分布式记账的几种方式
Posted 广州接入
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式记账的几种方式相关的知识,希望对你有一定的参考价值。
分布式记账是区块链中的叫法,是业务层面的概念,技术层面叫分布式存储。而分布式存储就是将我们要存的数据分开存储到不同的存储设备上(可以是逻辑的,也可以是硬盘的,通常都是不同的物理存储计算机上),有如下几种基本的方式:
1)所有数据都只有一份,但由于数据量大,一台机器上存储不下,分开存储在多台存储机器上;这种方式解决了数据量大的存储问题,但没有解决数据备份问题,安全上会有缺陷;
2)数据有多份,数据的每份都存储在不同的机器上,如果和前面的方式结合,就既解决了数据量大的存储问题,也解决了数据备份的问题。但对于为了数据安全,数据保存多少份比较合适就是一个非常重要的考量。备份多了,会增加存储成本和数据一致性维持成本。区块链原教旨主义所采用的每个节点都保存一份记账那种方式,对于少量数据还行,数据量大一点就是非常不现实和没有效率的方式,会极大的浪费成本。目前业界普遍采用的都是谷歌hadoop首先采用的方式,保存3份。因为从工程角度来说,过多的备份数会大大增加存储成本,以及为了维持备份一致性所付出的计算和带宽成本,所以保持3份是一个比较好的选择,实际上很多应用,做两份就已经足够了。当然,保存三份的方案也有很多细节的不同,例如是一主二从,还是三份对等,是冷备方式还是热备方式等。
3)为了提高性能,针对第1种方式,其实也有很多实现方案,例如就近使用者方案,这种方案将数据放在接近使用其数据最多人的地方,典型的就是有区域性使用属性的数据,例如天气数据,接种数据等。
4)针对第2种带有备份性质的分布式存储的备份分布策略,又有不同机器,不同机房,不同区域等多种分布策略。每种分布策略的安全性不一样,同时成本也不同。具体采用那种方式要看你的具体业务场景下数据的重要性来定。当然,如果你采用的是区块链所要求的每个参与的节点都保存一份,就不用考虑这种分布策略。
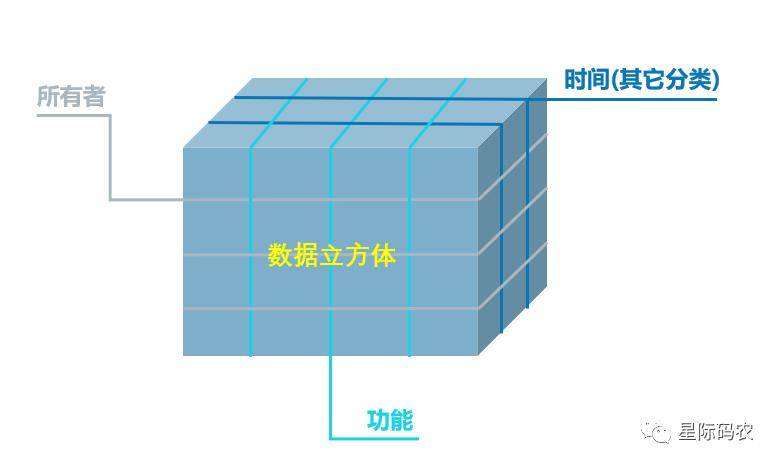
5)对于大数据而言,如果数据不仅规模大,而且数据种类多,这种情况下,我们需要针对数据进行存储切割,按产生数据的功能来分,就是我们通常的微服务模式;我们也可以按所有者分,这样方便处理和区分不同所有者的数据;同时也会按时间维度进行一定的划分,区分数据的冷热,以提高数据处理的效率和性能。上面的业务、所有者和时间只是我们比较习惯的三个切分维度,当然,你也可以根据你自己业务场景的需要采用其它的分类维度来切分。更为复杂的情况,我们也可以根据多个维度同时进行切割,例如下面图所示:
对于数据的具体存储又涉及到是文件存储还是数据库存储,是结构化存储还是非结构化存储等方式。虽然当前处理这种分布式记账的技术相对成熟,但在实际实现的过程中为了取得比较好的效率和性能,还是有非常多的细节工作需要做。区块链中的分布式记账方式是最没有效率,最浪费资源的。开个玩笑,如果碳排放硬性要求收税,挖的币还不够支持碳排放税的。
对于分布式系统来说,一般来讲系统应该包含程序的分布和数据的分布两个部分,通常的系统的分布式架构应该是程序分布和数据分布同时。但在实际的应用系统架构过程中,很多软件企业基于开发中的难度都是只做程序的分布,没有做数据的分布,使得系统的瓶颈并没有得到很多改观。这种现象在业界大吹的微服务架构中尤其普遍,包括很多大的软件公司都是销售和技术一顿乱吹,但实际上根本不是合格的微服务架构。签合同前,反正你看不见系统,都是非常牛逼的架构,但签合同后,看到系统的时候骂娘都来不及了。本来做个技术应该是比较纯粹的事情,只能说人性确实很复杂。
以上是关于分布式记账的几种方式的主要内容,如果未能解决你的问题,请参考以下文章