TF-IDF介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TF-IDF介绍相关的知识,希望对你有一定的参考价值。
参考技术A TF-IDF是一种统计方法,用以评估一个词对于一篇文章或语料库中一篇文章的重要性。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
一个词预测主题的能力越强,权重就越大,反之,权重越小,因此一个词的TF-IDF就是:
通常在新闻的分类,或者说文章的分类的时候我们会用到ID-IDF。如果让编辑来对新闻或者文章分类,他一定要先读懂文章,然后找出主题,最后根据主题的不同对文章进行分类。而让电脑对文章进行分类,就要求我们先把文字的文章变成一组可以计算的数字,然后通过算法来算出文章的相似性。
首先我们先来看怎么用一组数字(或者说一个向量)来表示一篇文章。对于一篇文章的所有实词(除去无意义的停用词),计算出他们的TF-IDF值,把这些值按照对应的实词在词汇表的位置依次排列,就得到了一个向量。比如,词汇表中有64000个词,其编号和词:
在某一篇文章中,文章中的词的TF-IDF值对应为:
如果单词表的某个词在文章中没有出现,对应的值为零,这样我们就得到了一个64000维的向量,我们称为这篇文章的特征向量。然后每篇文章就可以用一个向量来表示,这样我们就可以计算文章之间的相似程度了。
向量的夹角是衡量两个向量相近程度的度量。因此,可以通过计算两篇文章的特征向量的夹角来判断两篇文章的主题的接近程度。那么我们就需要用余弦地理了。
∠A的余弦值为:
如果将三角形的两边b和c看成是两个以A为起点的向量,那么上述公式等于:
其中,分母便是两个向量b和c的长度,分子表示两个向量的内积。假设文章X和文章Y对应的向量是
那么他们的夹角的余弦等于
由于向量中的每一个变量都是正数,所以余弦的取值在0到1之间。当两篇文章向量的余弦等于1时,这两个向量夹角为零,两篇文章完全相同;当夹角的余弦接近于1时两篇文章越相似,从而可以归成一类;夹角的余弦越小,夹角越大,两篇文章越不相关。
现在假定我们已知一些文章的特征向量,那么对于任何一个要被分类的文章,就很容易计算出它和各类文章的余弦相似性,并将其归入它该去的那一类中。
如果事先没有已知的文章的特征向量呢,可以用自底向上不断合并的方法。
这样不断做下去,类别越来越少,而每个类越来越大。当某一类太大时,这一类里的文章的相似性就很小了,这时就要停止迭代过程了,然后完成分类。
TF-IDF算法介绍,简单模拟,以及在图数据中应用
一、百度百科关于TF-IDF的算法介绍
https://baike.baidu.com/item/tf-idf/8816134?fr=aladdin
二、简单模拟
既然是简单模拟,我们就用人们最常用的一种工具MySQL去模拟一下这个算法可以实现的效果
2.1、创建表以及数据
article_keywords.sql
CREATE TABLE `article_keywords` (
`id` int NOT NULL AUTO_INCREMENT,
`article` varchar(255) NOT NULL,
`keyword` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=126 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `article_keywords` VALUES ('113', '悟空悟空芭蕉扇牛魔王', '悟空');
INSERT INTO `article_keywords` VALUES ('114', '悟空悟空芭蕉扇牛魔王', '悟空');
INSERT INTO `article_keywords` VALUES ('115', '悟空悟空芭蕉扇牛魔王', '芭蕉扇');
INSERT INTO `article_keywords` VALUES ('116', '悟空悟空芭蕉扇牛魔王', '牛魔王');
INSERT INTO `article_keywords` VALUES ('117', '悟空红孩儿红孩儿三昧真火三昧真火', '悟空');
INSERT INTO `article_keywords` VALUES ('118', '悟空红孩儿红孩儿三昧真火三昧真火', '红孩儿');
INSERT INTO `article_keywords` VALUES ('119', '悟空红孩儿红孩儿三昧真火三昧真火', '红孩儿');
INSERT INTO `article_keywords` VALUES ('120', '悟空红孩儿红孩儿三昧真火三昧真火', '三昧真火');
INSERT INTO `article_keywords` VALUES ('121', '悟空红孩儿红孩儿三昧真火三昧真火', '三昧真火');
INSERT INTO `article_keywords` VALUES ('122', '悟空三昧真火火眼金睛', '三昧真火');
INSERT INTO `article_keywords` VALUES ('123', '悟空三昧真火火眼金睛', '火眼金睛');
INSERT INTO `article_keywords` VALUES ('124', '悟空三昧真火火眼金睛', '悟空');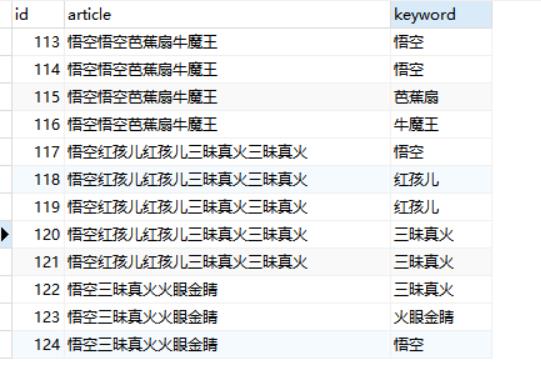
2.2、模拟实现TF-IDF的统计算分
实现sql
#实现TF-IDF的统计算分值
SELECT * FROM (
#计算TF-IDF的值
SELECT *,(TF * IDF)as 'TF-IDF' FROM (
#分别计算TF和IDF的值
SELECT *,(keyword_in_current_article_count / current_article_keyword_count) as TF,(article_count / keyword_in_all_article_count) as IDF FROM(
#查询表中数据以及联查计算TF-IDF所需的各种聚合值以及直接聚合文章总数量的值
SELECT article_keywords.*,keyword_in_current_article_count.keyword_in_current_article_count,current_article_keyword_count.current_article_keyword_count,keyword_in_all_article_count.keyword_in_all_article_count,(SELECT COUNT(1) FROM (SELECT article FROM article_keywords GROUP BY article) as a)as article_count FROM article_keywords as article_keywords
#联查关键词在当前文章中出现的频率的聚合表
LEFT JOIN (SELECT article,keyword,COUNT(1) as keyword_in_current_article_count FROM article_keywords GROUP BY article,keyword)as keyword_in_current_article_count
ON article_keywords.article = keyword_in_current_article_count.article AND article_keywords.keyword = keyword_in_current_article_count.keyword
#联查当前文章中所有关键词的个数的聚合表
LEFT JOIN (SELECT article,COUNT(keyword) as current_article_keyword_count FROM article_keywords GROUP BY article) as current_article_keyword_count
ON article_keywords.article = current_article_keyword_count.article
#联查出现此关键词的文章个数的聚合表
LEFT JOIN (SELECT a.keyword as keyword,COUNT(article) keyword_in_all_article_count FROM (
SELECT article,keyword FROM article_keywords GROUP BY article,keyword
)as a GROUP BY a.keyword)as keyword_in_all_article_count
ON article_keywords.keyword = keyword_in_all_article_count.keyword
) as article_keywords_tf_idf
) as article_keywords_tfidf
)as article_keywords_tfidf_order
#WHERE keyword = '三昧真火'
GROUP BY article,keyword ORDER BY article_keywords_tfidf_order.`TF-IDF` DESC
结果样例
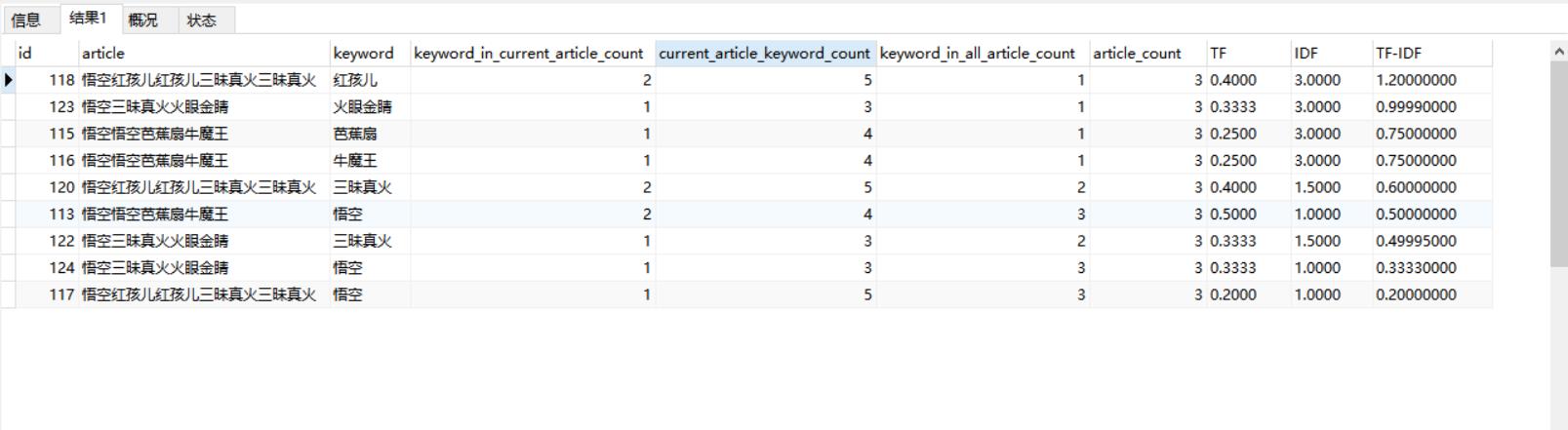
这只是用大家都熟悉的一个MySQL做一个简单的模拟实现的效果
当然,在实际应用中的场景比这要复杂的多,而且实际应用也不会使用MySQL来实现
下面我们来看看在图数据中的一个实际应用场景
三、图数据中应用
以上是关于TF-IDF介绍的主要内容,如果未能解决你的问题,请参考以下文章