第二十篇:Summarisation摘要
Posted flying_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二十篇:Summarisation摘要相关的知识,希望对你有一定的参考价值。
目录
ROUGE(Recall Oriented Understudy for Gisting Evaluation):
摘要
• 从文本中提取最重要的信息以生成缩短或删节的版本
• 例子
‣ 文档大纲
‣ 科学文章摘要
‣ 新闻标题
‣ 搜索结果片段
总结什么?
• 单一文档摘要
‣ 输入:单个文档
‣ 输出:表征内容的摘要
• 多文档摘要
‣ 输入:多个文档
‣ 输出:捕获所有文档要点的摘要
‣ 例如 从多个来源或角度总结新闻事件
• 提取总结
‣ 通过从文档中选择具有代表性的句子进行总结
• 抽象总结
‣ 用自己的话概括内容
‣ 摘要通常是对原始内容的转述
总结的目标?
• 通用摘要
‣ 摘要提供文档中的重要信息
• 以查询为中心的摘要
‣ 摘要响应用户查询
‣ 类似于问答
‣ 但是答案要长得多(不仅仅是短语)
大纲
• 提取总结
‣ 单文档
‣ 多文档
• 抽象总结
‣ 单文档(深度学习模型!)
• 评估
提取总结-单文档
摘要系统
• 内容选择:选择要从文档中提取的句子
• 信息排序:决定如何对提取的句子进行排序
• 句子实现:清理以确保组合句子流畅
• 我们将专注于内容选择
• 对于单个文档摘要,不需要信息排序
‣ 以原始顺序呈现提取的句子
• 如果以点点形式呈现,也不需要实现句子
内容选择
• 使用真实提取句子的数据不多
• 主要是无监督方法
• 目标:找出重要或突出的句子
方法一:TF-IDF
• 文档中的常用词 → 突出
• 但是一些通用词非常频繁但没有提供信息
‣ 虚词
‣ 停用词
• 通过其逆文档频率对文档中的每个单词进行加权:

方法 2:对数似然比
• 直觉:如果一个词在输入语料库中的概率与背景语料库非常不同,则该词是显着的

•是之间的比率:
‣ 假设 P(w|I) = P(w|B) =p, I 指的是输入语料,B指的是背景语料
P(w|I):
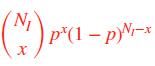
P(w|B):

p:

‣ 假设 P(w|I) =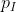 ,P(w|B) =
,P(w|B) = , I 指的是输入语料,B指的是背景语料
, I 指的是输入语料,B指的是背景语料
P(w|I):

P(w|B):
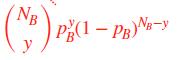
:

:
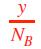
一个句子的显着性?
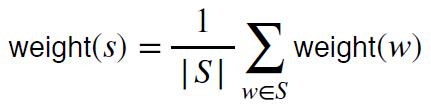
只考虑 S 中的非停用词
方法 3:句子中心性
• 对句子进行排序的替代方法
• 测量句子之间的距离,并选择与其他句子更接近的句子
• 使用 tf-idf BOW 表示句子
• 使用余弦相似度测量距离
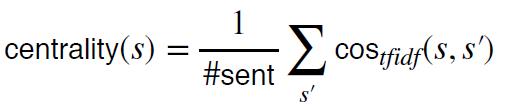
最终提取摘要
• 使用排名靠前的句子作为提取摘要
‣ 显着性(tf-idf 或对数似然比)
‣ 中心性
方法四:RST解析
• 修辞结构理论(第十一篇文章,话语):解释从句是如何连接的
• 定义核心(主要从句)和卫星(支持从句)之间的关系类型
• 核心比卫星更重要
• 一个句子作为更多句子的核心=更显着
提取总结-多文档
摘要系统
• 类似于单文档提取摘要系统
• 挑战:
‣ 信息冗余
‣ 句子排序
内容选择
• 我们可以使用相同的无监督内容选择方法(tf-idf、对数似然比、中心性)来选择显着句子
• 但忽略多余的句子
最大边际相关性
• 反复选择要添加到摘要的最佳句子
• 要添加的句子必须新颖
• 如果候选句子与提取的句子相似,则对其进行惩罚:

• 添加所需数量的句子时停止
信息排序
• 时间顺序:
‣ 按文档日期排序
• 连贯性:
‣ 以相邻句子相似的方式排序
‣ 基于实体组织方式的排序(中心理论,第十一篇文章)
句子实现
• 确保实体被连贯地引用
‣ 首次提及时的全名
‣ 后续提及的姓氏
• 应用共指方法来首先提取名称
• 编写规则以进行清理
抽象总结-单文档(深度学习模型!)
• 释义
• 一项非常艰巨的任务
• 我们可以训练一个神经网络来生成摘要吗?
Encoder-Decoder?
• 如果我们对待:
‣ 源句 = “文档”
‣ 目标句 = “摘要”
数据
• 新闻头条
• 文档:文章的第一句
• 摘要:新闻标题/标题
• 从技术上讲更像是“标题生成任务”
更多摘要数据
• 但标题生成并不令人兴奋……
• 其他汇总数据:
‣ CNN/Dailymail:30 万篇文章,以项目符号汇总
‣ 新闻室:130 万篇文章,作者总结
- 各种各样的; 38种主要出版物
‣ XSum:200K BBC 文章
- 摘要比其他数据集更抽象
改进
• 注意力机制
• 更丰富的单词特征:POS 标签、NER 标签、tf-idf
• 分层编码器
‣ 一个用于单词的 LSTM
‣ 另一个用于句子的 LSTM
复制机制
• 生成重现文档中详细信息的摘要
• 可以通过将它们复制到文档中来在摘要中生成词汇外的单词
‣ 例如 smergle = 词汇量之外
‣ p(smergle) = 注意力概率 + 生成概率 = 注意力概率
最新发展
• 最先进的模型使用transformers而不是 RNN
• 大量的预训练
• 注意:BERT 不直接适用,因为我们需要一个单向解码器(BERT 只是一个编码器)
评估
ROUGE(Recall Oriented Understudy for Gisting Evaluation):
• 与 BLEU 类似,评估生成的摘要和参考/人工摘要之间的单词重叠程度
• 但以找回为导向
• 度量在 N-gram 中分别重叠(例如,从 1 到 3)
• ROUGE-2:从生成的摘要中的参考计算二元组的百分比
ROUGE-2: 例子
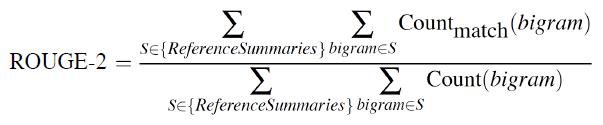

最后
• 研究重点是单文档抽象摘要
‣ 主要是新闻数据
• 但要摘要的数据类型很多:
‣ 图片、视频
‣ 图表
‣ 结构化数据:例如 病历、表格
• 多文档抽象摘要
OK,今天的内容就到这里了,辛苦大家观看!有问题随时评论交流哈!
以上是关于第二十篇:Summarisation摘要的主要内容,如果未能解决你的问题,请参考以下文章