Spark远程调试+页面监控--用最熟悉的方式开发Spark应用
Posted roykingw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark远程调试+页面监控--用最熟悉的方式开发Spark应用相关的知识,希望对你有一定的参考价值。
大家好。 我是楼兰,持续分享最纯粹的技术内容。
大数据技术已经大行其道,但是很多人对大数据组件依然会觉得很陌生,很不顺手。对大部分人来说,环境部署、API使用其实问题都不大,技术人员最不欠缺的就是学习能力。而陌生的根源就在于这些远程执行的代码很难像本地应用一样进行靠谱的调试。并且这些远程组件又很难像我们熟悉的数据库之类的产品一样集成进来。这里就简单总结一下Spark的远程调试以及应用监控的思路,让Spark不再那么陌生。
一、Java应用远程调试
以往我们开发熟悉的J2EE应用,在本地开发调试好了之后,放到服务器上运行效果差别一般不会太大,所以我们也习惯了这种本地调试,服务端运行的开发模式。但是在大数据场景下,MapReduce计算,Spark计算等这些大型的计算,就很难使用这种熟悉的开发模式了。虽然MapReduce,Spark都提供了Local的运行模式,可以在本地运行。但是当计算规模比较大,计算任务比较复杂时,本地调试就显得有点捉襟见肘了。本地调试完美的应用,放到集群上,往往漏洞百出,这也让很多人头疼不已。
这时,就可以引入远程调试模式,让程序在远程Spark集群上运行,而在本地IDEA中打断点调试。用我们熟悉的方式开发,并且在真实环境中验证,这样就回到了我们熟悉的开发模式。
步骤也不复杂,但是非常实用。秘密就在最常用的JDK中。Java提供了JDWP远程调试机制,可以对远程应用进行本地调试。JDWP全称Java Debug Wire Protocol,是JAVA提供的一个非常有用的功能。像Hadoop的MapReduce计算,Spark计算这些基于JVM的应用程序,都可以进行远程调试。大大释放本地资源。
接下来使用JDK1.8版本 , spark-3.1.1-bin-hadoop3.2版本 和 IDEA 2021.1.3旗舰版一起来尝试一下远程调试功能把。
二、Spark集群中提交任务
1、普通提交方式
正常任务提交方式会通过Spark提供的spark-submit脚本进行提交。需要一大堆的参数,记不住怎么办?直接执行脚本就行了。他会给你足够的提示。

按照提示,将任务打成jar包后就可以往Spark集群中提交了。
/app/spark/spark-3.1.1-bin-hadoop3.2/bin/spark-submit --class com.roy.personaeng.etl.DataToJsonJob --master yarn /app/hspersona/engine/HsPersonaEng.jar ID2112131310569166728092638 admin /data/admin/hspersona/DS ID2112131310569166728092638 /
其中 --class指定任务启动类,也就是main方法所在的类。–master 指定为yarn,表示交由hadoop的yarn来进行资源管理。然后后面的几个参数代表任务所在的jar包,以及任务执行时的参数,这些参数就是任务启动类的main方法接收到的参数。
2、带远程监听的提交方式
如果正常提交任务,那任务在提交之后就会直接在spark集群中运行起来了,这样是无法进行断点调试的。这时,可以使用JVM提供的远程调试功能,让Spark程序乖乖的听话。
/app/spark/spark-3.1.1-bin-hadoop3.2/bin/spark-submit --class com.roy.personaeng.etl.DataToJsonJob --master yarn --driver-java-options "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5005" /app/hspersona/engine/HsPersonaEng.jar ID2112131310569166728092638 admin /data/admin/hspersona/DS ID2112131310569166728092638 /
其中主要是增加了几个JVM的参数,-Xdebug表示启用调试特性。-Xrunjdwp表示启用JDWP。配置时给JDWP增加了几个子选项:
-
transport=dt_socket:这表示Java前端和后端之间的传输方法。dt_socket表示使用套接字传输。
-
address=8888:这表示JVM在8888端口上监听请求。
-
server=y:y表示启动的JVM是被调试者。如果为n,则表示启动的JVM是调试器。
-
suspend=y:y表示启动的JVM会暂停等待,直到调试器连接上才继续执行。suspend=n,则JVM不会暂停等待。
带上这几个JVM参数后提交任务,任务将会在刚开始的时候阻塞住,等待开启监听。

这时应用会等待IDEA发起监听。下面就需要在IDEA中开启监听程序,任务才会继续往下执行。
三、IDEA中配置远程监听端口
回到IDEA项目中,首选需要配置一个远程执行任务
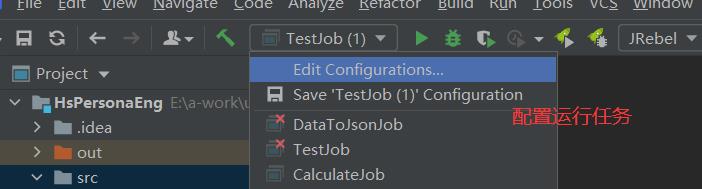
在打开的窗口中配置一个Remote JVM Debug执行任务,指向远程服务端的监听端口。

接下来在本地任务中提前打好断点,就可以用Debug指令启动调试了。
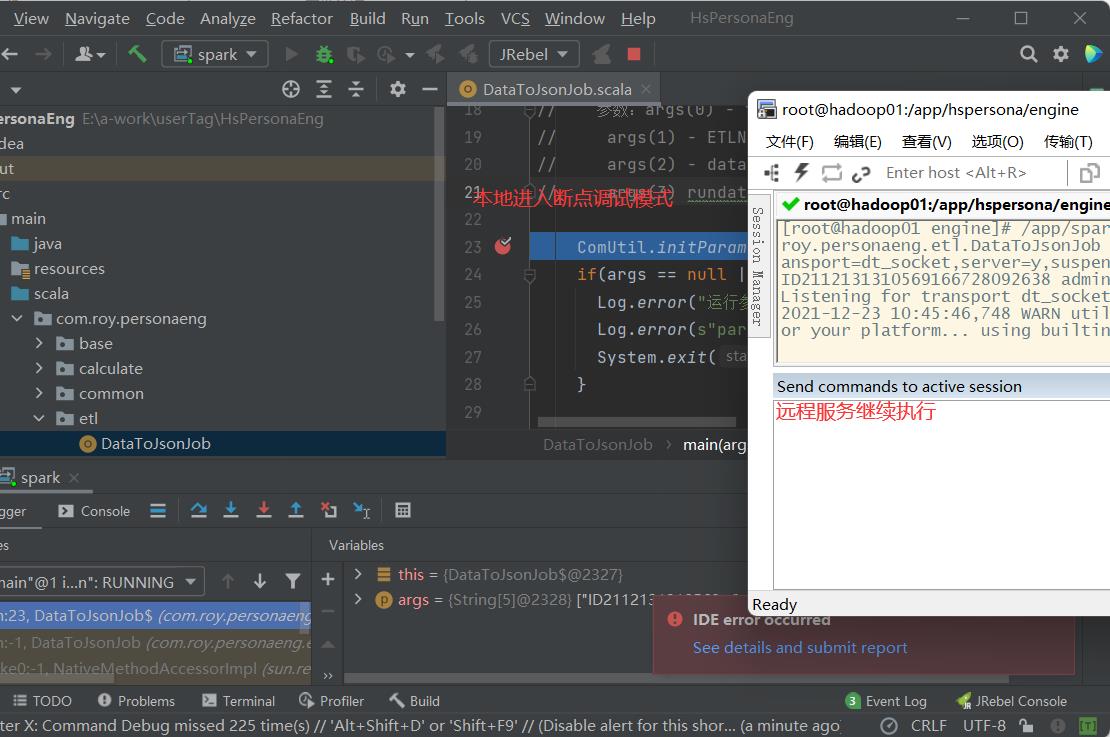
接下来就可以像调试本地代码一样一行行进行调试了。
四、应用中如何监控Spark任务执行情况
解决了第一个开发的陌生感问题,接下来就是结果验证了。我们去访问一些熟悉的远程功能组件,比如数据库,都可以立即拿到结果,所以我们在开发应用时,可以很方便的做出很多监控程序,在应用中直接跟踪指令执行结果。
但是使用Spark后,情况就不太妙了。如何在应用中启动Spark的应用程序并监控Spark任务执行情况呢?
Spark应用出问题的地方太多了,如果只是拿到计算任务的执行结果是成功还是失败,那几乎没有任务作用。程序抛出的异常对于问题排查也几乎起不到任何帮助。只能从运行日志中观察。但是运行日志是在命令行展开的,难道要我蹩脚的去查应用日志文件?
No,No,No.内心强大的程序员自然有更妙的技术设计(偷懒工具)。于是我转变了一下思路,整理出了另外一种在J2EE应用中管理Spark任务的方法。

由于触发的是一个远程Spark集群中的计算任务,所以后台肯定不可能集成Spark的API去启动任务。这时,可以调用远程Shell指令的方式,实现曲线救国。
首先:获取到远程指令执行的结果
<dependency>
<groupId>ch.ethz.ganymed</groupId>
<artifactId>ganymed-ssh2</artifactId>
<version>build210</version>
</dependency>
使用这个功能组件,可以在Java应用中调用shell指令,并且获得shell指令的执行日志。并且还提供了SSH连接到远程服务器的功能,非常全面贴心。这里提供一个简单的执行远程shell指令的测试方法,大家赶紧拿到自己的环境中去试试把。
//hostName:远程服务器地址,userName:远程服务器登录用户,password:远程服务器登录密码,command:要执行的shell指令
private static int submitCommand(String hostName String userName,String password, String command)
try
//登录远程服务器 注意Connection,Session这些都是ganymed-ssh2工具包中的类
Connection conn = new Connection(hostName);
conn.connect();
boolean isAuthenticated = conn.authenticateWithPassword(userName, password);
if (isAuthenticated == false)
throw new IOException("Authentication failed.");
Session sess = conn.openSession();
sess.execCommand(command);
System.out.println("be executing command : " + command);
System.out.println("===================== Start =====================");
//解析指令执行日志
InputStream stdout = null;
stdout = new StreamGobbler(sess.getStdout());
BufferedReader br = new BufferedReader(new InputStreamReader(stdout, "UTF-8"));
while (true)
String line = br.readLine();
if (line == null)
break;
if ("".equals(line.trim()))
continue;
System.out.println(line);
br.close();
System.out.println("===================== END =====================");
sess.waitForCondition(ChannelCondition.EXIT_STATUS, 60*60*1000);//默认等待一个小时的数据
System.out.println("ExitCode: " + sess.getExitStatus());
sess.close();
conn.close();
if(sess.getExitStatus()==null)
return 1;
return sess.getExitStatus();
catch (IOException e)
e.printStackTrace(System.err);
return 1;
这样就可以在Java应用中打印出在远程服务器上执行shell指令的执行日志了。
然后:实现页面监控执行日志
其实获取到了执行结果之后,想要在页面展示执行结果,相对就比较简单了。我们可以引入SpringBoot当中的HttpSession来作为一个桥梁。将上面方法中通过readline读取到的每一行内容都放到Session当中。然后在前端启动一个定时任务,固定从Session中读取日志内容展示到前端页面。
这个实现方式并不难,设置并读取Session信息,这应该是最基本的操作了。但是唯一需要注意的是,在读取Session中的日志信息时,要记得读取完后就把Session中的这个信息清空,这样可以防止Session中的信息爆炸。通过这样简单的思路,就可以在页面上监控Spark任务执行的每一行日志。再对日志关键部分稍微做一点点美化,最终就形成了这样的执行效果

当然,基于Spark的场景,计算结果到底是成功还是失败?失败时问题出在哪里? 这些问题还是只能从日志中自行进行判断,在应用层还是很难完成这种复杂日志的解析的。
如果你把这整个过程自己总结并实现了一下,你会发现,使用Spark变得像我们使用mysql一样简单轻松。并且,如果将文中提到的远程调试与远程执行Shell指令结合起来,就完全可以实现像调试本地应用一样的开发感受。
以上是关于Spark远程调试+页面监控--用最熟悉的方式开发Spark应用的主要内容,如果未能解决你的问题,请参考以下文章