《CondInst:Conditional Convolutions for Instance Segmentation》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《CondInst:Conditional Convolutions for Instance Segmentation》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:
1. 概述
介绍:这篇文章描述的是单阶段的实例分割算法,类似与SOLO模型将不同的实例编码到channel和动态卷积参数中一样,这篇文章借鉴的是动态卷积参数去独立表征每个实例mask。回顾之前的两阶段实例分割算法(以Mask RCNN)为代表其存在如下的一些问题:1) 该方法通常会根据RoI box使用RoI Align的策略将特征图实现对齐与抠取,但是在一些情况下会引入较多背景区域的干扰,特别是对于存在旋转的目标(现在也有针对旋转目标的检测算法,但是其更加复杂);2) 为了更好区分前景和背景往往分割网络需要较大的感受野,因而在Mask RCNN算法中会堆叠多个kernel为 3 ∗ 3 3*3 3∗3的卷积,这样带来的问题就是耗时会增加;3) 实例分割对目标的边界是比较敏感的,在Mask RCNN中统一会将其分辨率压缩到 28 ∗ 28 28*28 28∗28,这显然不利于细节信息的表达;而直接使用分割算法却无法感知不同目标的外观信息与定位信息,导致实例分割的效果不佳。对此文行引入Conditional卷积,为每一个满足训练要求的实例生成对应的预测参数,从而实现在分割框架下完成实例分割。
这里将文章的方法与之前的一些实例分割方法进行对比,见下图:

2. 方法设计
2.1 整体pipeline
文章方法的流程图见下图所示:
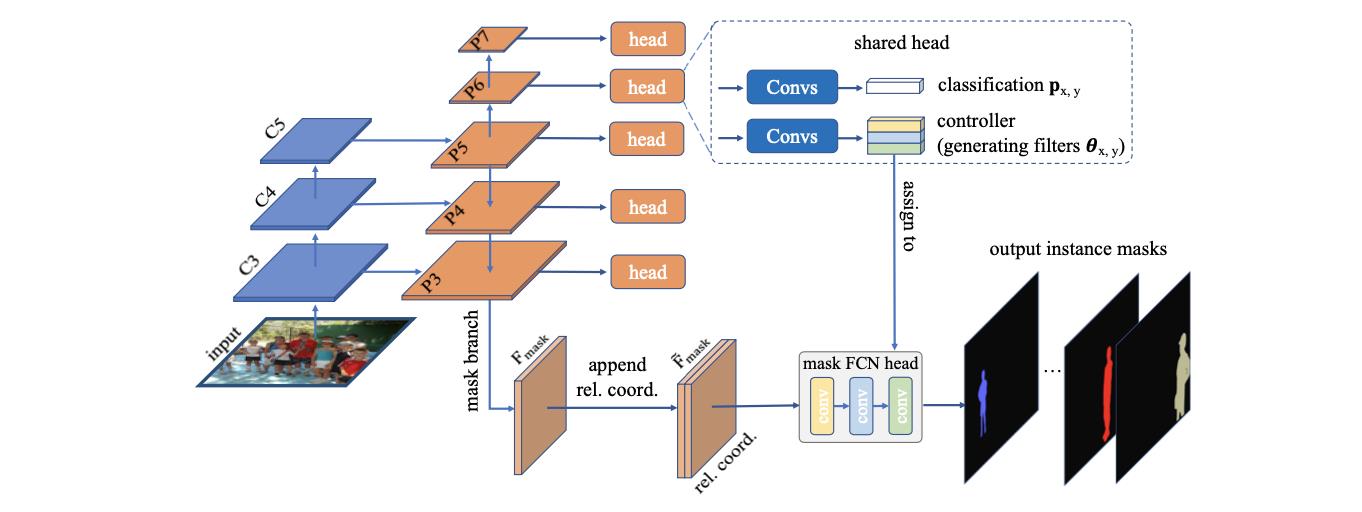
通看文章的方法,其是建立在FCOS算法之上的,主要的区别有两点:
- 1)在原有分类、box回归、center-ness分支上增加了一个预测动态卷积参数的controller模块,其生成169个channel的特征;
- 2)在FPN网络输出P3部分增加Mask-branch,生成用于实例mask预测的 F m a s k F_mask Fmask特征,该特征之后会concat上相对位置结合动态卷积参数生成每个实例的预测mask;
上述内容中
F
m
a
s
k
F_mask
Fmask生成过程中包含的layer_nums和channels对整体分割性能和速度的影响见下表:
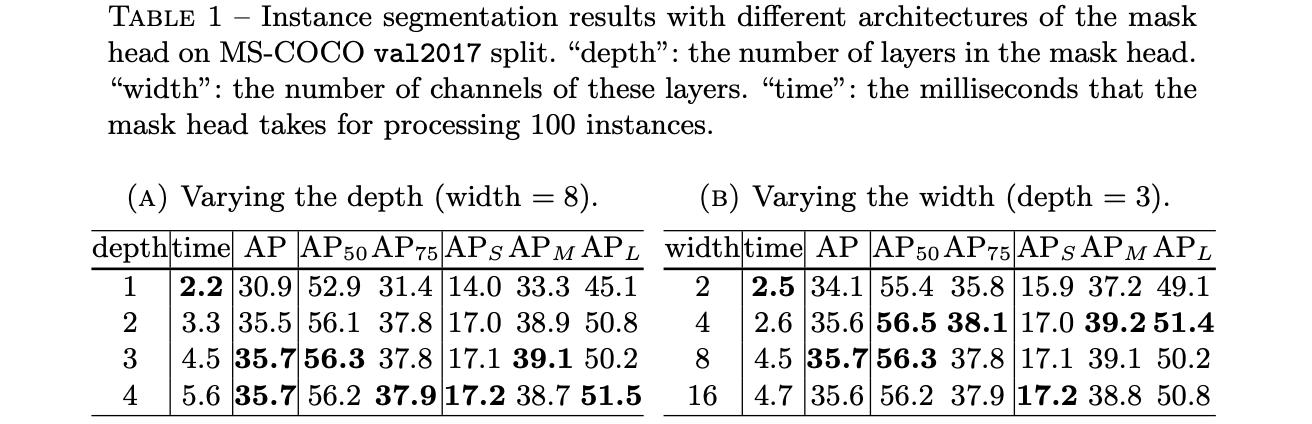
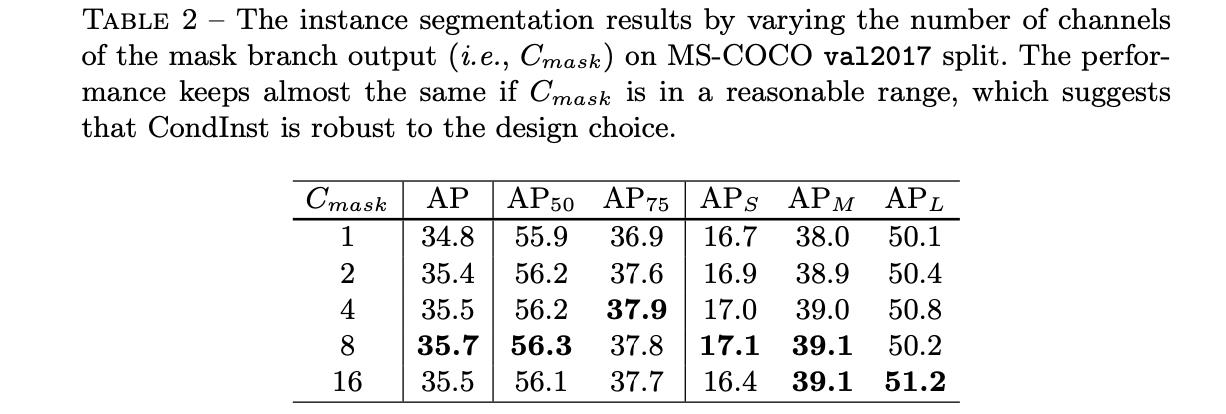
最后生成
F
m
a
s
k
F_mask
Fmask的时候其channel数量对性能的影响见下表(channel数为8也能达到不错的效果):
2.2 实例预测过程
在上面提到动态参数channel维度是169维度的,其实这169维度里面是包含了3个动态卷积的参数的,其decode过程(也是实例分割预测的过程)可以描述为下面的这一段代码:
# fcos/modeling/fcos/fcos_outputs.py#L366
def forward_for_mask(self, boxlists):
N, dim, h, w = self.masks.shape
# 生成位置坐标
grid_x = torch.arange(w).view(1, -1).float().repeat(h, 1).cuda() / (w - 1) * 2 - 1
grid_y = torch.arange(h).view(-1, 1).float().repeat(1, w).cuda() / (h - 1) * 2 - 1
x_map = grid_x.view(1, 1, h, w).repeat(N, 1, 1, 1)
y_map = grid_y.view(1, 1, h, w).repeat(N, 1, 1, 1)
# 将相对坐标位置与mask_feat组合
masks_feat = torch.cat((self.masks, x_map, y_map), dim=1) # [N, 10, h, w]
o_h = int(h * self.strides[0])
o_w = int(w * self.strides[0])
for im in range(N): # 遍历每张图片
boxlist = boxlists[im]
input_h, input_w = boxlist.image_size
mask = masks_feat[None, im]
ins_num = boxlist.controllers.shape[0]
# [inst_num*8, 10, 1, 1]
weights1 = boxlist.controllers[:, :80].reshape(-1, 8, 10).reshape(-1, 10).unsqueeze(-1).unsqueeze(-1)
# [inst_num*8]
bias1 = boxlist.controllers[:, 80:88].flatten()
# [inst_num*8, 8, 1, 1]
weights2 = boxlist.controllers[:, 88:152].reshape(-1, 8, 8).reshape(-1, 8).unsqueeze(-1).unsqueeze(-1)
# [inst_num*8]
bias2 = boxlist.controllers[:, 152:160].flatten()
# [inst_num, 8, 1, 1]
weights3 = boxlist.controllers[:, 160:168].unsqueeze(-1).unsqueeze(-1)
# [inst_num]
bias3 = boxlist.controllers[:, 168:169].flatten()
conv1 = F.conv2d(mask, weights1, bias1).relu() # 普通卷积
conv2 = F.conv2d(conv1, weights2, bias2, groups=ins_num).relu() # 分组卷积
masks_per_image = F.conv2d(conv2, weights3, bias3, groups=ins_num) # 分组卷积
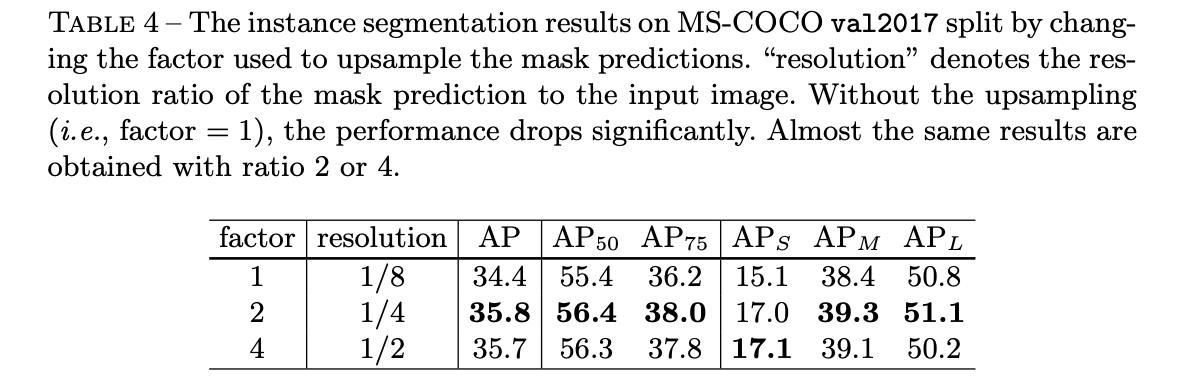
参与预测实例分割的特征图stride对于最后分割性能的影响见下表:
2.3 损失函数
对于mask部分的损失,只会将满足置信度和NMS要求的实例参与到最后mask求取过程,则实例分割部分的损失函数描述为:
L
m
a
s
k
(
θ
x
,
y
)
=
1
N
p
o
s
∑
x
,
y
1
c
x
,
y
∗
>
0
L
d
i
c
e
(
M
a
s
k
H
e
a
d
(
F
ˉ
x
,
y
;
θ
x
,
y
)
,
M
x
,
y
∗
)
L_mask(\\\\theta_x,y\\)=\\frac1N_pos\\sum_x,y\\mathcal1_\\c_x,y^*\\gt0\\L_dice(MaskHead(\\barF_x,y;\\theta_x,y),M_x,y^*)
Lmask(θx,y)=Npos1x,y∑1cx,y∗>0Ldice(MaskHead(Fˉx,y;θx,y),Mx,y∗)
总的损失函数为:
L
o
v
e
r
a
l
l
=
L
f
c
o
s
+
λ
L
m
a
s
k
L_overall=L_fcos+\\lambda L_mask
Loverall=Lfcos+λLmask
3. 实验结果
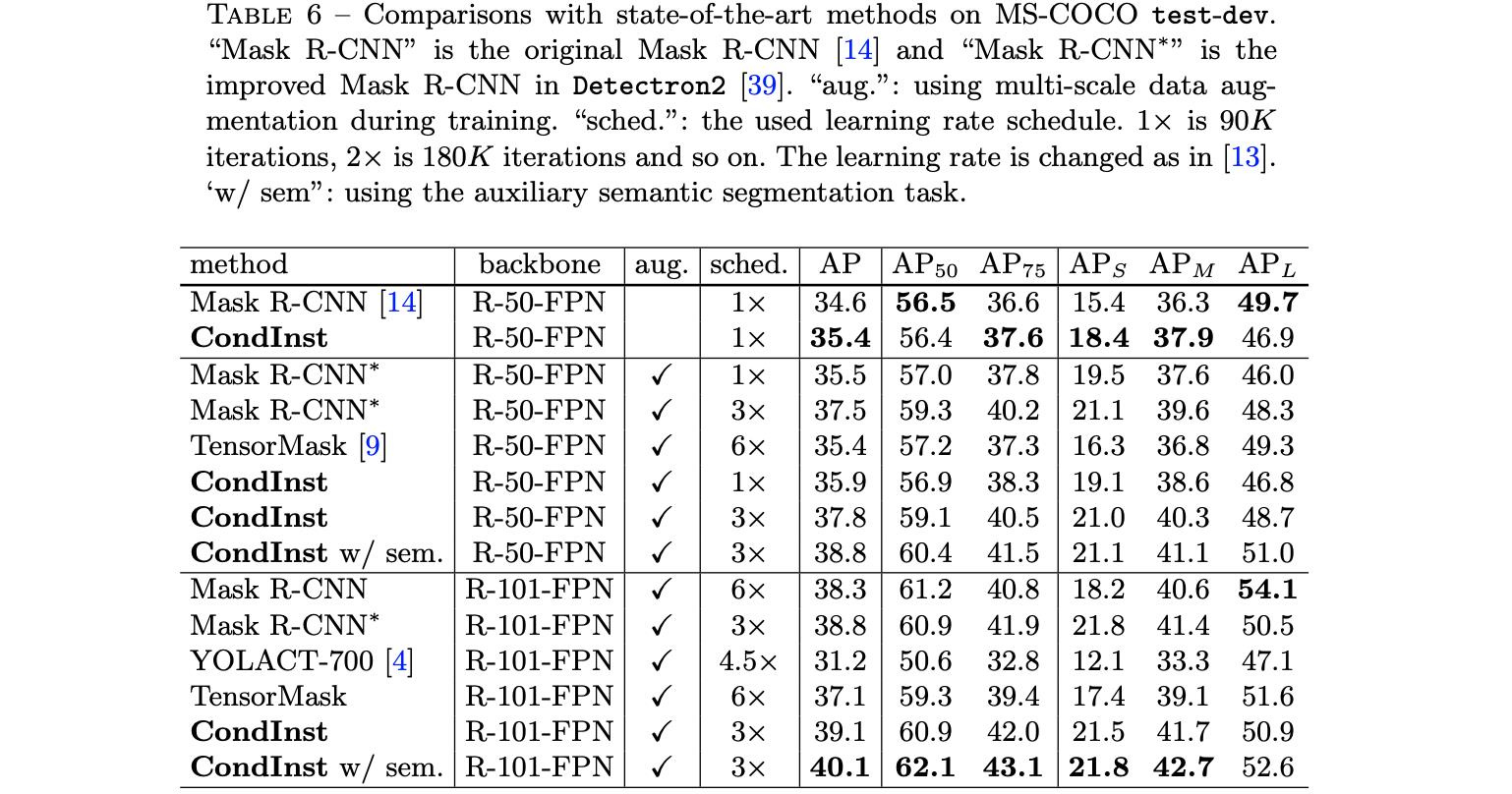
MS-COCO test-dev上的性能比较:
以上是关于《CondInst:Conditional Convolutions for Instance Segmentation》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章