[YOLO专题-14]:YOLO V5 - ultralytics在自定义数据集上获得高性能的常见关键项
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[YOLO专题-14]:YOLO V5 - ultralytics在自定义数据集上获得高性能的常见关键项相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122302497
目录
前言:
YOLO V5官方提供的性能指标,是在YOLO V5指定的数据集和相应的超参数设置下获的的最佳性能,而不仅仅取决于网络,该性能是数据集、模型、超参数设置相关因素共同作用的效果。
用户要想在自己的数据集上获的最佳的训练效果,有些常规的最佳实践还是需要遵守的。
如下来自官网的建议。
Tips for Best Training Results 📌 - YOLOv5 Documentation
第1步:数据集的优化
训练数据集对于模型最终的训练效果,有这至关重要的影响,主要的影响因素或建议如下:
(1)图像的数量
每一种分类的图片的数量要大于1.5K张。确保模型有足够的泛化能力。
(2)标签的目标实例的数量
每一种分类,该数量要大于10K个。
(3)图片的变化性
训练图片具备代表性,能够代表实际部署情形不同场景下的图片。
对于实际图片目标用例,推荐来自一天中不同时间、不同季节、不同天气、不同光照、不同角度、不同来源(在线抓取、本地收集、不同相机)等的图像。这样确保训练图片具备最广泛的代表性,而不仅仅代表某种场合。
(4)标签的一致性
模型会把所有没有标注的目标,识别成背景。因此,所有图像中所有类的所有需要识别的实例都必须标记。部分标签将导致副作用,比如“图片中的dog”, 部分标注,而部分不标注,将导致负面效果,训练时,模型就容易混淆,相同的“狗的属性”,有时候要识别成“狗”,有时候又不需要识别成“狗”,这就比较麻烦。
任何需要是不的对象,在训练数据集中都不应缺少标签,确保目标对象标签的一致性。
(5)标签准确性
- 标签必须紧密地包围每个对象。
对象与其边界框之间不应存在空间。因为机器很傻,它会把边界框内的所有像素点都作为“目标”特征的一部分,对象与其边界框也会被认为是目标对象的一部分。如果这部分在预测的图片中,不存在,这就容易容模型降低在实际预测目标时的相似度。
(6)背景图片的添加
背景图像是指没有对象的图像,把这些图像添加到数据集中,能够降低非目标对象错误的识别成目标对象的概率。也就说,这些图片,能够帮助模型识别,哪些目标是不需要识别的,他们仅仅作为背景图片的一部分。
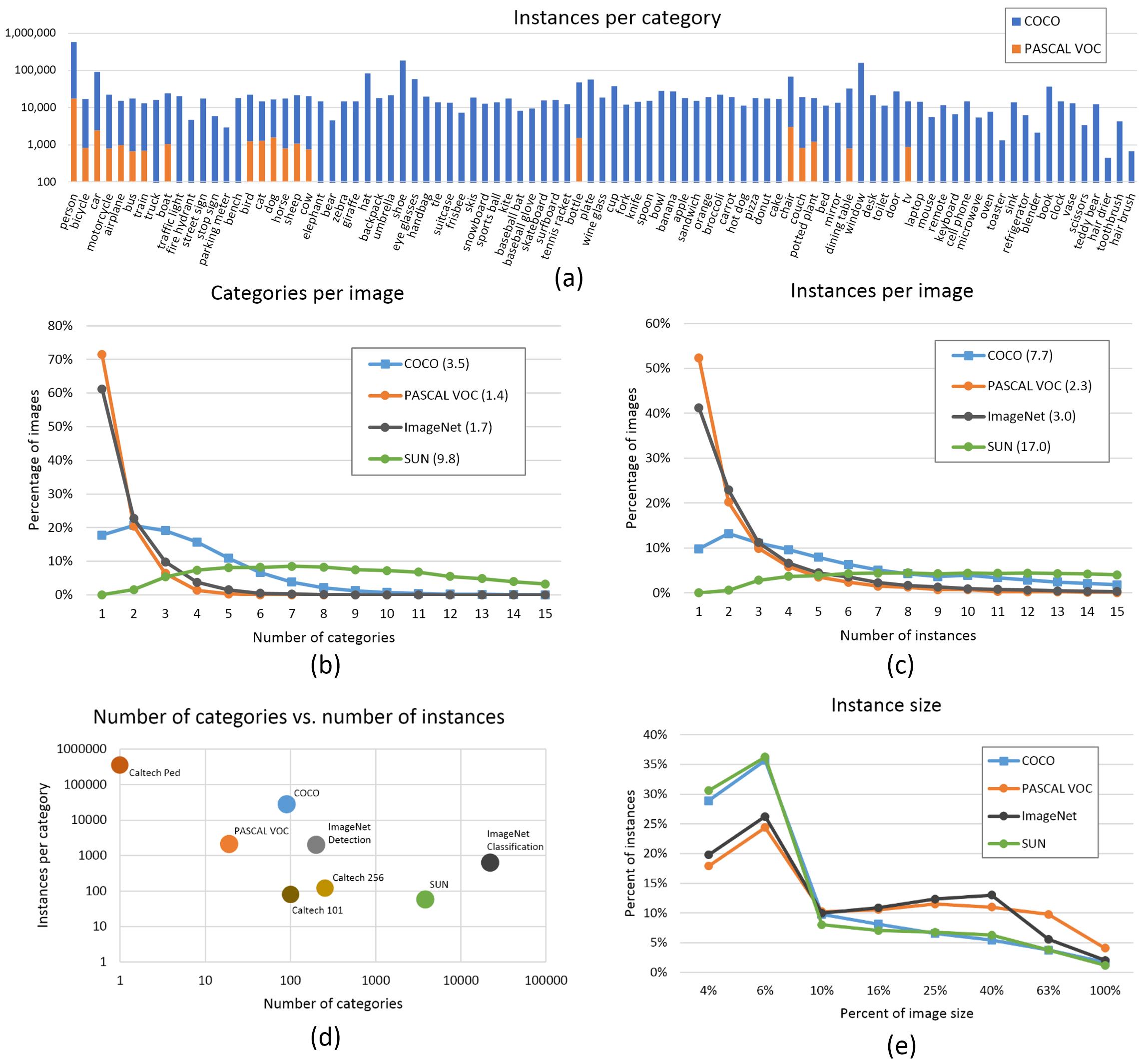
背景图片的数量,建议占总体图片数量的0-10%之间,COCO 数据集就有 1000 张背景图片可供参考,占总数的 1%,如下图所示:
第2步:模型的选择
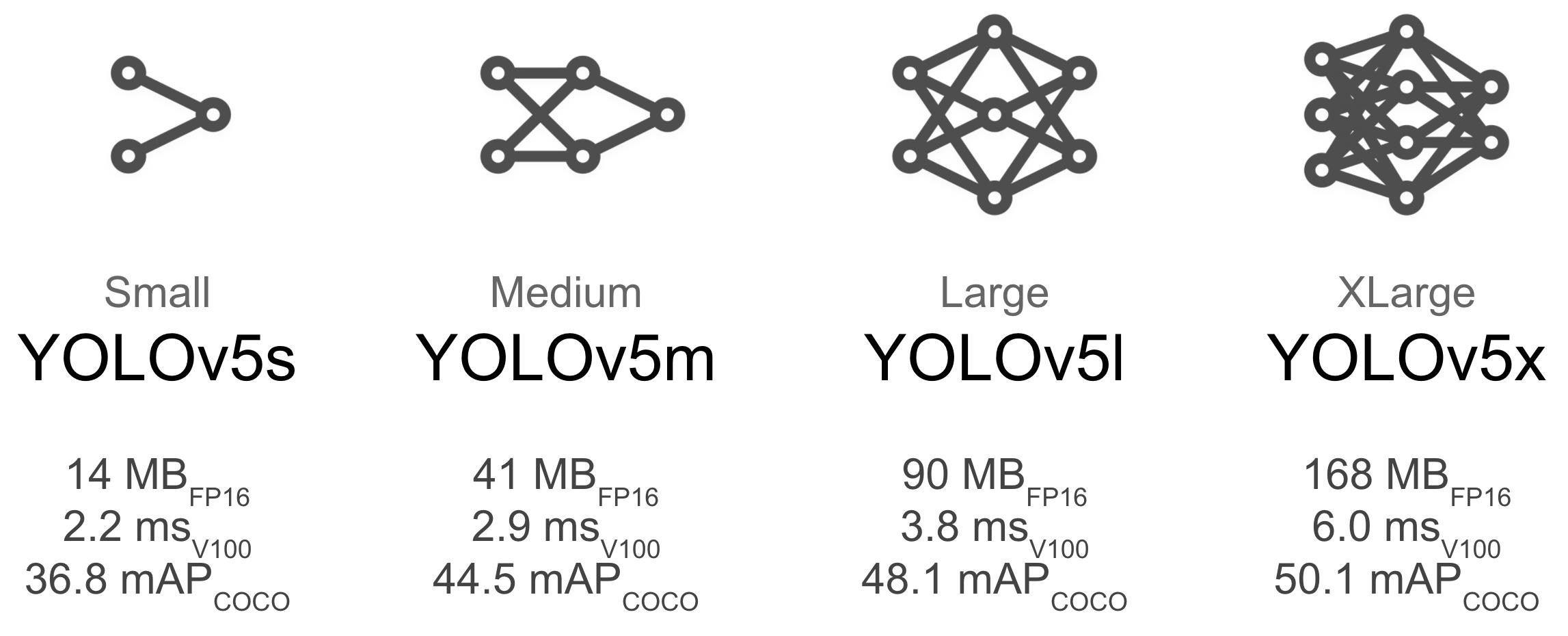
不同的模型,有不用的应用场景和目标。小的模型,追求的是速度,大的模型,追求的是准确率。
YOLOv5x 和YOLOv5x6等较大的模型几乎在所有情况下都会产生更好的结果,但参数更多,需要更多的 CUDA 内存来训练,并且运行速度较慢。
对于移动部署,我们推荐 YOLOv5s/m。
对于云部署,我们推荐 YOLOv5l/x。
不同模型的选择,可以参见:
 https://blog.csdn.net/HiWangWenBing/article/details/122294915
https://blog.csdn.net/HiWangWenBing/article/details/122294915第3步:模型训练过程的优化
3.1 情形1:从预训练模型(权重文件)开始
如果用户的数据集是小型数据集,没有充足的数据量,要基于这样的数据集训练模型,建议从官网提供的预训练模型开始,以官网的预训练模型为基准。除了节省训练时间,还能够提升模型的准确性。因为预训练模型是在复杂、大型数据集上获的的,它具备最大的泛化能力,具备广泛的特征提取的能力。
小型的用户数据集,不适合训练特征提取网络,只适合训练分类与目标检查的输出网络。
因此,基于预训练的权重的模型,再进一步对用户的数据集进行训练,既能够节省时间,也能够提升用户数据集上训练结果的准确性。
对于小型的数据集,如果完全从头开始训练,容易导致网络过拟合,泛化能力差等不好的效果。
训练命令如下:
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt通过--weights 参数,(1)指定模型;(2)指定对应的权重文件。
如果在yolov5工程的根目录中,找不到相应的预训练权重文件,如yolov5s.pt,则YOLO V5的工程代码会自动从官网上下载相应的权重文件。
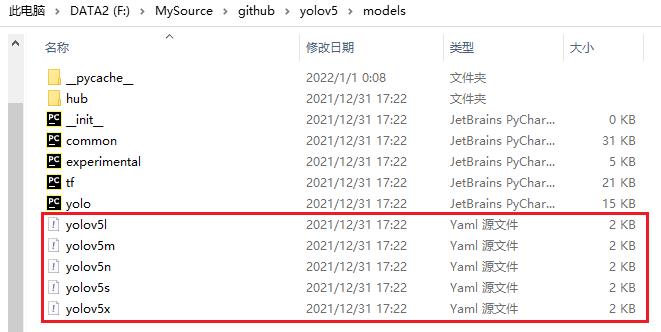
这种方式,模型训练的参数,使用默认的模型参数,模型的参数被定义在预定义的模型配置文件中:
如下图所示:
3.2 情形2:从头开始训练
如果用户的数据集是大型数据集,有足够多的样本来训练模型,则可以不用基于官网提供的预训练模型开始,而是从头开始训练自己的模型权重参数。
这种方式需要注意如下几点:
(1)训练的时间较长,正常情况下,需要1个星期以上。
(2)模型的权重设定为“空”: --weights '' "
(3)由于权重文件,YOLO V5不知道用户需要使用什么的模型(YOLO V5多种规模的模型),因此需要通过--cfg 参数,指定模型本身的参数或配置。命令如下图所示:
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yamlyolov5s.yaml是模型的配置文件,其位于models目录中:
模型配置文件的内容如下图所示:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes # 分类数目
depth_multiple: 0.33 # model depth multiple # 模型的深度倍数,值越小,模型的规模越小
width_multiple: 0.50 # layer channel multiple # 模型通道的倍数,值越小,模型的规模越小
anchors: # 先验框: 3 * 3 = 9个
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone # 特征提取网络
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3.3 模型训练超参数的选择
在修改任何内容之前,首先使用默认设置进行训练以建立性能基线,作为后续的比较基准。
train.py 设置的完整列表可以在train.py argparser 中找到。
(1)epoch。
至少从 300 个 epoch 开始,过少的epoch会导致模型训练不够充分。但如果这过拟合,那么您可以减少 epochs。如果在 300 个 epoch 后没有发生过拟合,则可是使的训练更长时间,即 600、1200 个等 epoch。
(2)图片大小。
COCO数据集使用默认的--img 640。
如果用户的数据集上有大量的小目标,那么使用--img 1280可以获得更好的性能。但需要注意的是,如果在--img 1280上进行训练,那么也需要在--img 1280上进行预测。
(3)批量大小。
使用--batch-size您的硬件允许的最大尺寸。小批量会产生较差的批量规范统计数据,应避免使用。
(4)超参数(Hyperparameters)
默认超参数存在与hyp.scratch.yaml文件中。
我们建议您先使用默认超参数进行训练,然后再考虑修改任何超参数。
一般来说,增加增强超参数将减少和延迟过拟合,允许更长的训练和更高的最终 mAP。
减少损失分量增益超参数hyp['obj']将有助于减少那些特定损失分量的过度拟合。
有关优化这些超参数的自动化方法,请参阅我们的超参数演化教程。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122302497
以上是关于[YOLO专题-14]:YOLO V5 - ultralytics在自定义数据集上获得高性能的常见关键项的主要内容,如果未能解决你的问题,请参考以下文章