爬虫系列 2.2 爬虫基础2 -网页结构进阶
Posted yk 坤帝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫系列 2.2 爬虫基础2 -网页结构进阶相关的知识,希望对你有一定的参考价值。
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
2.2.1 HTML基础1 - 我的第一个网页
html(HyperText Markup Language)是一种用于写这些框架的的标准标记语言,这一小节主要就是讲如何利用它来进行网页搭建。
2.2.2 代码编辑器
荐一款代码编辑器:Notepad++,其作用和Pycharm类似,都是方便来编写HTML代码的,当然如果觉得麻烦的话,完全也可以不用下载,直接在txt中敲代码也是完全可以的。其下载地址为:https://notepad-plus-plus.org/,在刚刚创建的那个html文件右击,选择“Edit with Notepad++”可以打开文件进行代码编写,界面如下:

2.2.3 HTML基础知识2 - 基础结构
首先用notepad++打开刚刚的html文件(如果没有安装,右键点击html文件在打开方式里选择记事本打开即可),将原来的代码先补充些内容:

然后ctrl + s快捷键保存,在刚刚的网页上刷新,可以看到变成如下内容:

网页出现乱码(乱码就是中文显示成奇怪的符号),可以把charset="utf-8"中的utf-8改成gbk,这是两种不同的中文格式,各个浏览器可能各有不同。
2.2.4 HTML基础知识3 - 标题、段落、链接
标题标签:
标题是通过
-
标签来定义的,
一般格式为:
标题内容
。其中h1的字号最大,h6的字号最小
(2) 段落
标签:
段落是通过标签
来定义的,一般格式为:
段落内容
。比如我们在刚刚的基础上略作修改:

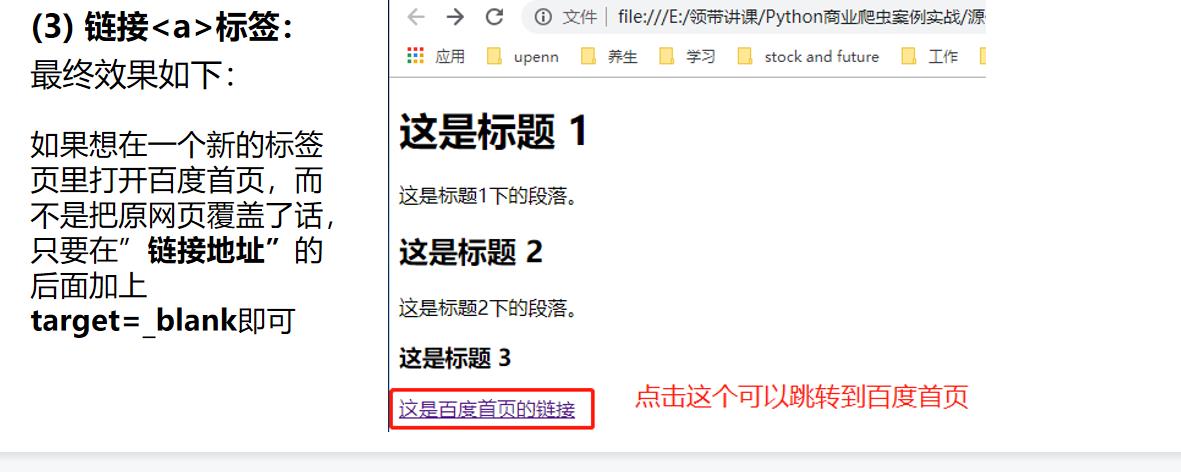
(3) 链接标签:

2.2.5 HTML基础知识4 - 区块
区块最主要的表现形式就是
可以看到每个新闻都被包围在一个叫做
用F12看百度新闻的源码:

2.2.6 HTML基础知识5 - 类(class)与 ID


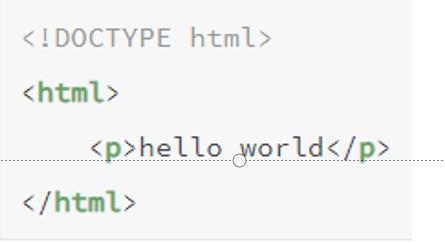
2.2.1 我的第一个网页
<!DOCTYPE html>
<html>
<p>hello world</p>
</html>

2.2.3 逐渐完善的网页
<!DOCTYPE html>
<html>
<body>
<h1>���DZ��� 1</h1>
<p>���DZ���1�µĶ��䡣</p>
<h2>���DZ��� 2</h2>
<a href="https://www.baidu.com">���Ǵ����ӵ�����</a>
</body>
</html>

个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
以上是关于爬虫系列 2.2 爬虫基础2 -网页结构进阶的主要内容,如果未能解决你的问题,请参考以下文章