A Large-Scale Chinese Short-Text Conversation Dataset
Posted Facico
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了A Large-Scale Chinese Short-Text Conversation Dataset相关的知识,希望对你有一定的参考价值。
A Large-Scale Chinese Short-Text Conversation Dataset
- 大型中文短文本对话数据集
提供已清洗中文对话数据集LCCC,有base、large版本
所有模型和数据https://github.com/thu-coai/CDial-GPT
数据集
采用了推特、Reddit、微博以及技术论坛等社交媒体来建立语料库。
- 公开的资源语料库非常丰富的,但也包含了许多噪音点,这些噪音点需要处理。
通过众包资源来构建高质量的对话数据集,服务于更高级的对话任务
- 如维基百科向导(WoW)、基于文档的对话(DoG),用于基于知识的对话生成,针对角色PERSON-CHAT对话生成,以及DailyDialog用于情感对话生成等
数据收集
LCCC-base使用两阶段数据收集的方案用于构建我们的原始对话。
第一阶段
收集一组种子用户
- 我们手动选择了一批跟随专业大众媒体致力于发布新闻的微博帐号,然后将其视为高质量用户,并用bot更新
第二阶段
收集这些种子用户的对话
- 按照树状组织结构的下方评论来收集这些用户的微博帖子(从根到叶的任何路径都可以视为对话的一部分)
LCCC-large:从多个开源存储库中收集了语料库,包括中国Chatterbot语料库,PTT闲话语料库,OpenSubtitles语料库和小黄鸡语料库。这些数据集与青云语料库和贴吧语料库一起被清洗,并处理为单轮对话数据集
数据清洗
基于规则的噪音过滤
- 1、删除在对话中的平台标签
- 2、从网址字符串中删除文本
- 3、对话数超过30的会话拆分为多轮对话数少于30的会话
- 4、在一个句子中仅保留重复超过6次的短语或单词
- 5、如果回答太长或太短,则删除对话
- 6、如果识别为广告则移除对话
- 7、如果回复中90%的三元组是高频三元组,则删除对话
- 8、如果回复具有某些特定形式的通用回复,则删除对话
- 9、删除回复与帖子相同的对话
构建噪声黑名单,若对话中有此类,则删除对话
1、脏话,敏感词和方言
2、有专业术语
3、名称,称谓和未知缩写
4、特殊符号和表情符号
5、平台标志,例如与广告,图片和视频相关的单词
基于分类器的过滤
与语义语法上下文等相关的对话,难以用规则过滤,因此构建两个BERT分类器来更精细的过滤
-
第一个分类器使用手动标记的10w个会话进行训练,若对话中有规则上的噪声或以下噪声则被标记为嘈杂(测试集的分类精度达到73.76%):
- 1、回复不流畅或句子中有严重错别字
- 2、回复的信息不完整
- 3、对话的主题是有时效性的
- 4、帖子中未提及的节日,地点,性别和时间出现在回复中
- 5、帖子和回复无关
-
第二个BERT分类器在包含10,000个发音的手动标记数据集上进行了训练(社交媒体上对话经常会依赖于文本之外得到上下文,使其难以理解)
- 在测试集上,分类器准确率达到77.60%
两种形式的过滤例子如下图所示

数据集的统计和结果
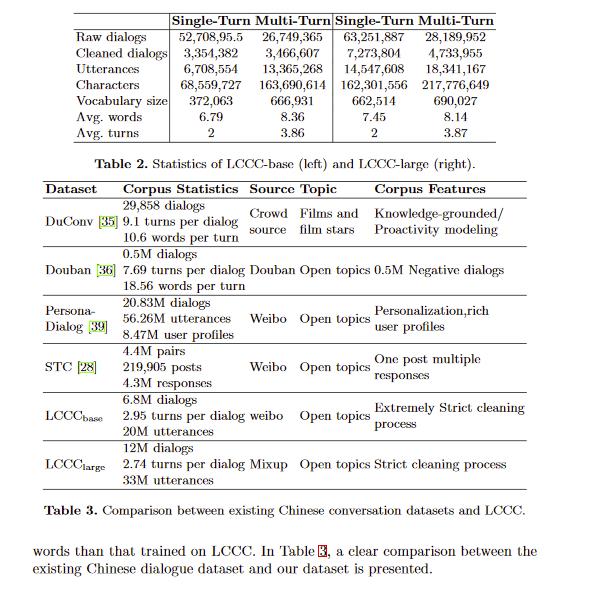
模型
模型使用GPT
- 输入表示:将所有的历史话语连成一个序列,模型的输入是word embedding, speaker embedding, position embedding得到和
- speaker embedding用于代表不同的speakers,使用speaker symbol来作为分隔的token
训练
- GPT_Novel:12层GPT,在Chinese Novel上经过70轮的预训练,该数据集由各种流派(喜剧,浪漫,推理),大约0.5亿个token组成。
- CDialGPT_LCCC-base:12层GPT,在Chinese Novel上预训练了70轮,并在LCCC-base数据集上进行30轮post-training。(这里还有一个用GPT2训练的,训练方式层数一样)
- CDialGPT_LCCC-large:12层GPT,在Chinese Novel上预训练了70轮,并在LCCC-large数据集上进行30轮post-training。
实验和fine-tune


-
可以看到效果挺好
-
fine-tune
- GPTNovel最多可以微调30轮。
- 所有其他模型都可以在相同的批次大小和梯度累积数量的情况下微调多达10轮

- PPL很好,bleu-2比transformer差,这和之前的工作结论相似,而之前的工作表名PPL更接近人类评估,所以本模型更有竞争力
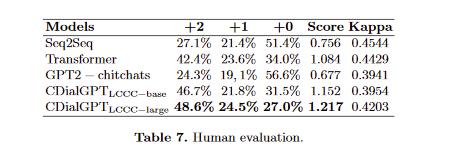
- 人类评估如上
以上是关于A Large-Scale Chinese Short-Text Conversation Dataset的主要内容,如果未能解决你的问题,请参考以下文章