Elasticsearch:运用 Java 对索引进行 nested 搜索
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:运用 Java 对索引进行 nested 搜索相关的知识,希望对你有一定的参考价值。
在我之前的文章 “Elasticsearch: nested 对象”,我详细地描述了如何使用 nested 数据类型来进行搜索及聚合。 Elasticsearch 不是关系数据库!nested 数据类型是一种可以描述数据关系的一种类型。简单地说,nested 是一种特殊的字段数据类型,它允许对象数组以一种可以相互独立查询的方式进行索引。如果你的数据字段里:
- 含有数组数据
- 在查询或聚合的时候可能会使用到这个字段里的两个及以上的子字段进行查询
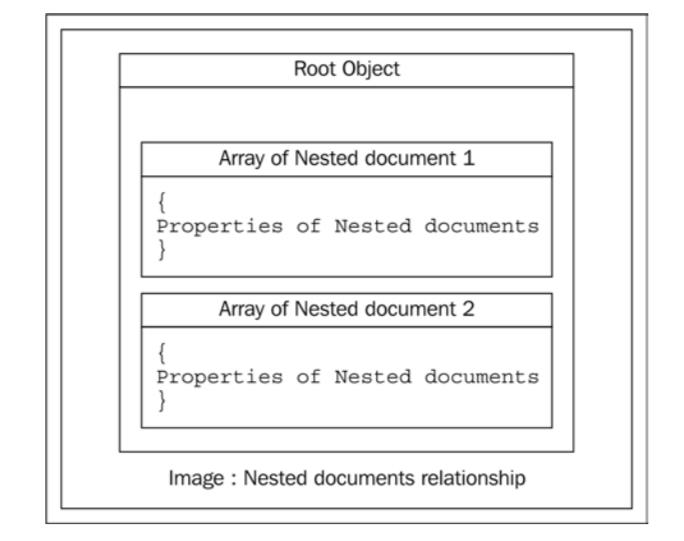
在这种情况下,我们需要使用到 nested 数据类型。
Nested 示例
我们建立如下的一个 mapping:
PUT developer
"mappings":
"properties":
"name":
"type": "text"
,
"skills":
"type": "nested",
"properties":
"language":
"type": "keyword"
,
"level":
"type": "keyword"
我们创建两个文档:
POST developer/_doc/101
"name": "zhang san",
"skills": [
"language": "ruby",
"level": "expert"
,
"language": "javascript",
"level": "beginner"
]
POST developer/_doc/102
"name": "li si",
"skills": [
"language": "ruby",
"level": "beginner"
]
如上所示,我们的 skills 字段里含有数组数据。当我们针对这个 skills 字段进行搜索时,并且同时使用 language 及 level 进行搜索时,我们需要使用 nested 字段。
针对 nested 搜索的 Java 实现
我们可以参考之前的文章:
来创建一个 Java 项目。为了大家方便,我创建了一个 github 的项目:GitHub - liu-xiao-guo/ElasticsearchNestedQuery。
ElasticsearchNestedQuery.java
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.apache.lucene.search.join.ScoreMode;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.NestedQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
import java.util.Arrays;
import java.util.Map;
public class ElasticsearchNestQuery
private final static String INDEX_NAME = "developer";
private static RestHighLevelClient client = null;
private static synchronized RestHighLevelClient makeConnection()
final BasicCredentialsProvider basicCredentialsProvider = new BasicCredentialsProvider();
basicCredentialsProvider
.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("elastic", "password"));
if (client == null)
client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback()
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder)
httpClientBuilder.disableAuthCaching();
return httpClientBuilder.setDefaultCredentialsProvider(basicCredentialsProvider);
)
);
return client;
public static void main(String[] args)
client = makeConnection();
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(INDEX_NAME);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
String nestedPath="skills";
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
MatchQueryBuilder matchQuery1 =
QueryBuilders.matchQuery("skills.language", "ruby");
MatchQueryBuilder matchQuery2 =
QueryBuilders.matchQuery("skills.level", "expert");
NestedQueryBuilder nestedQuery = QueryBuilders
.nestedQuery(nestedPath, boolQueryBuilder.must(matchQuery1).must(matchQuery2), ScoreMode.None);
searchSourceBuilder.query(nestedQuery);
searchRequest.source(searchSourceBuilder);
Map<String, Object> map = null;
try
SearchResponse searchResponse = null;
searchResponse =client.search(searchRequest, RequestOptions.DEFAULT);
if (searchResponse.getHits().getTotalHits().value > 0)
SearchHit[] searchHit = searchResponse.getHits().getHits();
for (SearchHit hit : searchHit)
map = hit.getSourceAsMap();
System.out.println("output::"+ Arrays.toString(map.entrySet().toArray()));
catch (IOException e)
e.printStackTrace();
上面的代码是实现如下的搜索:
GET developer/_search
"query":
"nested":
"path": "skills",
"query":
"bool":
"filter": [
"match":
"skills.language": "ruby"
,
"match":
"skills.level": "expert"
]
上面搜索的结果:
"took" : 0,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 1,
"relation" : "eq"
,
"max_score" : 0.0,
"hits" : [
"_index" : "developer",
"_type" : "_doc",
"_id" : "101",
"_score" : 0.0,
"_source" :
"name" : "zhang san",
"skills" : [
"language" : "ruby",
"level" : "expert"
,
"language" : "javascript",
"level" : "beginner"
]
]
运行上面的 Java 代码结果为:
output::[skills=[level=expert, language=ruby, level=beginner, language=javascript], name=zhang san]
以上是关于Elasticsearch:运用 Java 对索引进行 nested 搜索的主要内容,如果未能解决你的问题,请参考以下文章