python常用到哪些库
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python常用到哪些库相关的知识,希望对你有一定的参考价值。
第一、NumPy
NumPy是NumericalPython的简写,是Python数值计算的基石。它提供多种数据结构、算法以及大部分涉及Python数值计算所需的接口。NumPy还包括其他内容:
①快速、高效的多维数组对象ndarray
②基于元素的数组计算或数组间数学操作函数
③用于读写硬盘中基于数组的数据集的工具
④线性代数操作、傅里叶变换以及随机数生成
除了NumPy赋予Python的快速数组处理能力之外,NumPy的另一个主要用途是在算法和库之间作为数据传递的数据容器。对于数值数据,NumPy数组能够比Python内建数据结构更为高效地存储和操作数据。
第二、pandas
pandas提供了高级数据结构和函数,这些数据结构和函数的设计使得利用结构化、表格化数据的工作快速、简单、有表现力。它出现于2010年,帮助Python成为强大、高效的数据分析环境。常用的pandas对象是DataFrame,它是用于实现表格化、面向列、使用行列标签的数据结构;以及Series,一种一维标签数组对象。
pandas将表格和关系型数据库的灵活数据操作能力与Numpy的高性能数组计算的理念相结合。它提供复杂的索引函数,使得数据的重组、切块、切片、聚合、子集选择更为简单。由于数据操作、预处理、清洗在数据分析中是重要的技能,pandas将是重要主题。
第三、matplotlib
matplotlib是最流行的用于制图及其他二维数据可视化的Python库,它由John D.
Hunter创建,目前由一个大型开发者团队维护。matplotlib被设计为适合出版的制图工具。
对于Python编程者来说也有其他可视化库,但matplotlib依然使用最为广泛,并且与生态系统的其他库良好整合。
第四、IPython
IPython项目开始于2001年,由FernandoPérez发起,旨在开发一个更具交互性的Python解释器。在过去的16年中,它成为Python数据技术栈中最重要的工具之一。
尽管它本身并不提供任何计算或数据分析工具,它的设计侧重于在交互计算和软件开发两方面将生产力最大化。它使用了一种执行-探索工作流来替代其他语言中典型的编辑-编译-运行工作流。它还提供了针对操作系统命令行和文件系统的易用接口。由于数据分析编码工作包含大量的探索、试验、试错和遍历,IPython可以使你更快速地完成工作。
第五、SciPy
SciPy是科学计算领域针对不同标准问题域的包集合。以下是SciPy中包含的一些包:
①scipy.integrate数值积分例程和微分方程求解器
②scipy.linalg线性代数例程和基于numpy.linalg的矩阵分解
③scipy.optimize函数优化器和求根算法
④scipy.signal信号处理工具
⑤scipy.sparse稀疏矩阵与稀疏线性系统求解器
SciPy与Numpy一起为很多传统科学计算应用提供了一个合理、完整、成熟的计算基础。
第六、scikit-learn
scikit-learn项目诞生于2010年,目前已成为Python编程者首选的机器学习工具包。仅仅七年,scikit-learn就拥有了全世界1500位代码贡献者。其中包含以下子模块:
①分类:SVM、最近邻、随机森林、逻辑回归等
②回归:Lasso、岭回归等
③聚类:K-means、谱聚类等
④降维:PCA、特征选择、矩阵分解等
⑤模型选择:网格搜索、交叉验证、指标矩阵
⑥预处理:特征提取、正态化
scikit-learn与pandas、statsmodels、IPython一起使Python成为高效的数据科学编程语言。
参考技术A第一、NumPy
NumPy是Numerical
Python的简写,是Python数值计算的基石。它提供多种数据结构、算法以及大部分涉及Python数值计算所需的接口。NumPy还包括其他内容:
①快速、高效的多维数组对象ndarray
②基于元素的数组计算或数组间数学操作函数
③用于读写硬盘中基于数组的数据集的工具
④线性代数操作、傅里叶变换以及随机数生成
除了NumPy赋予Python的快速数组处理能力之外,NumPy的另一个主要用途是在算法和库之间作为数据传递的数据容器。对于数值数据,NumPy数组能够比Python内建数据结构更为高效地存储和操作数据。
第二、pandas
pandas提供了高级数据结构和函数,这些数据结构和函数的设计使得利用结构化、表格化数据的工作快速、简单、有表现力。它出现于2010年,帮助Python成为强大、高效的数据分析环境。常用的pandas对象是DataFrame,它是用于实现表格化、面向列、使用行列标签的数据结构;以及Series,一种一维标签数组对象。
pandas将表格和关系型数据库的灵活数据操作能力与Numpy的高性能数组计算的理念相结合。它提供复杂的索引函数,使得数据的重组、切块、切片、聚合、子集选择更为简单。由于数据操作、预处理、清洗在数据分析中是重要的技能,pandas将是重要主题。
第三、matplotlib
matplotlib是最流行的用于制图及其他二维数据可视化的Python库,它由John D.
Hunter创建,目前由一个大型开发者团队维护。matplotlib被设计为适合出版的制图工具。
对于Python编程者来说也有其他可视化库,但matplotlib依然使用最为广泛,并且与生态系统的其他库良好整合。
第四、IPython
IPython项目开始于2001年,由Fernando
Pérez发起,旨在开发一个更具交互性的Python解释器。在过去的16年中,它成为Python数据技术栈中最重要的工具之一。
尽管它本身并不提供任何计算或数据分析工具,它的设计侧重于在交互计算和软件开发两方面将生产力最大化。它使用了一种执行-探索工作流来替代其他语言中典型的编辑-编译-运行工作流。它还提供了针对操作系统命令行和文件系统的易用接口。由于数据分析编码工作包含大量的探索、试验、试错和遍历,IPython可以使你更快速地完成工作。
第五、SciPy
SciPy是科学计算领域针对不同标准问题域的包集合。以下是SciPy中包含的一些包:
①scipy.integrate数值积分例程和微分方程求解器
②scipy.linalg线性代数例程和基于numpy.linalg的矩阵分解
③scipy.optimize函数优化器和求根算法
④scipy.signal信号处理工具
⑤scipy.sparse稀疏矩阵与稀疏线性系统求解器
SciPy与Numpy一起为很多传统科学计算应用提供了一个合理、完整、成熟的计算基础。
第六、scikit-learn
scikit-learn项目诞生于2010年,目前已成为Python编程者首选的机器学习工具包。仅仅七年,scikit-learn就拥有了全世界1500位代码贡献者。其中包含以下子模块:
①分类:SVM、最近邻、随机森林、逻辑回归等
②回归:Lasso、岭回归等
③聚类:K-means、谱聚类等
④降维:PCA、特征选择、矩阵分解等
⑤模型选择:网格搜索、交叉验证、指标矩阵
⑥预处理:特征提取、正态化
scikit-learn与pandas、statsmodels、IPython一起使Python成为高效的数据科学编程语言。
7-5 Python并发网络库常考题
一、你用过哪些并发网络库?
Tornado vs Gevent vs Asyncio
1.Tornado并发网络库和同时也是一个web微框架
2.Gevent绿色线程(greenlet)实现并发,猴子补丁修改内置socket
3.Ayncio Python3内置的并发网络库,基于原生协程
二、Tornado框架
Tornado适用于微服务,实现Restful接口
1.底层基于Linux多路复用
2.可以通过协程或者回调实现异步编程
3.不过生态不完善,相应的异步框架比如ORM不完善
异步编程例子:
import tarnado.ioloop
import tornado.web
from tornado.httpclient import AsyncHTTPClient
class APIHandler(tornado.web.RequestHandler):
async def get(self):
url = 'http://httpbin.org/get'
http_client = AsyncHTTPClient()
resp = await http_client.fetch(url)
print(resp.body)
return resp.body
def make_app():
return tornado.web.Application([
(r'/api', APIHandler),
])
if __name__ == '__main__':
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
运行结果:
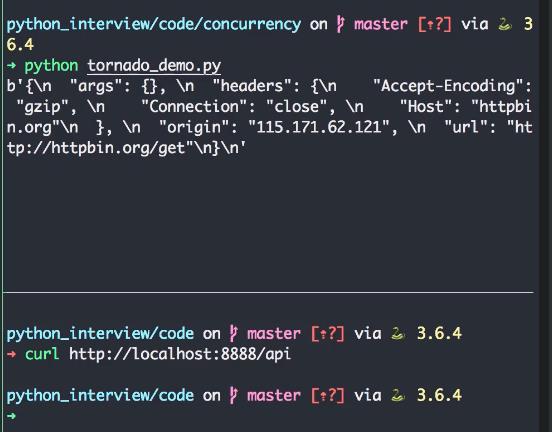
三、Gevent
高性能的并发网络库
1.基于轻量级绿色线程(greenlet)实现并发
2.需要注意monkey patch,gevent修改了内置的socket改为非阻塞
3.配合gunicorn和gevent部署作为wsgi server
《Gevent程序员指南》是学习Gevent的一个比较好的资料
Gevent爬虫示例:
import gevent.monkey
gevent.monkey.patch_all() # 修改内置的一些库为非阻塞
import gevent
import requests
def fetch():
url = 'http://httpbin.org/get'
resp = requests.get(url)
print(len(resp.text), i)
def asynchronous():
threads = []
for i in range(1, 10):
threads.append(gevent.spawn(fetch, i))
gevent.joinall(threads)
print('Asynchronous: ')
asynchronous()
运行结果:
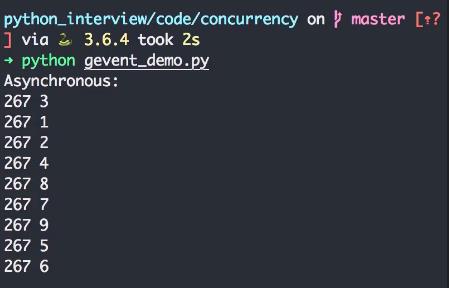
四、Asyncio
基于协程实现的内置并发网络库
1.Python3引入到内置,协程+事件循环
2.生态不够完善,滑大规模生产环境检验
3.目前应用不够广泛,基于Aiohttp可以实现一些小的服务
代码示例:
# 基于 aiohttp 并发请求
import asyncio
from aiohttp import ClientSEssion # pip install aiohttp
async def fetch(url, session):
async with session.get(url) as response:
return await response.read()
async def run(r=10):
url = 'http://httpbin.org/get'
tasks = []
async with ClientSession() as session:
for i in range(r):
task = asyncio.ensure_future(fetch(url, session))
tasks.append(task)
responses = await asyncio.gather(*tasks)
for resp_body in reponses:
print(le(resp_body))
loop = asyncio.get_event_loop()
future = ayncio.ensure_future(run())
loop.run_until_complete(future)
运行结果:
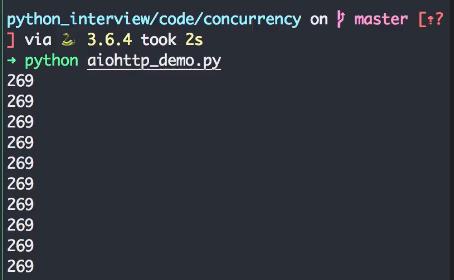
五、本章回顾
TCP; HTTP; socket编程;IO多路复用;并发网线库
1.TCP和HTTP是重点和常考点。善用wireshark/curl/httpie等工具抓包分析请求
2.了解socket编程原理有助于我们理解框架的实现
3.并发网络库底层一般都是基于IO多路复用实现
六、网络编程练习题
编写一个异步爬虫类:使用Python的gevent或者asyncio编写一个异步爬虫类
1.你可以选择使用gevent或者asyncio(推荐),编写一个异步爬虫类
2.要求1:该类可以传入需要抓取的网址列表。
3.要求2:该类可以通过继承的方式提供一个处理response的方法。
以上是关于python常用到哪些库的主要内容,如果未能解决你的问题,请参考以下文章