深拷贝和原型原型链和web api 和 this指向等(中初级前端面事题)持续更新中,建议收藏
Posted 暑假过期le
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深拷贝和原型原型链和web api 和 this指向等(中初级前端面事题)持续更新中,建议收藏相关的知识,希望对你有一定的参考价值。
深拷贝
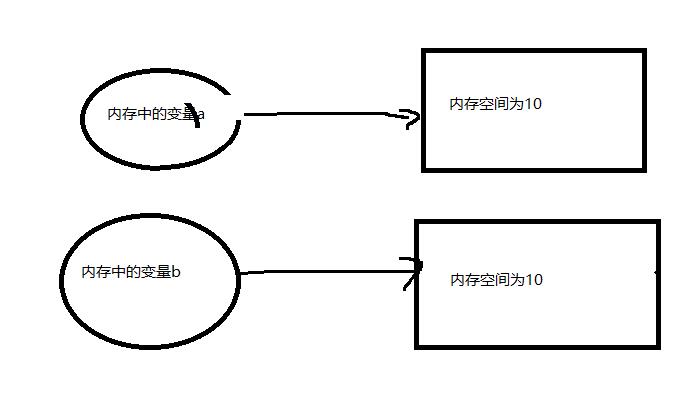
值类型的赋值就是深拷贝:变量赋值时,拷贝的不是内存地址,而是将数据完整的在内存中复制了一份
const a = 10
const b = a
console.log(b);
浅拷贝
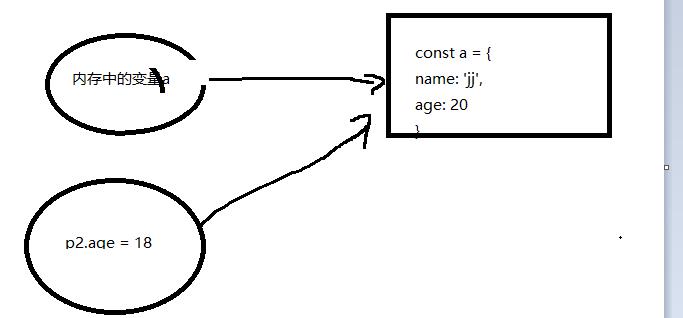
引用类型(null 对象 数组)的赋值操作都不是深拷贝:拷贝的是内存地址,最终两个变量指向的是同一个地址
const a =
name: 'jj',
age: 20
const b = a
b.age = 18
console.log(a.age); // 18
深拷贝和浅拷贝的区别
- 浅拷贝只复制一层对象的属性,而深拷贝则递归复制了所有层级
- 浅拷贝有效性针对的是单一层级对象 [1,2,3]或者a:1,b:2
- 深拷贝有效性针对的是单层或者多层级对象 [1,2,3]或者a:1,b:2或者[1,[1],a:1]或者a:[1],b:c:2
如何让引用类型深拷贝
简单的实现深拷贝
const p1 =
name: 'jj',
age: 20
const deepClone = (obj) =>
let result =
for (let i in obj)
// console.log(obj[i]);
result[i] = obj[i]
return result
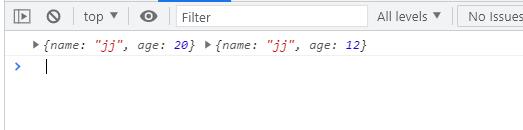
const p2 = deepClone(p1)
p2.age = 12
console.log(p1, p2);
加入递归
const p1 =
name: 'ss',
age: 20,
address:
province: '河北省',
city: '保定市',
area: '莲池区',
info: '河北软件职业技术学院'
const deepClone = (obj) =>
let result =
for (let i in obj)
result[i] = obj[i]
return result
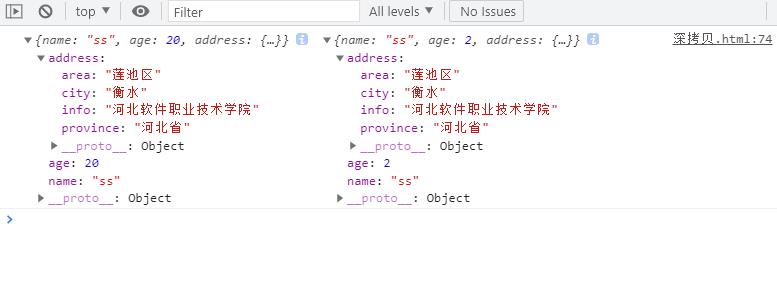
const p2 = deepClone(p1)
p2.age = 2
p2.address.city = '衡水'
console.log(p1, p2);
输出结果
-
对于name和age属性手机深拷贝
-
对于address属性不是深拷贝
-
深拷贝的核心是我没找到对象或数值中的值类型(age 和 name属性的值),然后进行赋值操作,就是深拷贝,而address属性是一个对象自然采用内存地址拷贝
-
解决方案:加入递归,一致递归到值类型为止
-
在deepClone函数中的循环改写为:
result[i]=deepclone(obj[i])
完整代码
const deepClone = (obj) =>
// 如果不是对象或者等于null的时候无需进行深拷贝
if (typeof obj !== 'object' || obj == null)
return obj
//声明变量,用于存储拷贝的数据
let result
if (obj instanceof Array)
result = []
else
result =
for (let i in obj)
// console.log(deepClone(obj[i]));
result[i] = deepClone(obj[i])
return result
const p1 =
name: 'ss',
age: 20,
address:
province: '河北省',
city: '保定市',
area: '莲池区',
info: '河北软件职业技术学院'
const p2 = deepClone(p1)
p2.age = 2
p2.address.city = '衡水'
console.log(p1, p2);
原型和原型链
隐式原型和显示原型
class People
constructor(name)
this.name = name
eat()
console.log('eat');
class Student extends People
constructor(name, number)
super(name)
this.number = number
sayHi()
console.log(`姓名:$this.name,学号:$this.number`);
const xialuo = new Student('夏洛特', '110')
console.log(xialuo.__proto__ === Student.prototype);//true
console.log(xialuo.__proto__);//对象的对象原型,也是隐式原型
console.log(Student.prototype);//类的原型对象,也是显示原型
对象的隐式原型与类的显式原型是同一个对象,内存地址一致
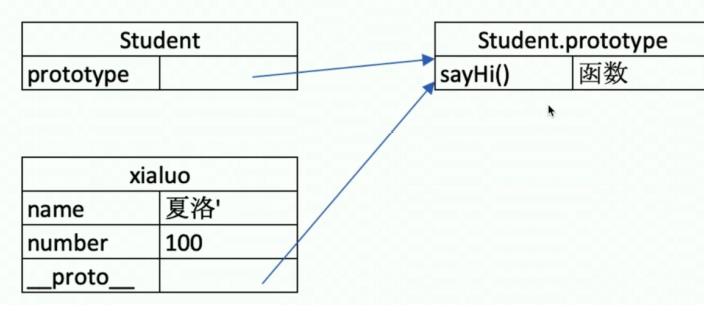
原型关系
- 每个class都有显示原型prototype
- 每个实例都有隐式声明__proto__
- 实例的__proto__指向对应的class的prototype
获取属性方法时
const xialuo = new Student('夏洛特', '110')
console.log(xialuo.name);//夏洛特
xialuo.sayHi()
xialuo.eat()
- 获取属性或方法时,首先在对象的自身属性中查找如上面name就是对象的自身属性
- 如果找不到,则自动取__proto__中查找,如上面的sayHi方法,在对象中并没有,所有取对象的隐式原型上查找
原型链
hasownProperty 方法判断某个属性或者方法是否在当前隐式原型中
在 javascript 中,每个对象都有一个指向它的原型(prototype)对象的内部链接(proto)。这个原型对象又有自己的原型,直到某个对象的原型为 null 为止(也就是不再有原型指向)。这种一级一级的链结构就称为原型链(prototype chain)。 当查找一个对象的属性时,JavaScript 会向上遍历原型链,直到找到给定名称的属性为止;到查找到达原型链的顶部(Object.prototype),仍然没有找到指定的属性,就会返回 undefined。
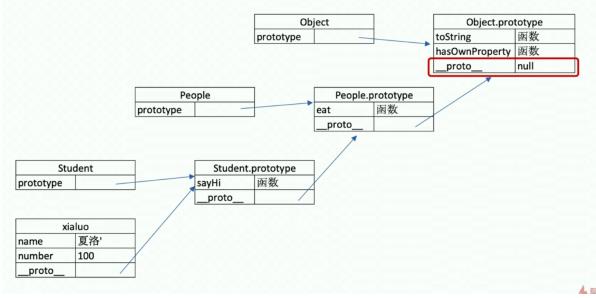
所有 class 都是从 Object 继承的,也就是说 Object 是其他类的原型
作用域
script标签的开始和结束标记之间,叫全局作用域
函数内部的是函数作用域
花括号之间的是块级作用域
自由变量:在当前作用域中没有,在上级找到的变量就是自由变量如果全局没有找到就回报 is not defiend
自由变量的查找就是在函数定义的地方,向上级作用域查找
闭包
在函数调用完之后作用域和变量都被清除
闭包在函数调用之后不会清除作用域和变量,只有调用内部函数的时候才会清除
闭包是一种现象 闭包可以访问其他作用域的变量 有两种情况:1.函数作为返回值 2.函数作为参数
this指向
this 是在函数执行时(调用时)确定的,而不是定义时,
在全局作用域中this是指 window
普通函数this指向
作为普通函数调用this值是window
apply、bind 和 call 方法可以改变普通函数中 this 的指向,传递的第一个参数是什么,则函数中的 this 就是什么
function fn ()
console.log(this);
fn.call( x: 100 ) // x:100
const fn_res = fn.bind( x: 100 )
fn_res() // x:100
定义在对象里面的函数(this指向)
定义在对象里面的函数this指向的是这个对象
const person =
name: 'onlifes',
sayHi ()
console.log(this);
,
wait ()
setTimeout(function ()
console.log(this);
, 0)
person.sayHi()
person.wait()
结果
name: "onlifes", sayHi: ƒ, wait: ƒ
Window
原因:因为 wait 方法中使用了 setTimeOut 函数,其中的函数永远被当作一个普通函数,所以 this=window
箭头函数(this指向)
箭头函数没有自己的this指向,箭头函数的this指向是父级作用域的this指向决定的
class类中方法的this(this指向)
class类中方法的this指向的是声明的对象实例
同步和异步
单线程和异步
JS 是单线程语言,只能同时做一件事,这时候就需要异步解决单线程的问题 异步是解决JS语言单线程瓶颈的一个解决方案
异步和同步的区别
异步是基于 JS 单线程特点而产生的
1.异步不会阻塞代码执行
同步会阻塞代码执行
2.同步就相当于是 当客户端发送请求给服务端,在等待服务端响应的请求时,客户端不做其他的事情。当服务端做完了才返回到客户端。这样的话客户端需要一直等待。用户使用起来会有不友好。
异步就是,当客户端发送给服务端请求时,在等待服务端响应的时候,客户端可以做其他的事情,这样节约了时间,提高了效率。
存在就有其道理 异步虽然好 但是有些问题是要用同步用来解决,比如有些东西我们需要的是拿到返回的数据在进行操作的。这些是异步所无法解决的。
解决异步问题
使用Promise方法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div class="info">
</div>
</body>
</html>
<script>
const url1 =
'https://th.bing.com/th/id/R33674725d9ae34f86e3835ae30b20afe?rik=Pb3C9e5%2b%2b3a9Vw&riu=http%3a%2f%2fwww.desktx.com%2fd%2ffile%2fwallpaper%2fscenery%2f20180626%2f4c8157d07c14a30fd76f9bc110b1314e.jpg&ehk=9tpmnrrRNi0eBGq3CnhwvuU8PPmKuy1Yma0zL%2ba14T0%3d&risl=&pid=ImgRaw'
const url2 = 'https://tse2-mm.cn.bing.net/th/id/OIP.T1-KOJxH7Dg0YqlcZiJ6vAHaHa?pid=ImgDet&rs=1'
const url3 =
'https://th.bing.com/th/id/Rc6c03edea530e9caa677c9d17f193a4d?rik=MBgpsjumbTD5eQ&riu=http%3a%2f%2fwww.desktx.com%2fd%2ffile%2fwallpaper%2fscenery%2f20170209%2fca186d97701674b996264b2d352894a7.jpg&ehk=HunG%2fPF7pUbpcS34cWpNvlS%2faoDPbcaTYL6LFFPQIIM%3d&risl=&pid=ImgRaw'
function loadImg(url)
return new Promise((resolve, reject) =>
const img = document.createElement('img')
img.src = url
img.onload = function ()
resolve(img)
)
loadImg(url1)
.then(img =>
loadInfo(img)
return loadImg(url2)
).then(img =>
loadInfo(img)
return loadImg(url3)
).then(img =>
loadInfo(img)
)
function loadInfo(ele)
const sp = document.createElement('span')
sp.innerHTML = ele.width
document.querySelector('.info').appendChild(sp)
document.body.appendChild(ele)
</script>
用 await方法改造
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div class="info">
</div>
</body>
</html>
<script>
const url1 =
'https://th.bing.com/th/id/R33674725d9ae34f86e3835ae30b20afe?rik=Pb3C9e5%2b%2b3a9Vw&riu=http%3a%2f%2fwww.desktx.com%2fd%2ffile%2fwallpaper%2fscenery%2f20180626%2f4c8157d07c14a30fd76f9bc110b1314e.jpg&ehk=9tpmnrrRNi0eBGq3CnhwvuU8PPmKuy1Yma0zL%2ba14T0%3d&risl=&pid=ImgRaw'
const url2 = 'https://tse2-mm.cn.bing.net/th/id/OIP.T1-KOJxH7Dg0YqlcZiJ6vAHaHa?pid=ImgDet&rs=1'
const url3 =
'https://th.bing.com/th/id/Rc6c03edea530e9caa677c9d17f193a4d?rik=MBgpsjumbTD5eQ&riu=http%3a%2f%2fwww.desktx.com%2fd%2ffile%2fwallpaper%2fscenery%2f20170209%2fca186d97701674b996264b2d352894a7.jpg&ehk=HunG%2fPF7pUbpcS34cWpNvlS%2faoDPbcaTYL6LFFPQIIM%3d&risl=&pid=ImgRaw'
function loadImg(url)
return new Promise((resolve, reject) =>
const img = document.createElement('img')
img.src = url
img.onload = function ()
resolve(img)
)
async function fn()
loadInfo(await loadImg(url1))
loadInfo(await loadImg(url2))
loadInfo(await loadImg(url3))
fn()
function loadInfo(ele)
const sp = document.createElement('span')
sp.innerHTML = ele.width
document.querySelector('.info').appendChild(sp)
document.body.appendChild(ele)
</script>
web api
- ECMA 和 W3C 是两个机构,但这两个机构的会员有很大重合
- ECMA 规定 ECMAScript 的标准,W3C 规定了 Web API 的标准,也就是说 ECMA 负责 ECMAScript 脚本语言的研究和发布,W3C 定义了 ECMAScript 能做什么
- ECMA 262 是基础,与 Web API 结合才能发挥作用
DOM操作
dom的本质是什么
我们都知道,DOM 是一棵树。梨树还是桃树?
首先要明白,通过 VS Code 编辑的 HTML 源代码,最终会被浏览器拿到 浏览器拿到源代码经过解析,构建成DOM树,浏览器可以识别并通过JS可以操作的这个DOM树 所以,要将源代码与 DOM 区别开来
- 源代码是开发者编写的,由浏览器进行解析并渲染成页面,但渲染完成后,无法通过 JS 进行修改
- DOM 存在于浏览器的内存中(我自己的理解),通过 JS 可以修改,修改后,浏览器会根据修改后 的 DOM 树重新渲染页面
DOM节点操作
- property :修改对象属性,不会体现到 HTML 结构中
- attribute:修改 html 结构,会改变 HTML 结构
- 两者都可能引起 DOM 结构重新渲染
// property 方式:
element.style.color='red'
element.className='blue'
// atribute 方式
element.setAttribute('class','blue')
element.getAttribute('href')
结论:尽量使用 property 的方式,万不得已,再使用 attribute 方式
DOM 结构操作
- 新增,插入节点
- 获取子元素列表,获取父元素
- 删除元素
新增节点
document.createElement('p')
插入节点
父节点.appendChild('p')
获取子元素列表
父元素.childNodes
获取父元素列表
子元素.parentNode
删除子元素
父元素.removeChild(子元素)
DOM性能优化
- 对DOM查询做缓存
- 将频繁的DOM操作作为一次性操作
用代码片段进行一次性的操作
body
<ul id="list"></ul>
//js
const listNode = document.getElementById("list")
// 创建一个文档片段,此时还没有插入到DOM树中
const frag = document.createDocumentFragment()
// 执行插入
for (let x = 0; x < 10; x++)
const li = document.createElement('li')
li.innerHTML = "list item " + x
frag.appendChild(li)
// 完成之后,再插入到DOM树中
listNode.appendChild(frag)
BOM操作
BOM:浏览器对象模型
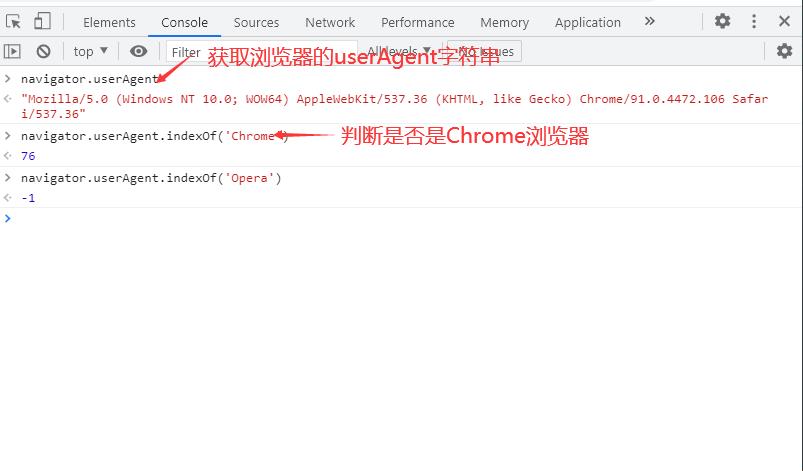
1.如何识别浏览器类型
用Navigator对象的
| 属性 | 说明 |
|---|---|
| appCodeName | 返回浏览器的代码名 |
| appName | 返回浏览器的名称 |
| appVersion | 返回浏览器的平台和版本信息 |
| cookieEnabled | 返回指明浏览器中是否启用 cookie 的布尔值 |
| platform | 返回运行浏览器的操作系统平台 |
| userAgent | 返回由客户机发送服务器的user-agent 头部的值 |
分析拆解 URI 各个部分

Screen 对象
Screen 对象包含有关客户端显示屏幕的信息。
| 属性 | 描述 |
|---|---|
| availHeight | 返回显示屏幕的高度 (除 Windows 任务栏之外)。 |
| availWidth | 返回显示屏幕的宽度 (除 Windows 任务栏之外)。 |
| bufferDepth | 设置或返回调色板的比特深度。 |
| colorDepth | 返回目标设备或缓冲器上的调色板的比特深度。 |
| deviceXDPI | 返回显示屏幕的每英寸水平点数。 |
| deviceYDPI | 返回显示屏幕的每英寸垂直点数。 |
| fontSmoothingEnabled | 返回用户是否在显示控制面板中启用了字体平滑。 |
| height | 返回显示屏幕的高度。 |
| logicalXDPI | 返回显示屏幕每英寸的水平方向的常规点数。 |
| logicalYDPI | 返回显示屏幕每英寸的垂直方向的常规点数。 |
| pixelDepth | 返回显示屏幕的颜色分辨率(比特每像素)。 |
| updateInterval | 设置或返回屏幕的刷新率。 |
| width | 返回显示器屏幕的宽度。 |
History 对象
History 对象包含用户(在浏览器窗口中)访问过的 URL
History 对象属性
| 属性 | 描述 |
|---|---|
| length | 返回浏览器历史列表中的 URL 数量。 |
History 对象方法
| 方法 | 描述 |
|---|---|
| back() | 加载 history 列表中的前一个 URL。 |
| forward() | 加载 history 列表中的下一个 URL。 |
| go() | 加载 history 列表中的某个具体页面。 |
事件
事件绑定
1.嵌入式
<button onclick="open()">按钮</button>
<script>
function open()
alert(1)
</script>
2.事件监听
<button id="btn">按钮</button>
<script>
document.getElementById('btn').addEventListener('click',function()
alert(1)
)
</script>
3.直接绑定
<button id="btn">按钮</button>
<script>
document.getElementById('btn').onclick = function()
alert(1)
</script>
addEventListener和on的区别
on:如果事件相同就会覆盖前一个但是有时我们又需要执行多个相同的事件 on就完成不了我们想要的效果
addEventListener:可以多次绑定同一个事件并且不会覆盖上一个事件。
事件代理
**事件代理:**将事件代理到父容器上,这样修改子元素,父容器都会监听到,从而执行对应的操作,若是将事件绑定到子元素上,假设新增了子元素,又得重新给子元素绑定事件,是非常繁琐的。
事件冒泡,事件捕获
<div>
<p>元素</p>
</div>
事件捕获
当你使用事件捕获时,父级元素先触发,子级元素后触发,即div先触发,p后触发。
事件冒泡
当你使用事件冒泡时,子级元素先触发,父级元素后触发,即p先触发,div后触发。
组织冒泡的方法
第一种:event.stopPropagation();
第二种:return false;
第三种:event.preventDefault();
webpack
是一个打包工具,模块化减少http请求,使新标准能够兼容旧版本
linux 常用命令
随便找个终端
ssh root@IP地址
回车后输入密码,就可以登录了
目录的增删改查
创建目录【增】 mkdir
命令:mkdir 目录
mkdir aaa 在当前目录下创建一个名为aaa的目录
mkdir /usr/aaa 在指定目录下创建一个名为aaa的目录
删除目录或文件【删】rm
命令:rm [-rf] 目录
删除文件:
rm 文件 删除当前目录下的文件
rm -f 文件 删除当前目录的的文件(不询问)
删除目录:
rm -r aaa 递归删除当前目录下的aaa目录
rm -rf aaa 递归删除当前目录下的aaa目录(不询问)
全部删除:
rm -rf * 将当前目录下的所有目录和文件全部删除
rm -rf /* 【自杀命令!慎用!慎用!慎用!】将根目录下的所有文件全部删除
注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了方便大家的记忆,无论删除任何目录或文件,都直接使用 rm -rf 目录/文件/压缩包
目录修改【改】mv 和 cp
一、重命名目录
命令:mv 当前目录 新目录
例如:mv aaa bbb 将目录aaa改为bbb
注意:mv的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作
二、剪切目录
命令:mv 目录名称 目录的新位置
示例:将/usr/tmp目录下的aaa目录剪切到 /usr目录下面 mv /usr/tmp/aaa /usr
注意:mv语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作
三、拷贝目录
命令:cp -r 目录名称 目录拷贝的目标位置 -r代表递归
示例:将/usr/tmp目录下的aaa目录复制到 /usr目录下面 cp /usr/tmp/aaa /usr
注意:cp命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r递归
搜索目录【查】find
命令:find 目录 参数 文件名称
示例:find /usr/tmp -name ‘a*’ 查找/usr/tmp目录下的所有以a开头的目录或文件
目录和文件的移动
linux中的移动使用mv指令。
- 移动文件
单纯地移动某一个文件直接使用:mv <源文件名称/地址> <新文件名称/地址>,
可以看出,这个方法也可以用来修改文件的名称。
2.移动文件夹(目录)以及文件夹下的内容
如果要移动文件夹的内容以及文件夹本身:mv <目录地址1 > <目录地址2/>,即文件夹目录地址后面加上/即可!
页面加载过程
从输入 url 到渲染出整个页面的过程
- DNS 解析:域名=>IP地址
- 浏览器根据 IP 地址向服务器发起 http/https 请求
- 请求的是资源(html文件、css文件、js文件、媒体文件),一般服务器直接返回
- 请求的是虚拟路径,比如某个 API,服务器会动态生成数据并返回
- 浏览器根据服务器返回的 HTML 生成 DOM Tree
- 浏览器根据服务器返回的 CSS 生成 CSSOM
- 浏览器将 DOM Tree 和 CSSOM 整合成 Render Tree
- 根据 Render Tree 渲染页面
- 渲染过程中用到 script 则暂停渲染,优先加载并执行 JS,完成后再继续
window.onload 和 DOMContentLoaded 的区别
- window.onload 等资源全部加载完后才执行,资源也包括图片
- DOMContentLoaded :DOM 渲染完成即可,图片可能尚未加载
前端性能优化
原则
- 多使用内存,缓存(以空间换时间,这种思想也适用于后台)访问频繁,变化不大
- 减少CPU计算量,减少网络加载耗时
方法
提升加载速度:
- 减少资源体积:webback压缩代码减少代码体积
- 减少访问次数:合并代码,ssr服务段渲染,缓存等(精灵图)
- 使用更快的网络请求:cdn
- css放在head,js放在body最下面
- 尽早开始执行js,用DOMContentLoaded触发
- 懒加载
提升渲染速度
-
对DOM查询进行缓存
-
拼单DOM操作,合并到一起插入DOM结构 片段:
document.createDocumentFragment() -
节流throttle和防抖debounce
防抖(debounce):触发高频事件后n秒内函数只会执行一次,如果n秒内高频事件再次被触发,则重新计算
节流(thorttle):高频事件触发,但在n秒内只会执行一次,所以节流会西施函数的执行频率
区别:防抖动是将多次执行变为最后一次执行,节流是将多次执行变成每隔一段时间执行。
以上是关于深拷贝和原型原型链和web api 和 this指向等(中初级前端面事题)持续更新中,建议收藏的主要内容,如果未能解决你的问题,请参考以下文章