深度学习框架中的动态Shape问题
Posted qianqing13579
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习框架中的动态Shape问题相关的知识,希望对你有一定的参考价值。
前言
最近这段时间实现了公司内部深度学习框架的dynamic shape的功能。在完成这个功能之后,我进一步深刻体会到了乔布斯说过的一段话:
When you start looking at a problem and it seems really simple, you don’t really understand the complexity of the problem. Then you get into the problem, and you see that it’s really complicated, and you come up with all these convoluted solutions. That’s sort of the middle, and that’s where most people stop… But the really great person will keep on going and find the key, the underlying principle of the problem — and come up with an elegant, really beautiful solution that works.
大致意思:当你遇到一个问题的时候,乍一看它似乎很简单,这是因为你并没有真正理解这个问题的复杂性。当你深入研究这个问题的时候,你会意识到这个问题真的很复杂性,然后你想出了所有复杂的解决方案。然而大部分人仅仅做到这个程度。但真正了不起的人会坚持下去,直到找到解决问题的关键,从而提出一个堪称完美的解决方案。
实际上从开始解决这个问题到现在差不多有一个月的时间了,实际上第一版很早之前就开发出来了,那个时候我并没有认识到这个问题的复杂性,也没有形成系统性的方法论。当第一版程序遇到了各种各样问题的时候,我才意识到这个问题并没有那么简单。之后进行了很多调研并加入了自己很多的思考,逐渐对这个问题有了更加深刻的思考,最后形成了一套比较系统的解决方案。并成功完成了动态Shape功能的开发。
这两天整理了一下相关内容,跟大家分享一下自己的一些想法。欢迎对这个问题感兴趣的小伙伴留言讨论。
目录
Dynamic Shape问题
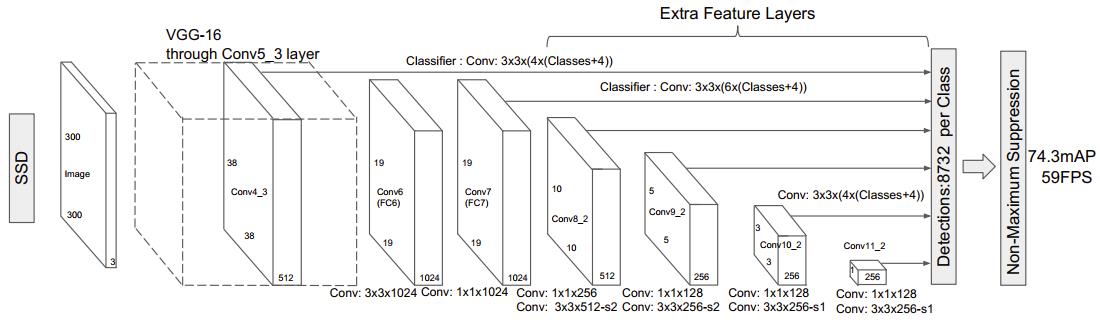
当一个模型具有多种输入/输出大小的时候,我们就说这个模型是一个dynamic shape模型,当一个模型是只有一种输入/输出大小的时候,我们就说这个模型是一个static shape模型。比如CV领域的目标检测模型SSD,YOLO这类检测模型能够支持多种输入大小(因为他们是全卷积神经网络),所以他们是dynamic shape模型。
动态模型示例:SSD
Dynamic Shape会带来什么问题
在static shape模式下,由于shape是固定的,计算图中每个节点的shape信息都是很明确的,所以可以做很多优化,比如:
- 内存优化:由于所有的shape信息都很明确,所以可以通过分析计算图中依赖关系实现内存复用,大大降低内存消耗,比如在TNN框架解析 这篇博客中提到的内存优化方式
- 计算图优化:目前主流的深度学习框架都会采用多种计算图优化来提高性能。比如eliminate concat优化,这个优化用来删除计算图中的concat算子,但是删除concat算子需要知道明确的输出shape信息,这样才能计算出各个部分在目标内存中的offset,如下图,需要明确知道三个卷积层输出shape信息,然后计算出offset,才能够完成eliminate concat的优化

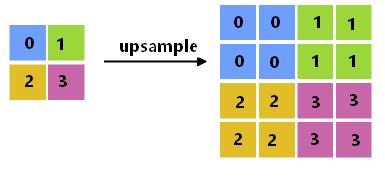
- 提前计算:当一个计算可以提前计算出结果而且在运行期这个值不会改变的时候,我们通常会提前计算好并保存为常量。比如upsample算子,如果upsample算子采用最近邻插值,由于输入和输出大小都是已知的,所以可以提前将插值的索引计算出来保存为常量,前向计算的时候,直接按照索引值去原图中取数据即可
但是在dynamic shape模式中,上述优化就会遇到问题,有些优化甚至无法完成,比如上述的内存复用优化。而且还存在这样的一个问题:IR中部分算子无法表达动态shape信息计算以及shape信息的传递(算子的属性跟具体shape信息有关),比如broadcast,slice,在静态shape模式中,这部分算子所有的shape的计算在编译期会被固化为常量保存在编译结果中,而在动态shape模式中,需要将这部分修改为运行期执行,这就给实现动态shape带来了更大的问题。
不同框架是如何解决Dynamic Shape问题
通过上面的分析,我们知道由于不同框架实现的机制不同,所以在解决动态shape这个问题的时候要面临的问题也不同。
首先我们按照算子粒度大小将目前的深度学习框架划分为两大类:
- 粗粒度。比如Caffe,TNN
- 细粒度。比如Pytorch,TensorFlow,TVM
粗粒度框架由于算子粒度较粗,具有较少的访存次数和内核启动次数,所以相比于细粒度框架来说,执行速度更快,缺点是不够灵活。细粒度算子由于算子粒度较细,增加了访存次数和内核启动次数,所以执行速度较慢,为了解决性能问题细粒度框架通常会做很多计算图的优化,比如算子融合来减少访存次数,细粒度框架通常通过编译阶段来完成这些优化。
下面我们分析一下不同框架在解决动态shape的时候遇到了哪些问题以及是如何解决dynamic shape问题的。
粗粒度框架如何解决Dynamic Shape问题
Caffe
Caffe是第一代深度学习框架,Caffe的算子粒度很粗,而且Caffe没有做内存复用优化,也没有做太多计算图优化,所以Caffe就不用解决上面提到的动态shape带来的这些问题,这就使得Caffe很容易实现动态shape机制,Caffe的Reshape函数只需要根据输入Blob的shape重新计算输出Blob的shape,然后重新分配内存即可,所以Caffe实现Reshape的机制还是比较简单的。
以concat层为例,看一下Caffe中Reshape的实现:

Caffe中每一层的Reshape函数首先会计算输出Blob的shape,然后对输出Blob进行reshape。
下面我们看一下Caffe的Forward的实现:
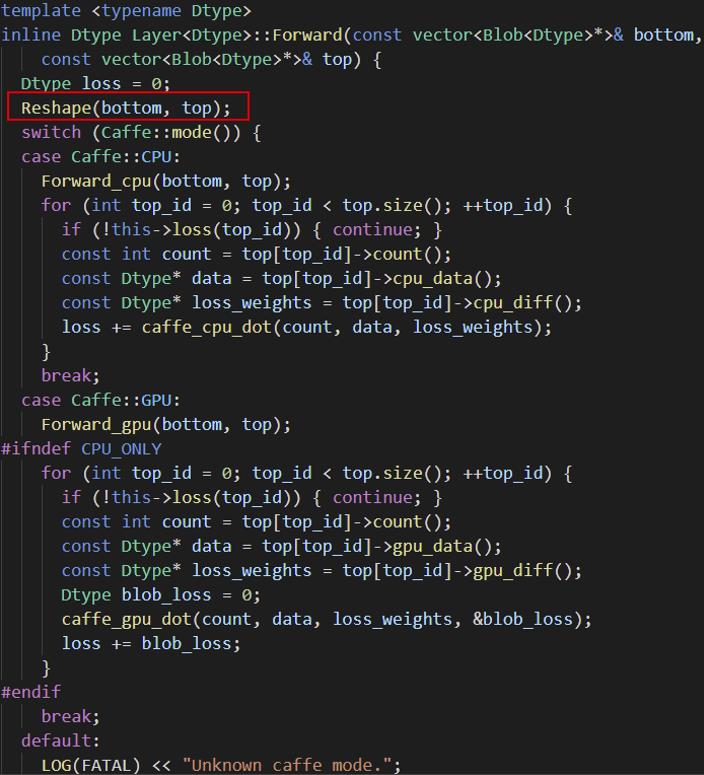
Caffe在每次Forwar的时候,都需要先执行Reshape操作,即使输入是固定大小,Caffe在运行的时候都需要调用Reshape操作。虽然Caffe解决了动态shape的问题,但是效率较低。
下面总结一下Caffe的动态shape机制:
优点:
- 可以完备支持dynamic shape模式
缺点:
- 由于没有内存复用优化,内存消耗大
- 频繁的内存申请和释放,降低了性能
- 只有动态shape模式,不能支持静态模式,影响系统性能
TNN
我们先看一下TNN实现dynamic shape的一个简单示例程序:
TNN_NS::TNN tnn;
// 加载模型
auto tnnProto = fdLoadFile("SSD.tnnproto"); // 网络结构
auto tnnModel = fdLoadFile("SSD.tnnmodel"); // 权重
TNN_NS::ModelConfig modelConfig;
modelConfig.model_type = TNN_NS::MODEL_TYPE_TNN;
modelConfig.params = tnnProto, tnnModel;
tnn.Init(modelConfig);
// 设置最小和最大输入大小
std::map<std::string, std::vector<int>> minInputShape;
std::map<std::string, std::vector<int>> maxInputShape;
minInputShape["input"]=1,3,300,300;
maxInputShape["input"]=1,3,1024,1024;
TNN_NS::NetworkConfig networkConfig;
networkConfig.device_type = TNN_NS::DEVICE_NAIVE;
TNN_NS::Status error;
auto net = tnn.CreateInst(networkConfig, error,minInputShape,maxInputShape);
// 输入大小
vector<cv::Size> inputSizes;
inputSizes.push_back(cv::Size(512,512));
inputSizes.push_back(cv::Size(1024,1024));
cv::Mat srcImage=imread("Test.jpg",1);
for(int i=0;i<inputSizes.size();++i)
// reshape
std::vector<int> inputShape=1,3,inputSizes[i].height,inputSizes[i].width;
TNN_NS::InputShapesMap inputShapeMap;
inputShapeMap["input"] = inputShape;
net->Reshape(inputShapeMap);
// 输入数据
cv::Mat inputBlob;
std::shared_ptr<TNN_NS::Mat> inputMat(new TNN_NS::Mat(TNN_NS::DEVICE_NAIVE, TNN_NS::NCHW_FLOAT, inputShape,(void *)inputBlob.data));
TNN_NS::MatConvertParam inputConvertParam;
net->SetInputMat(inputMat, inputConvertParam);
// 推理
net->Forward();
通过前面TNN的解析我们可以知道,TNN很多设计参考了Caffe,也采用了粗粒度算子机制,但是TNN在运行期之前做了很多优化,比如内存复用优化,计算图优化,这样TNN在实现动态shape的时候,就会遇到上述我们提到的几个问题。那TNN是如何解决这些问题的呢?首先看一下内存管理。TNN在实现动态shape的时候,需要先设置一个最大输入大小,这样做是因为在模型使用不同输入大小的时候,确保内存够用,这样就不用进行频繁的内存申请和释放,这样就大大提高的系统性能,同时由于TNN进行了内存复用优化,可以显著降低内存消耗。而且由于TNN并没有在Forward中执行Reshape,而是将Reshape和Forward进行了解耦,这样TNN就可以实现static shape模式和dynamic shape两种模式,当使用固定输入的时候采用static shape模式,当使用动态输入的时候采用dynamic shape模式,而Caffe不管输入是否固定只能采用dynamic shape模式。关于计算图的优化,TNN并没有使用类似eliminate concat这种需要明确shape信息的优化,TNN只使用了部分不需要明确知道shape信息的计算图优化,所以TNN在这部分不需要进行过多的处理。
下面总结一下TNN的动态shape机制:
优点:
- 消除了动态shape中频繁的内存申请和释放
- 实现了内存复用优化,降低内存消耗
- 可以实现static shape和dynamic shape两种模式
缺点:
- 需要设置最大输入大小,在无法确定最大输入大小的场景下可能会导致程序异常
细粒度框架如何解决Dynamic Shape问题
通过上面的分析我们知道,细粒度框架由于要解决性能问题,在运行期之前一般会增加一个编译步骤,编译步骤一般会实现很多优化,比如上面提到的内存复用优化,计算图优化,常量折叠优化等,这样细粒度框架在解决动态shape的时候会遇到如下几个方面的问题:
- 部分算子的属性与具体shape信息有关,比如broadcast,slice,这些算子需要在运行期修改
- 部分计算图优化与具体shape信息有关
- 内存管理,由于无法知道准确的shape信息,所以无法实现静态shape模式下的内存优化
最近调研了一下阿里PAI团队最新推出的一款深度学习框架: DISC: A Dynamic Shape Compiler for Machine Learning Workloads,这个框架的主要亮点就是解决了动态shape问题,下面简单分析一下DISC是如何解决的,由于该框架目前并没有开源,论文中很多细节也并没有提到,所以对论文的有些理解可能并不是很准确。
DISC: A Dynamic Shape Compiler for Machine Learning Workloads
DISC是基于MLIR(Multi Layer Intermediate Representation)的一款支持动态shape的深度学习框架。DISC具有以下特点:
- DISC在XLA的HLO IR基础上设计了一套可以完备支持动态shape表达的DHLO IR,这使得DISC可以支持多种前端深度学习框架,比如TensorFlow,Pytorch
- DISC利用shape的约束信息,完成了很多计算图的优化,比如算子融合,内存优化
- DISC同时支持static shape和dynamic shape两种运行模式,当DISC检测到采用固定输入的时候,DISC会自动切换到static shape模式,可以完成更多优化,提高性能。
DISC整体架构
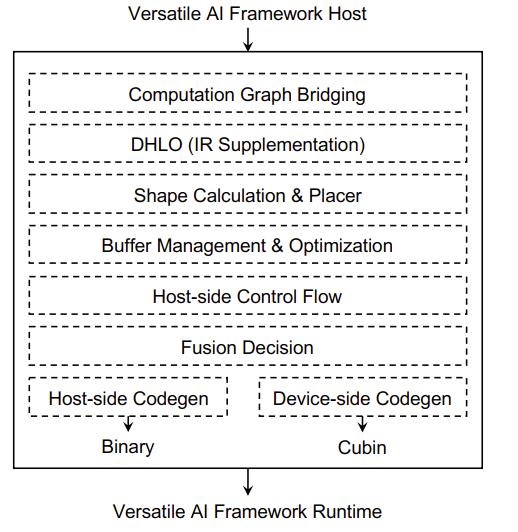
- computation graph bridging:这是一个桥接层,将前端AI框架计算图lower为DISC中的IR表示
- DHLO:DISC在XLA的HLO IR基础上设计的一套可以完备支持动态shape表达的IR
- Shape Calculation & Placer:这一层进行了 shape calculation的自动代码生成,DISC将计算分为shape计算和数据计算,将shape计算部分代码放在Host端,数据处理部分代码放在device端
- buffer management:主要负责内存管理
- host-side control:主要负责外部库的调用,内核启动的管理,设备管理等
- Fusion decision:主要完成op的融合,在动态shape模式下DISC根据shape的约束信息执行多种op融合
- codegen:自动代码生成,生成主机端和设备端的可执行代码
DISC是如何解决Dynamic shape问题的
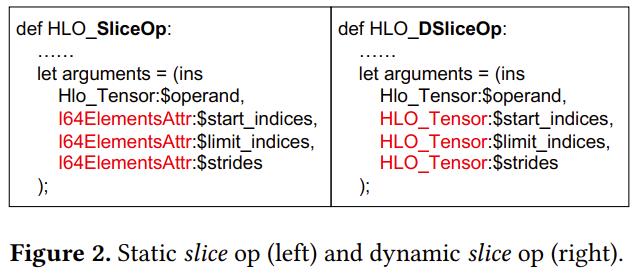
- IR中部分不具备动态shape表达能力的算子,比如broadcast,slice。DISC在XLA的HLO IR基础上,扩展了一套具有完备动态shape表达能力的IR:DHLO。对于那些在编译期计算出来的常量属性的算子修改为在运行期计算,比如 slice算子,在HLO IR中,slice算子的属性(start_indices,stride)会被编译为常量,但是在动态shape中,这些属性会发生改变,所以这些属性需要修改为在运行期计算,DHLO的做法就是将这些属性修改为运行期Tensor计算。这一点是DISC中实现动态shape机制最关键的部分。
- 内存管理。在静态Shape模式下编译期能够比较容易通过liveness分析,实现复用等优化,在动态shape模式下,由于shape信息未知编译期则不容易做到完全一致的优化。DISC目前采用的还是动态内存申请和释放,同时基于IR中的Shape Constraint信息做了部分内存复用优化
- 计算图优化。对于那些需要知道准确shape信息的计算图优化,DISC舍弃了部分优化,同时DISC充分利用了Shape Constraint信息进行了计算图优化和代码生成,比如如果两个op的输入大小相同或者相近,就可以考虑将这两个算子进行融合
下面总结一下DISC的动态shape机制:
优点:
- 可以完备支持dynamic shape模式
- 同时支持static shape和dynamic shape两种运行模式
缺点:
- 虽然利用了Shape Constraint信息,做了部分内存优化,但是在shape变化分为很大的情况下,存在频繁的内存申请和释放,降低了系统性能
- 虽然做了部分内存优化工作,但是内存消耗依旧较大
结束语
以上就是自己对动态shape的一些分析和思考。自己在实现动态shape机制的时候,融合了上述各个框架的优点,最后还算是比较成功的实现了动态shape这个功能。文中有不对的地方,欢迎大家批评指正。
2021-10-30 16:18:25
非常感谢您的阅读,如果您觉得这篇文章对您有帮助,欢迎扫码进行赞赏。

以上是关于深度学习框架中的动态Shape问题的主要内容,如果未能解决你的问题,请参考以下文章