如果测试中某个测试点的信号异常,如何判断故障点在哪
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如果测试中某个测试点的信号异常,如何判断故障点在哪相关的知识,希望对你有一定的参考价值。
测试环境中出现了一个异常的告警现象:一条告警通过 Thanos Ruler 的 HTTP 接口观察到持续处于 active 状态,但是从 AlertManager 这边看这条告警为已解决状态。按照 DMP 平台的设计,告警已解决指的是告警上设置的结束时间已经过了当前时间。一条发送至 AlertManager 的告警为已解决状态有三种可能:1. 手动解决了告警2. 告警只产生了一次,第二次计算告警规则时会发送一个已解决的告警3. AlertManager 接收到的告警会带着一个自动解决时间,如果还没到达自动解决时间,则将该时间重置为 24h 后首先,因为了解到测试环境没有手动解决过异常告警,排除第一条;其次,由于该告警持续处于 active 状态,所以不会是因为告警只产生了一次而接收到已解决状态的告警,排除第二条;最后,告警的告警的产生时间与自动解决时间相差不是 24h,排除第三条。那问题出在什么地方呢?
分析
下面我们开始分析这个问题。综合第一节的描述,初步的猜想是告警在到达 AlertManager 前的某些阶段的处理过程太长,导致告警到达 AlertManager 后就已经过了自动解决时间。我们从分析平台里一条告警的流转过程入手,找出告警在哪个处理阶段耗时过长。首先,一条告警的产生需要两方面的配合:
metric 数据
告警规则
将 metric 数据输入到告警规则进行计算,如果符合条件则产生告警。DMP 平台集成了 Thanos 的相关组件,数据的提供和计算则会分开,数据还是由 Prometheus Server 提供,而告警规则的计算则交由 Thanos Rule(下文简称 Ruler)处理。下图是 Ruler 组件在集群中所处的位置:
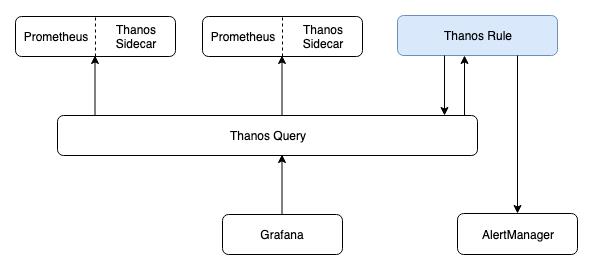
看来,想要弄清楚现告警的产生到 AlertManager 之间的过程,需要先弄清除 Ruler 的大致机制。官方文档对 Ruler 的介绍是:You can think of Rule as a simplified Prometheus that does not require a sidecar and does not scrape and do PromQL evaluation (no QueryAPI)。
不难推测,Ruler 应该是在 Prometheus 上封装了一层,并提供一些额外的功能。通过翻阅资料大致了解,Ruler 使用 Prometheus 提供的库计算告警规则,并提供一些额外的功能。下面是 Ruler 中告警流转过程:
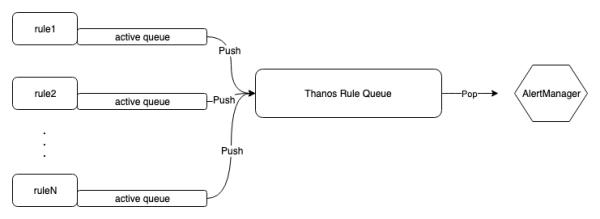
请点击输入图片描述
首先,图中每个告警规则 Rule 都有一个 active queue(下面简称本地队列),用来保存一个告警规则下的活跃告警。
其次,从本地队列中取出告警,发送至 AlertManager 前,会被放入 Thanos Rule Queue(下面简称缓冲队列),该缓冲队列有两个属性:
capacity(默认值为 10000):控制缓冲队列的大小,
maxBatchSize(默认值为 100):控制单次发送到 AlertManager 的最大告警数
了解了上述过程,再通过翻阅 Ruler 源码发现,一条告警在放入缓冲队列前,会为其设置一个默认的自动解决时间(当前时间 + 3m),这里是影响告警自动解决的开始时间,在这以后,有两个阶段可能影响告警的处理:1. 缓冲队列阶段2. 出缓冲队列到 AlertManager 阶段(网络延迟影响)由于测试环境是局域网环境,并且也没在环境上发现网络相关的问题,我们初步排除第二个阶段的影响,下面我们将注意力放在缓冲队列上。通过相关源码发现,告警在缓冲队列中的处理过程大致如下:如果本地队列中存在一条告警,其上次发送之间距离现在超过了 1m(默认值,可修改),则将该告警放入缓冲队列,并从缓冲队列中推送最多 maxBatchSize 个告警发送至 AlertManager。反之,如果所有本地队列中的告警,在最近 1m 内都有发送过,那么就不会推送缓冲队列中的告警。也就是说,如果在一段时间内,产生了大量重复的告警,缓冲队列的推送频率会下降。队列的生产方太多,消费方太少,该队列中的告警就会产生堆积的现象。因此我们不难猜测,问题原因很可能是是缓冲队列推送频率变低的情况下,单次推送的告警数量太少,导致缓冲队列堆积。下面我们通过两个方面验证上述猜想:首先通过日志可以得到队列在大约 20000s 内推送了大约 2000 次,即平均 10s 推送一次。结合缓冲队列的具体属性,一条存在于队列中的告警大约需要 (capacity/maxBatchSize)*10s = 16m,AlertManager 在接收到告警后早已超过了默认的自动解决时间(3m)。其次,Ruler 提供了 3 个 metric 的值来监控缓冲队列的运行情况:
thanos_alert_queue_alerts_dropped_total
thanos_alert_queue_alerts_pushed_total
thanos_alert_queue_alerts_popped_total
通过观察 thanos_alert_queue_alerts_dropped_total 的值,看到存在告警丢失的总数,也能佐证了缓冲队列在某些时刻存在已满的情况。
解决通过以上的分析,我们基本确定了问题的根源:Ruler 组件内置的缓冲队列堆积造成了告警发送的延迟。针对这个问题,我们选择调整队列的 maxBatchSize 值。下面介绍一下这个值如何设置的思路。由于每计算一次告警规则就会尝试推送一次缓冲队列,我们通过估计一个告警数量的最大值,得到 maxBatchSize 可以设置的最小值。假设你的业务系统需要监控的实体数量分别为 x1、x2、x3、...、xn,实体上的告警规则数量分别有 y1、y2、y3、...、yn,那么一次能产生的告警数量最多是(x1 * y2 + x2 * y2 + x3 * y3 + ... + xn * yn),最多推送(y1 + y2 + y3 + ... + yn)次,所以要使缓冲队列不堆积,maxBatchSize 应该满足:maxBatchSize >= (x1 * y2 + x2 * y2 + x3 * y3 + ... + xn * yn) / (y1 + y2 + y3 + ... + yn),假设 x = max(x1,x2, ...,xn), 将不等式右边适当放大后为 x,即 maxBatchSize 的最小值为 x。也就是说,可以将 maxBatchSize 设置为系统中数量最大的那一类监控实体,对于 DMP 平台,一般来说是 mysql 实例。
注意事项
上面的计算过程只是提供一个参考思路,如果最终计算出该值过大,很有可能对 AlertManager 造成压力,因而失去缓冲队列的作用,所以还是需要结合实际情况,具体分析。因为 DMP 将 Ruler 集成到了自己的组件中,所以可以比较方便地对这个值进行修改。如果是依照官方文档的介绍使用的 Ruler 组件,那么需要对源码文件进行定制化修改。
下面我分别来说一下如何确定故障点。
首先,开机听一下有没有主板发出的“滴”一声(大约在主机接通电源5-6秒钟发出),这是主板自检声,如果有这一声,说明:内存、主板或CPU正常。那么就是VGA信号线或显卡的故障了,然后换根VGA线(保证是好的,换之前先把自己的线的所有接头重新插一下,确定不是接头接触不良导致的),如果确认插接没问题的情况下,还是不好,那么说明是显卡问题,你再把显卡拔下来,用橡皮擦一擦“金手指”再插上,看看怎么样,在确定所有插接都没问题的情况下,故障如果依旧,那么就是显卡坏了;
回到前面,如果开机没有听到“滴”的一声自检声,那么,下面你首先将内存拔下来,用橡皮擦一擦“金手指”再插上,用干刷子清理一下主板等各部件上的积尘(各插槽为清理重点),做完这一步,开机,如果故障依旧,那么下一步,你拔下内存,启动机器(让机器不带内存启动),如果,出现内存故障报警声(不同Bios芯片的报警声不同:Award的就是不断地长响、AMI的是1长3短……还有其他的,可以根据你的BIOS芯片的类型上网查一下)那么说明主板或CPU是好的;如果,拔下内存来启动也是没有报警声,基本上可以判断为主板故障了。
以上是一些基本的判断方法,不排除有特殊情况,因为你描述的故障细节不清楚,也没法亲手检测你的机器,只能这样大体给你说一下,你先试试吧。本回答被提问者采纳
异常测试-中间件故障演练
前言
多年前入职了现在的公司,当时还没有完整的异常测试的体系,后来根据自己的经验结合现状,帮助公司建立了一套异常测试的流程和文档,和另外的同学一起设计了异常故障注入平台,也完成了一些演练的落地,在这里做一些总结。
kv故障演练
kv即key-value数据库,业界普遍使用的有redis、zookeeper等,和关系型数据库如mysql相比一般只提供对key的CRUD等的简单操作,读写速度却快很多。
kv在我们现在的系统中有几种使用用途:
- 用于缓存数据,将数据库的数据缓存到kv里,减轻大量查询对数据库访问的压力
- 用于临时数据的存储,比如锁、登陆态、记数器等
由于之前线上出现过因为kv异常导致整体业务不可用的问题,所以需要对所有使用kv的场景进行排查,确认是否是强依赖、是否能够降级,最终做到kv故障也不会影响核心业务的运行。
场景分析
在场景分析阶段,需要拉各业务线统一进行分析和梳理,确认各业务和应用在哪些场景和哪些接口逻辑里面有调用到kv,是否有降级,进行梳理和记录。
可以简单按这个方式登记下:
| 业务线 | 依赖kv的场景 | 是否有降级或者处理异常 |
| x x x |x x x | x x x |
在记录之后,需要审视和评估,这些使用到kv的地方是否合理,是否能做降级,比如:
- 查询kv失败,如果数据存储在db是否可以降级为查db;
- 核心流程里面加锁解锁访问kv失败,到底应该忽略错误让业务进行下去还是抛异常中断流程或是做其他异常处理,需要进行权衡、谨慎判断
在这过程中发现的问题可以提前进行优化,避免到了实际演练的时候出现太多的阻塞问题
确认用例&制定计划
根据之前的分析,整理出了各业务涉及kv的场景和用例,但仅仅有这些是不够的。做kv故障演练的根本目的还是保证核心主流程在kv异常时还能够正常运行,所以演练的用例还是要以核心主流程为基础。另一方面,随着系统复杂度的提高,业务方互相调用错综复杂,以业务方为纬度的梳理往往不够全面,比如业务方A没有调用kv的场景,但A的主流程会调用业务方B的接口,而该业务方B的接口的是个不太重要的功能但依赖了kv,可能就会被遗漏。
这样的问题适合在演练的时候发现,这实际上也是种集成的概念:各业务单元先保证自己对kv的依赖和处理是合理的,然后集成在一起,通过演练确保整体业务是健壮的。
于是我们可以根据核心主流程和依赖kv的场景输出演练时候的用例。有了场景和用例,可以制定相关的演练计划。考虑到业务之间存在依赖,比如只有账号功能正常了,才能登陆后做后续的操作;只有支付功能正常,才能下单走交易流程。所以在执行上需要安排基础业务方先行进行操作和验证,没有问题后再安排后续业务方进行验证。
最后,一个完整的演练计划包括这么几个步骤:
- 起始时间和各阶段的时间。因为故障演练一般在测试环境进行,会影响其他人的使用,所以时间选择需要避开高峰时间段同时控制时长,并提前通知。
- 执行故障。需要提前和运维或者kv维护人员沟通,安排人进行故障注入操作。
- 执行降级。有些降级需要手动执行,需要加入计划中,注明操作项和操作人,只有确保降级成功后再开始后续验证。
- 业务回归。先让基础业务方进行回归,再安排上层业务方参与。
- 问题排查和记录,对于发现的问题统一进行记录。
- 故障恢复。恢复故障后,各业务方确认业务是否都恢复正常。
- 分析汇总结果。对于执行失败的case和发现的问题,进行记录和补充原因,需要进行后续排查、优化的给出后续计划和时间点。
执行演练
按照之前的计划执行演练,最好将参与演练的开发和测试都安排在大会议室方便交流和问题排查。
先找人对kv注入故障,比如停掉服务,然后通知需要手动降级的业务方开始操作降级。降级完成后,让基础业务方先行进行验证,没有问题则通知上层业务方开始介入进行功能回归。
期间可能需要协调不同业务方去排查互相调用时出现的问题。
最后,等各业务方都确认用例执行完成,则可以恢复环境。
记录和分析结果
对于执行过程中的失败,需要详细记录失败场景、报错日志等信息,帮助开发排查问题,也方便自己下次进行回归验证。
演练结束后,对失败的原因进行分析,并给出后续的action。
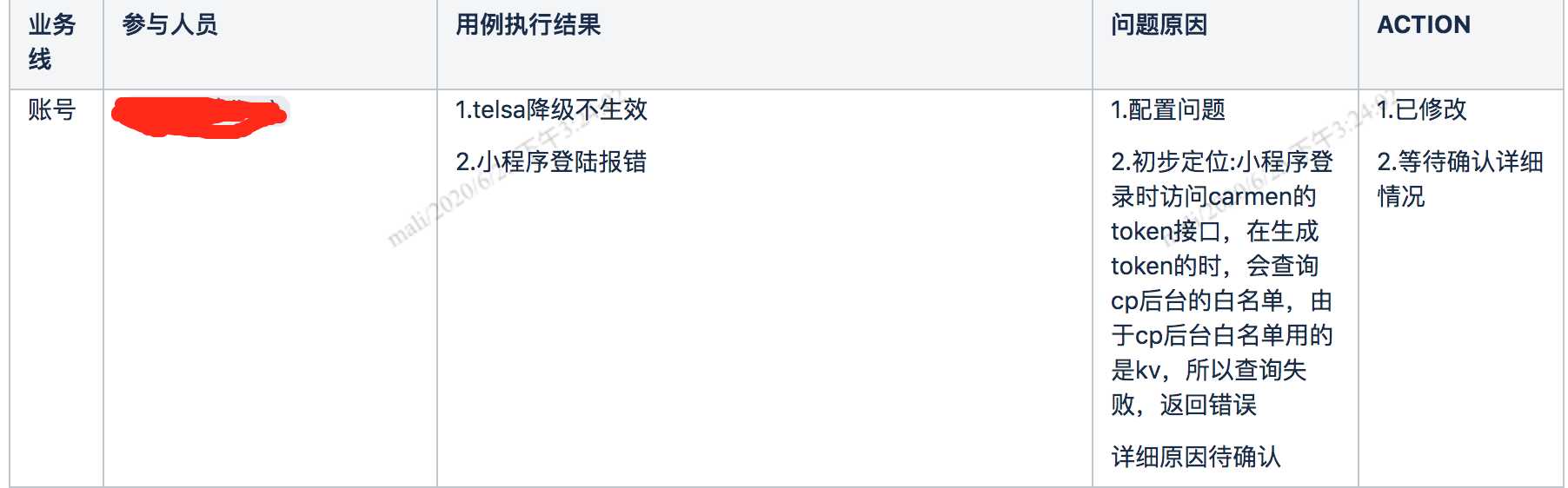
作为演练的负责人,需要不定期的跟进action的完成情况,督促业务方尽快进行优化改进,等上一次演练发现的问题解决的差不多了,就可以开启新一轮的演练。
一般情况下,如果这次是第一次做故障演练,对于整体功能的可用性就不能抱有太大期望,可能在基础业务方这层就会存在问题,导致上层业务无法正常运行。
但是不必气馁,演练就是个需要不断迭代改进和巩固的过程,之前演练了2-3次之后,整体的流程基本上就能跑下来了。看到系统不断的变健壮,还是很有成就感的。
降级演练
双11期间,系统往往会遭遇大流量的洗礼,作为质量保障的一环,需要对系统自动降级和过载保护的有效性进行验证。所以组织了针对性的一次验证和演练。
用例设计
降级
执行方式:接口接入自动降级组件,构造请求,触发配置的规则
关注点:
1.规则是否生效(超时/失败等)
2.降级行为是否符合预期,如返回默认数据或错误,
3.降级期间业务功能是否正常
4.解除异常,降级行为是否能够自动恢复
5.可能的话关注下降级切换花费的时间以及切换过程中的失败率
限流
执行方式:接口接入过载保护组件,构造流量进行加压
关注点:
1.流量超过限制,是否触发限流
2.限流行为是否符合预期
3.流量降低,业务是否恢复正常
热点缓存
执行方式:接口接入过载保护组件,构造流量进行加压
关注点:
1.出现热点商品是否触发过载保护,将热点商品加载到localcache
2.流量降低,业务是否恢复正常模式
测试策略与执行
接口级别验证->功能级别验证
先针对单接口,验证接入组件是否生效。此时可以在降级和过载保护组件里配置强制开启降级,通过简单的接口调用直接触发降级和过载保护,验证处理结果是否符合预期。在这个层次上主要发现降级是否生效,处理逻辑是否正常的问题。
然后根据功能场景,构造流量进行降级和过载的验证。通过不断加压,让流量达到配置的阈值,观察系统是否自动开启了降级和过载保护,持续一段时间,然后观察接口返货、系统响应是否正常,系统状态和日志输出是否正常,然后慢慢降低流量,观察系统是否能够恢复正常。这这个层次上主要发现降级和过载配置合理性的问题以及性能上的问题。
分析总结
对于发现的问题进行分析和总结,推动开发进行优化和改进。
执行单独的降级和过载保护的验证解决的是有无保护的问题,一些配置参数配置是否合理往往需要结合全链路压测的时候来一起进行分析判断。
后记
之前参与主导和编写了公司的测试白皮书,今年出了电子版。有兴趣的朋友可以交流学习下:
https://shop13579785.youzan.com/wscvis/course/detail/2ocqwv300c8oh
以上是关于如果测试中某个测试点的信号异常,如何判断故障点在哪的主要内容,如果未能解决你的问题,请参考以下文章