一.spark内存模型和执行计划过程
Posted 上官沐雪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一.spark内存模型和执行计划过程相关的知识,希望对你有一定的参考价值。
一. spark内存模型和执行计划过程
1. spark内存模型
 说明:
说明:
总内存分为:
统一内存(60%)和其他内存(40%)。
1. 其中统一内存分为:storage存储内存,和Execution执行内存,分别占50%。
storage内存用于broadcast、缓存cache 数据:
Storage 堆内内存=(spark.executor.memory–300MB) * spark.memory.fraction * spark.memory.storageFraction
Execution执行Shuffle、Join、Sort 等计算过程中的临时数据:
Execution 堆内内存=(spark.executor.memory–300MB) * spark.memory.fraction * (1-spark.memory.storageFraction)
other :主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息:
Reserved Memory:系统预留内存,会用来存储Spark内部对象
堆外内存:一种是DirectMemory, 一种是JVM Overhead。主要用于程序的共享库、Perm Space、 线程Stack和一些Memory mapping等, 或者类C方式allocate object
2. 执行计划过程
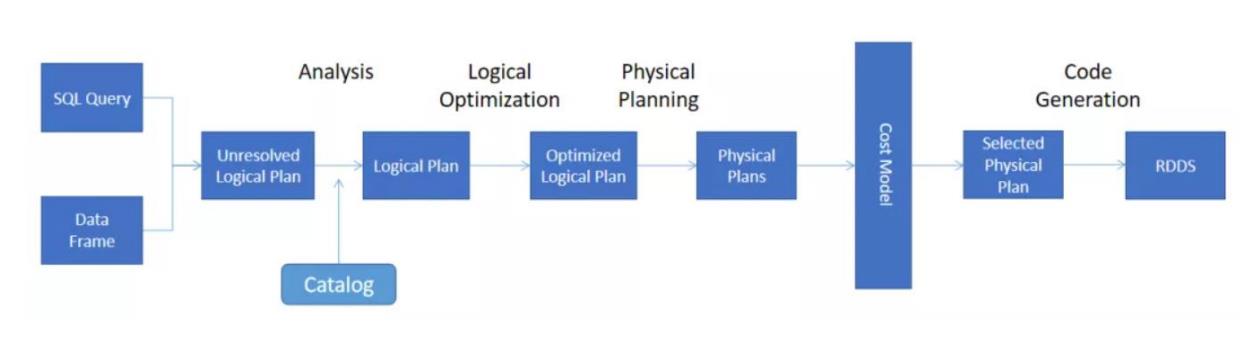
- Unresolved 逻辑执行计划:Parser 组件检查 SQL 语法上是否有问题,然后生成 Unresolved(未决断)的逻辑计划,不检查表名、不检查列名。
- Resolved 逻辑执行计划:通过访问 Spark 中的 Catalog 存储库来解析验证语义、列名、类型、表名等。
- 优化后的逻辑执行计划:Catalyst 优化器根据各种规则进行优化。sql经过RBO优化生成最终的逻辑计划。
- 物理执行计划:根据CBO选择最终的物理执行计划
1)HashAggregate 运算符表示数据聚合,一般 HashAggregate 是成对出现,第一个
HashAggregate 是将执行节点本地的数据进行局部聚合,另一个 HashAggregate 是
将各个分区的数据进一步进行聚合计算。
2)Exchange 运算符其实就是 shuffle,表示需要在集群上移动数据。很多时候
HashAggregate 会以 Exchange 分隔开来
3)Project 运算符是 SQL 中的投影操作,即列裁剪
4)BroadcastHashJoin 运算符表示通过基于广播方式进行 HashJoin。
5)LocalTableScan 运算符就是全表扫描本地的表
以上是关于一.spark内存模型和执行计划过程的主要内容,如果未能解决你的问题,请参考以下文章