates: Memory=132MB || WARNING: The following tables are missing relevant table and/or column statistics. || test.ks_project || || PLAN-ROOT SINK || | || 03:AGGREGATE [FINALIZE] || | output: sum:merge(goal) || | row-size=16B cardinality=1 || | || 02:EXCHANGE [UNPARTITIONED] || | || 01:AGGREGATE || | output: sum(goal) || | row-size=16B cardinality=1 || | || 00:SCAN HDFS [test.ks_project] || partition predicates: dt = '201612' || partitions=1/2 files=1 size=44.35MB || row-size=16B cardinality=unavailable |+------------------------------------------------------------------------------------+
执行情况:

通过summary我们可以看到每个Operator的耗时时间。可以看到从HDFS上扫描了32W条数据。此处耗时最长的就是读取HDFS文件了。通过Profile我们可以查看非常详细的执行信息。
Query Compilation: 5.894ms- Metadata of all 1 tables cached: 630.068us (630.068us)- Analysis finished: 1.729ms (1.099ms)- Value transfer graph computed: 1.832ms (102.561us)- Single node plan created: 3.099ms (1.266ms)- Runtime filters computed: 3.544ms (445.347us)- Distributed plan created: 3.598ms (53.993us)- Lineage info computed: 3.714ms (116.034us)- Planning finished: 5.894ms (2.180ms)Query Timeline: 317.378ms- Query submitted: 33.001us (33.001us)- Planning finished: 6.995ms (6.962ms)- Submit for admission: 7.726ms (730.150us)- Completed admission: 7.895ms (168.975us)- Ready to start on 2 backends: 8.021ms (126.867us)- All 2 execution backends (2 fragment instances) started: 11.089ms (3.067ms)- Rows available: 306.085ms (294.996ms)- First row fetched: 312.351ms (6.266ms)- Last row fetched: 313.671ms (1.319ms)- Released admission control resources: 314.311ms (640.540us)- Unregister query: 315.922ms (1.610ms)- AdmissionControlTimeSinceLastUpdate: 85.000ms- ComputeScanRangeAssignmentTimer: 14.645usFrontend:ImpalaServer:- ClientFetchWaitTimer: 7.629ms- RowMaterializationTimer: 2.206msExecution Profile c34d5def1c253b70:d42a1c9400000000:(Total: 300.115ms, non-child: 0.000ns, % non-child: 0.00%)Number of filters: 0Filter routing table:ID Src. Node Tgt. Node(s) Target type Partition filter Pending (Expected) First arrived Completed Enabled-------------------------------------------------------------------------------------------------------------------Backend startup latencies: Count: 2, min / max: 2ms / 2ms, 25th %-ile: 2ms, 50th %-ile: 2ms, 75th %-ile: 2ms, 90th %-ile: 2ms, 95th %-ile: 2ms, 99.9th %-ile: 2ms
通过提前查看执行计划,以判断查询是否会以低效的方式执行。
查看执行计划应该从下往上查看:
最后一部分,显示的是比较low-level的详细信息,例如:将要读取的数据量。我们根据这些数据来判断分区策略是否有效。
在往上,我们可以看到合并结果集,并将数据从一个节点传输到另一个节点如何流动。
explain输出的信息量由EXPLAIN_LEVEL决定。例如:
SET EXPLAIN_LEVEL=level(MINIMAL, STANDARD, EXTENDED, or VERBOSE)# 设置详细级别SET EXPLAIN_LEVEL=VERBOSE
如果设置了EXTENDED级别,执行计划会列出来需要的内存、最小的CPU数量。
3、执行计划解析
一个Query一般是从一定数量的数据扫描开始
每个节点都会对节点本地的聚合操作,例如:COUNT(*)
中间的计算结果发送回协调器节点(这个过程称为Exchange)
最后将中间结果合并在一起,并返回至客户端
我们可以通过执行计划看到整个数据流动的pipeline。不同的EXPLAIN_LEVEL展示着不同的级别的数据。在Impala中有4种级别的level。
0或者MINIMAL
1或者STANDARD(默认方式)
2或者EXTENDED
3或者VERBOSE
1、MINIMAL(逻辑执行计划)
最小输出,每种操作显示一行。
+-------------------------------------------------------------+| Explain String |+-------------------------------------------------------------+| Max Per-Host Resource Reservation: Memory=11.94MB Threads=4 || Per-Host Resource Estimates: Memory=132MB || || PLAN-ROOT SINK || 04:EXCHANGE [UNPARTITIONED] || 03:AGGREGATE [FINALIZE] || 02:EXCHANGE [HASH(dt,state)] || 01:AGGREGATE [STREAMING] || 00:SCAN HDFS [test.ks_project_delimited_001] |+-------------------------------------------------------------+
整个执行阶段一目了然,先扫描HDFS、然后本地聚合计算,再按照dt、state进行数据交换,再进行追踪聚合,最后进行数据交换传输给Coordinator。
2、STANDARD
默认的显示级别。包括了分布式查询是如何拆分的。
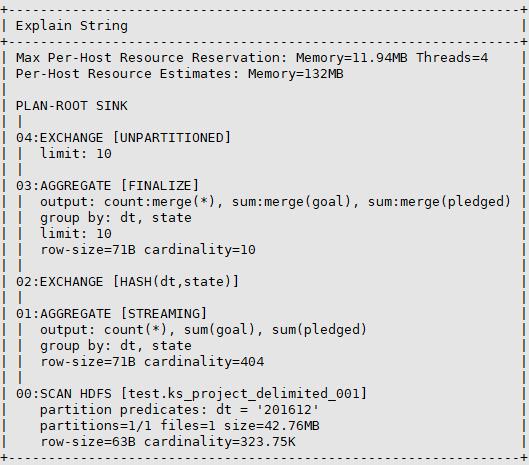
3、EXTENDED
包含了查询计划如何使用统计信息、使用HINT、添加或者删除谓词来调整查询等详细信息。Impala 3.2或者更高的版本,输出中还包括分析后的查询。在输出的标头中会带有强制转换信息。
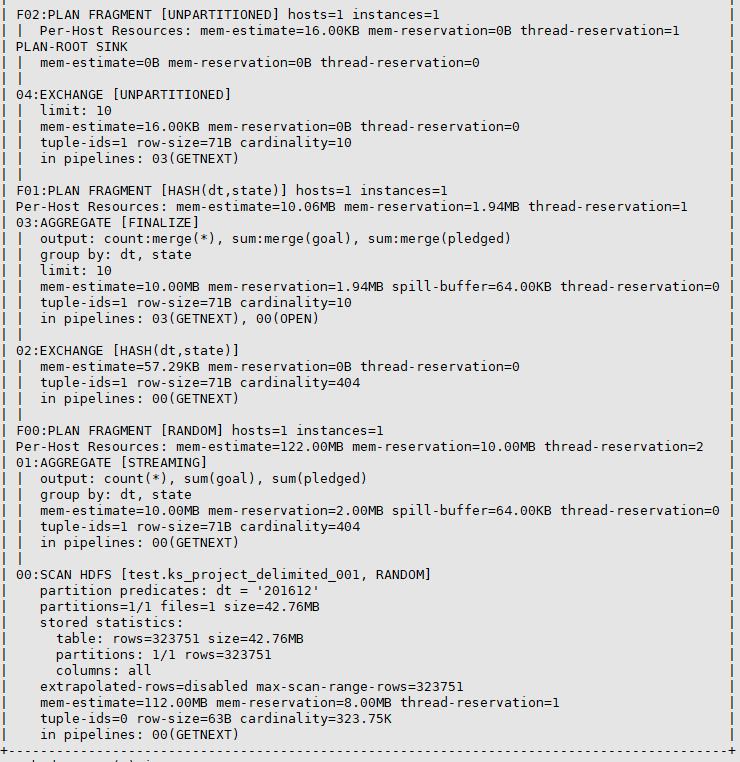
我们看到显示了比较详细的执行计划信息。
4、VERBOSE(物理执行计划)
最高详细程度。显示了如何在每个节点中将参训分解为查询片段。一般VERBOSE级别的执行计划,主要用于Impala本身中low level的性能测试和优化,而不是在用户级别优化SQL代码。
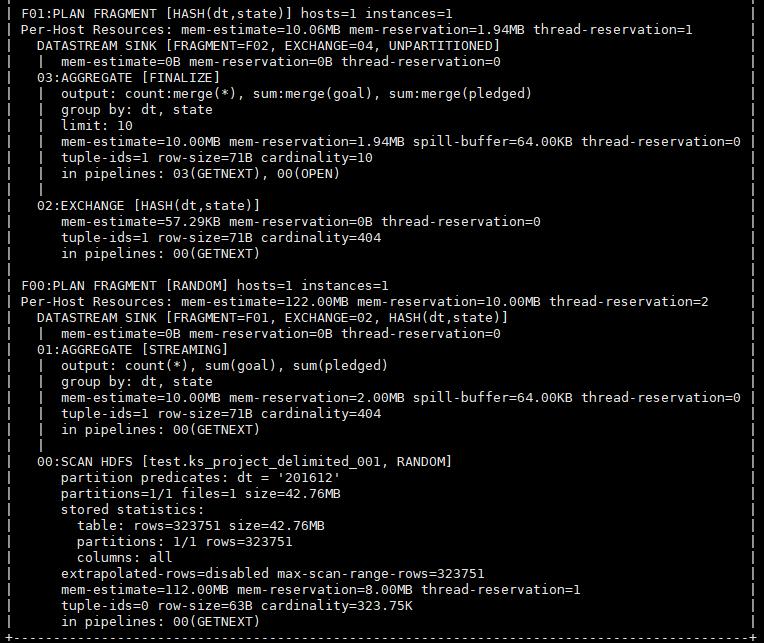
我们可以看到VERBOSE中显示了任务会如何在集群中调度。
5
Impala接入控制与查询排队
打开CM中的Impala组件,就可以看到有Admission Controll的配置。而且放在类别的第一位,可见它的重要性。
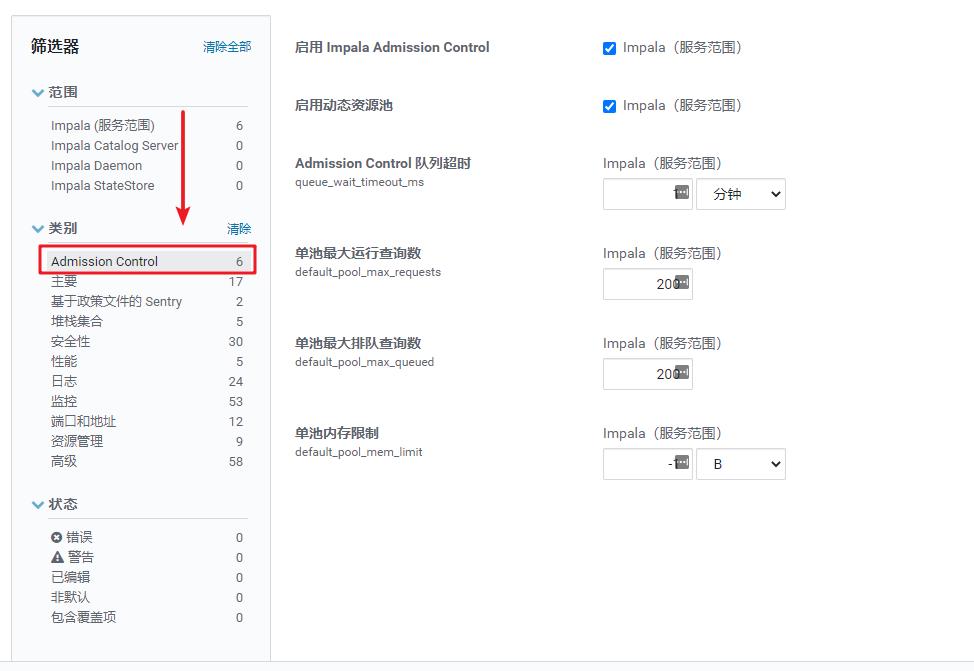
这里,默认Impala接入控制是开启的。我们把Admission Controll称之为接入控制。因为如果客户端不断地往Impala中提交Query,假设有300个用户,那么如果不加以管理,Impala集群可能危在旦夕。可以看到,通过接入控制,能够设定内存的大小限制、查询数量限制、排队数量限制等。
通过接入控制,就好比我们去高铁站做安检,流量大的时候,会一批一批的过安检。其实是一回事。人多了,就排队嘛,不能因为人多就把人全赶走啊~
接入控制也一样,超出配置的查询数就需要等待了。在CDH5.7/Impala 2.5以上版本中,我们可以针对一个池来配置接入控制。通过接入控制可以提升整个Impala集群的吞吐量。因为,如果一个IO密集型的查询就把所有的资源占用完,此时,其他用户再往Impala中提交作业,因为没有足够地资源,执行效率很大打折扣。
1
并发控制
1、控制并发查询数量
接入控制的一种最直接的方法就是设置Impala并发执行查询的上限。如果我们上限了一个Impala集群,但不知道探索性任务、交互式查询的提交情况,这种方法是比较有效的。
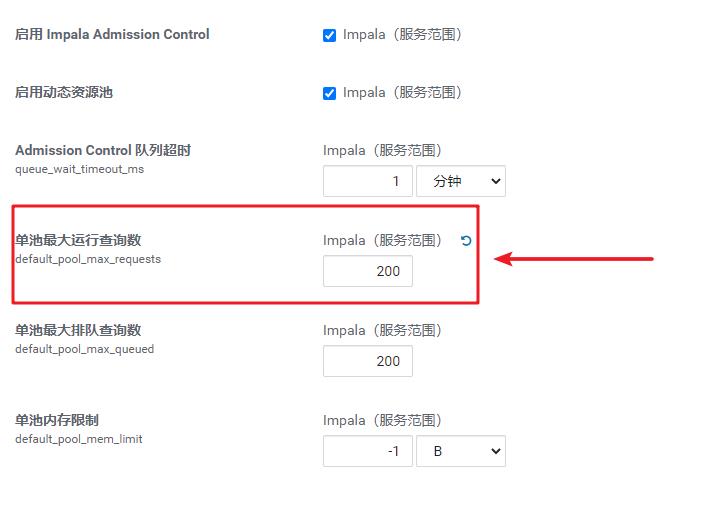
这个配置客户端使用的资源是动态配置的。上面配置的单池最大运行查询数指的最大并发不超过200。如果超出200,就会将查询放入到队列中,知道有其他查询结束。
这种配置适用于刚上线的Impala集群。如果发现集群中运行了大量比较小的查询,则应该把最大并发调整得大一点,或者设置为-1,不做限制。
2、最大排队查询类
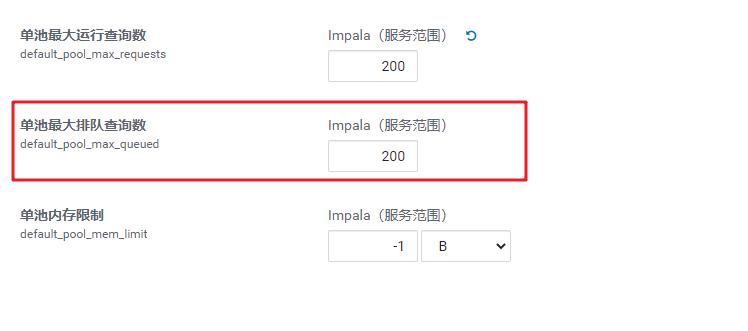
我们看到,默认依然是200。
3、排队超时
如果一个用户在队列中等待的时间过长,Impala会自动取消该查询。12306抢票,是不是也会有超时时间?不会让你等3-5个小时,是吧?
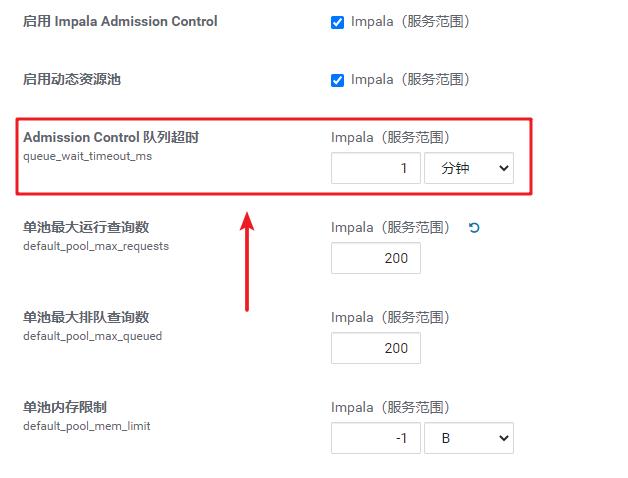
我们看到此处的默认配置是1分钟。
2
内存控制
每个动态资源池都可以对资源池中能够在集群中使用的内存进行控制。
1、最大内存
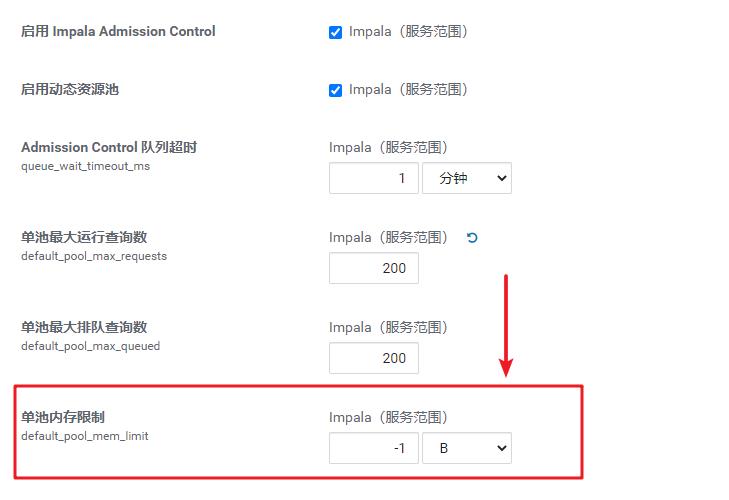
我们看到,当前的池中是没有任何内存控制的。也就是,池中能够榨干Impala集群的整个内存。注意哦,这个配置是针对的整个Impala集群,而不是单个Impalad。
2、在客户端查询中设置内存限制
用户在提交查询之前,可以通过设置MEM_LIMIT来覆盖Impala集群中的配置。
set mem_limit=20g;
3
Impala是如何调度和控制查询并发的
接入控制是运行在每个Impalad中的,它通过StateStore来进行通信。我们配置的最大并行查询、和内存资源虽然是针对整个集群的,但每个Impalad都会自己来决定查询是立即执行,还是排队。这个过程是非常快的,接入控制是轻量级的,但可能会存在不精确的情况。有时候,排队的查询或执行查询的数量会超过指定的阈值。所以,可以把排队的查询数量配置得高一点、内存资源可以配置低一点,这样更多查询也不至于耗尽内存然后被取消掉。
为了避免积压过多排队的查询请求,可以设置队列的大小阈值。如果排队的数量超过该限制,就取消一些查询,而不是一直在排队。还可以设置超时时间,避免让用户无限期地等待。为了能够快速完成查询,对于一些大型表,尤其是join的大表,加载了很多数据或者添加新的分区之后,应该使用COMPUTE STATS或者COMPUTE INCREMENTAL STATS来更新统计信息。
6
Impala schema设计原则
1
首选二进制文件存储数据
二进制文件更节省空间,可以提高内存的使用率和查询性能。大型的、密集型数据查询都应该使用二进制文件。对于数仓的查询分析,Parquet格式是最有效的。对于RC和Sequence File面向行的文件格式,Impala是不支持INSERT操作的。如果考虑到和Hadoop ETL系统集成,Avro是比较合适的。为了方便导入原始数据,建议使用文本格式而不是RC或者Sequence File,然后再将文本格式转换为Parquet。
我们做一个试验,看看用parquet存储与文本存储的对比。
/* 创建parquet格式表 */create table if not exists test.ks_project_parquet(id string, name string, category string, main_category string, currency string, deadline timestamp, goal decimal(20,2), launched timestamp, pledged decimal(20,2), state string, backers bigint, country string)partitioned by (dt String)comment '众筹项目表'stored as parquet;show create table test.ks_project_parquet;-- CREATE TABLE test.ks_project_parquet ( id STRING, name STRING, category STRING, main_category STRING, currency STRING, deadline TIMESTAMP, goal DECIMAL(20,2), launched TIMESTAMP, pledged DECIMAL(20,2), state STRING, backers BIGINT, country STRING ) PARTITIONED BY ( dt STRING ) STORED AS PARQUET LOCATION 'hdfs://cdh6-slave1:8020/user/hive/warehouse/test.db/ks_project_parquet'
导入分区数据:
insert overwrite table test.ks_project_parquet partition(dt='201612')selectid, name, category, main_category, currency, deadline, goal, launched, pledged, state, backers, countryfrom test.ks_project where dt= '201612';
对比大小:
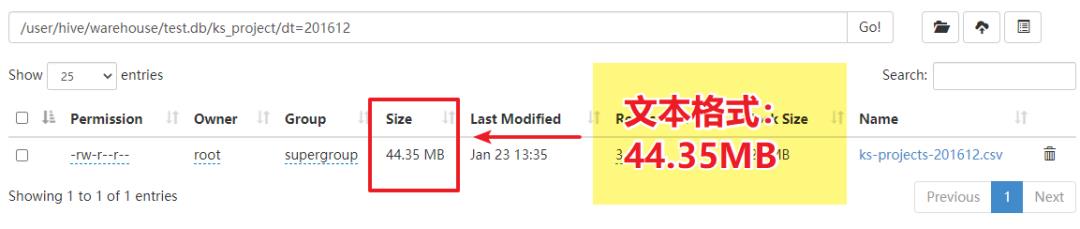
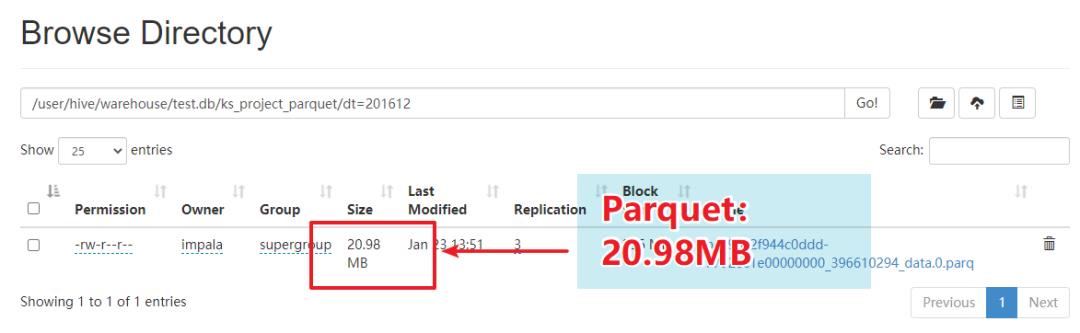
查询效率对比:
select sum(goal) from test.ks_project where dt = '201612'文本方式:

Parquet方式:

我们发现基于Parquet的方式,扫描HDFS的时间为txt方式的6倍。
2
启用Snappy压缩
Snappy压缩只需较低的CPU开销就可以解压缩,可以节省大量的空间。优先使用Snappy。
/* 创建parquet snappy格式表 */drop table if exists test.ks_project_parquet_snappy;create table if not exists test.ks_project_parquet_snappy(id string, name string, category string, main_category string, currency string, deadline timestamp, goal decimal(20,2), launched timestamp, pledged decimal(20,2), state string, backers bigint, country string)partitioned by (dt String)comment '众筹项目表'stored as parquetTBLPROPERTIES ("parquet.compress"="SNAPPY");/* 设置snappy压缩编码 */set COMPRESSION_CODEC=snappy;/* 加载数据 */insert overwrite table test.ks_project_parquet_snappy partition(dt='201612')selectid, name, category, main_category, currency, deadline, goal, launched, pledged, state, backers, countryfrom test.ks_project_parquet where dt= '201612';
导入数据对比:
文本方式:

Snappy压缩方式:
查看下数据大小,发现和parquet方式一样。因为默认创建的parquet表就是有snppy压缩。
[root@cdh6-slave1 ~]# parquet-tools meta 854ee6a9c50db827-af8494fb00000000_1376222048_data.0.parqfile: file:/root/854ee6a9c50db827-af8494fb00000000_1376222048_data.0.parqcreator: impala version 3.2.0-cdh6.3.2 (build 1bb9836227301b839a32c6bc230e35439d5984ac)file schema: schema-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------id: OPTIONAL BINARY R:0 D:1name: OPTIONAL BINARY R:0 D:1category: OPTIONAL BINARY R:0 D:1main_category: OPTIONAL BINARY R:0 D:1currency: OPTIONAL BINARY R:0 D:1deadline: OPTIONAL INT96 R:0 D:1goal: OPTIONAL FIXED_LEN_BYTE_ARRAY L:DECIMAL(20,2) R:0 D:1launched: OPTIONAL INT96 R:0 D:1pledged: OPTIONAL FIXED_LEN_BYTE_ARRAY L:DECIMAL(20,2) R:0 D:1state: OPTIONAL BINARY R:0 D:1backers: OPTIONAL INT64 L:INTEGER(64,true) R:0 D:1country: OPTIONAL BINARY R:0 D:1row group 1: RC:323751 TS:21993789 OFFSET:4-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------id: BINARY SNAPPY DO:4 FPO:274943 SZ:2297284/4447656/1.94 VC:323751 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 0x31303030303032333330, max: 0x494420, num_nulls: 0]name: BINARY SNAPPY DO:2297374 FPO:3465117 SZ:9395190/12166890/1.30 VC:323751 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 0x2020202049549253204120484F542043415050554343494E4F204E494748542020, max: 0xFC62FC642057414C4C, num_nulls: 0]category: BINARY SNAPPY DO:11692686 FPO:12086290 SZ:951115/1108634/1.17 VC:323751 ENC:RLE,PLAIN_DICTIONARY ST:[min: 0x, max: 0xA3, num_nulls: 0]main_category: BINARY SNAPPY DO:12643876 FPO:12708943 SZ:441458/565902/1.28 VC:323751 ENC:RLE,PLAIN_DICTIONARY ST:[min: 0x, max: 0x80, num_nulls: 0]currency: BINARY SNAPPY DO:13085413 FPO:13096079 SZ:194584/363331/1.87 VC:323751 ENC:RLE,PLAIN_DICTIONARY ST:[min: 0x2020372D696E636820746F75636873637265656E203364207072696E74657222, max: 0x78626F782033363020436F6E74726F6C6C657220677561726420262057656253746F726522, num_nulls: 0]deadline: INT96 SNAPPY DO:13280139 FPO:13652989 SZ:2909483/3737353/1.28 VC:323751 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[num_nulls: 21893, min/max not defined]goal: FIXED_LEN_BYTE_ARRAY SNAPPY DO:16189731 FPO:16227239 SZ:550476/587881/1.07 VC:323751 ENC:RLE,PLAIN_DICTIONARY ST:[min: 0.01, max: 100000000.00, num_nulls: 21893]launched: INT96 SNAPPY DO:16740296 FPO:17138437 SZ:3156313/3787662/1.20 VC:323751 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[num_nulls: 18214, min/max not defined]pledged: FIXED_LEN_BYTE_ARRAY SNAPPY DO:19896718 FPO:20110556 SZ:1006933/1652120/1.64 VC:323751 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 0.00, max: 20000000.00, num_nulls: 18214]state: BINARY SNAPPY DO:20903752 FPO:20996238 SZ:360055/683844/1.90 VC:323751 ENC:RLE,PLAIN_DICTIONARY ST:[min: 0x30, max: 0x756E646566696E6564, num_nulls: 0]backers: INT64 SNAPPY DO:21263887 FPO:21282187 SZ:502997/538959/1.07 VC:323751 ENC:RLE,PLAIN_DICTIONARY ST:[min: 0, max: 1193255, num_nulls: 18416]country: BINARY SNAPPY DO:21766974 FPO:21775165 SZ:227901/404041/1.77 VC:323751 ENC:RLE,PLAIN_DICTIONARY ST:[min: 0x224E, max: 0x756E646566696E6564, num_nulls: 0]
3
表中优先使用数字类型
例如:年、月、日。年可以定义为SMALLINT、MONTH和DAY可以定义为TINYINT。数字类型放入到Parquet文件中更节省空间,而且在Join操作时,可以提升内存利用率。
4
使用分区,但不要过度分区
如果某个分区中的数据量每天只有几十兆的数据,按照年月日分区就太细了。以一天为单位查询,集群中的大多数节点可能都处在闲置状态,或者每个节点的负载很低。所以,我们可以减少分区的键,例如:按月或者季度分区,让每个分区中包含几个G的数据。
Impala 2.0+版本,Parquet模块块大小是256MB。如果我们有10个节点,可以设置PARQUETFILESIZE=1g。这样要有10个数据文件(最大10GB)才能让每个节点都工作。而针对多核处理器,每个core都可以并行处理一个单独的block。如果是16核的机器,可以并行处理160GB的数据。如果每个分区只有几个数据文件,不仅仅是大数据的集群节点都将处于闲置,其他机器的CPU core也将处于闲置。此时,可以减小Parquet块大小,例如:调整到128MB或者是64MB,来增加分区的文件数量,来提高并行度。
5
加载数据后始终计算统计信息
Impala应该经常使用有关表和每一列的数据的统计信息,这样可以帮助我们规划密集型操作。例如:Join查询或者将数据插入到Parquet表中的分区。在数据加载到表或者分区后,执行COMPUTE STATS语句。这样,我们就可以操作是否成功,或者是因为内存不足或者是超时的操作。遇到性能或者存储容量问题,更要使用SHOW STATS,检查所有表的统计信息是否都是正常的。
使用EXPLAIN和Summary验证合理的执行计划
在执行资源密集型查询之前,先用EXPLAIN大致了解IMAPALA的执行计划,了解IMPALA会如何并行查询。当发现查询效率低时,可以使用以下步骤进行调优:
更改文件格式
运行COMPUTE STATS语句,并添加QUERY HINTS
执行完查询后,还可以执行SUMMARY命令来查看性能相关信息。
COMPUTE STATS test.t_user_parquet;COMPUTE INCREMENTAL STATS test.t_user_parquet PARTITION(dt='20210116');
执行计划:
EXPLAIN select dt, count(DISTINCT username) from test.t_user_parquet group by 1;Query: EXPLAIN select dt, count(DISTINCT username) from test.t_user_parquet group by 1+------------------------------------------------------------+| Explain String |+------------------------------------------------------------+| Max Per-Host Resource Reservation: Memory=3.88MB Threads=2 || Per-Host Resource Estimates: Memory=26MB || Codegen disabled by planner || || PLAN-ROOT SINK || | || 02:AGGREGATE [FINALIZE] || | output: count(username) || | group by: dt || | row-size=19B cardinality=1 || | || 01:AGGREGATE || | group by: dt, username || | row-size=36B cardinality=1 || | || 00:SCAN HDFS [test.t_user_parquet] || partitions=1/1 files=1 size=1.14KB || row-size=36B cardinality=1 |+------------------------------------------------------------+
使用SUMMARY我们可以看到上一条SQL语句每个阶段的执行信息。
[] default> SELECT y, count(y) FROM year cross join month group by 1;Query: SELECT y, count(y) FROM year cross join month group by 1Query submitted at: 2021-01-20 00:46:12 (Coordinator: http://cdh6-slave1:25000)Query progress can be monitored at: http://cdh6-slave1:25000/query_plan?query_id=9149043bcb376e31:6f5da3fe00000000+------+----------+| y | count(y) |+------+----------+| 2027 | 12 || 2022 | 12 || 2025 | 12 || 2029 | 12 || 2021 | 12 || 2026 | 12 || 2024 | 12 || 2023 | 12 || 2028 | 12 || 2030 | 12 |+------+----------+Fetched 10 row(s) in 0.22s[] default> summary;+------------------------+--------+----------+----------+-------+------------+-----------+---------------+-----------------------+| Operator |+------------------------+--------+----------+----------+-------+------------+-----------+---------------+-----------------------+| F03:ROOT | 1 | 14.05us | 14.05us | | | 0 B | 0 B | || 07:EXCHANGE | 1 | 36.33us | 36.33us | 10 | 10 | 64.00 KB | 16.00 KB | UNPARTITIONED || F02:EXCHANGE SENDER | 1 | 299.16us | 299.16us | | | 11.63 KB | 0 B | || 06:AGGREGATE | 1 | 936.25us | 936.25us | 10 | 10 | 1.96 MB | 10.00 MB | FINALIZE || 05:EXCHANGE | 1 | 20.79us | 20.79us | 10 | 10 | 72.00 KB | 16.00 KB | HASH(y) || F00:EXCHANGE SENDER | 1 | 102.27us | 102.27us | | | 11.63 KB | 0 B | || 03:AGGREGATE | 1 | 637.48us | 637.48us | 10 | 10 | 2.03 MB | 10.00 MB | STREAMING || 02:NESTED LOOP JOIN | 1 | 402.30us | 402.30us | 120 | -1 | 36.00 KB | 2.00 GB | CROSS JOIN, BROADCAST || |--04:EXCHANGE | 1 | 9.38us | 9.38us | 12 | -1 | 16.00 KB | 16.00 KB | BROADCAST || | F01:EXCHANGE SENDER | 1 | 38.43us | 38.43us | | | 128.00 KB | 0 B | || | 01:SCAN HDFS | 1 | 2.65ms | 2.65ms | 12 | -1 | 24.00 KB | 32.00 MB | default.month || 00:SCAN HDFS | 1 | 870.24us | 870.24us | 10 | 10 | 28.00 KB | 32.00 MB | default.year |+------------------------+--------+----------+----------+-------+------------+-----------+---------------+-----------------------+
参考文献:
http://impala.apache.org/docs/build/html/index.html
https://en.wikipedia.org/wiki/Apache_Impala
https://en.wikipedia.org/wiki/Massively_parallel
https://www.tutorialspoint.com/impala/impala_architecture.htm
https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/impala_admission.html
[引用]
THE
END
推荐你看 以上是关于Apache Impala(五) Impala数据导入方式的主要内容,如果未能解决你的问题,请参考以下文章