python抓取局域网内数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python抓取局域网内数据相关的知识,希望对你有一定的参考价值。
现在在一个局域网内安装了一台TCP/IP协议的温湿度传感器,也分配好的地址,请问如何实现用python编写个小软件,抓取温湿度数据?
参考技术A 你必须要让传感器那边有接受/发送的相应协议。python怎么抓取网页中DIV的文字
第一张图是我抓取整个网页的代码,怎么修改把所有title的文字抓取出来?
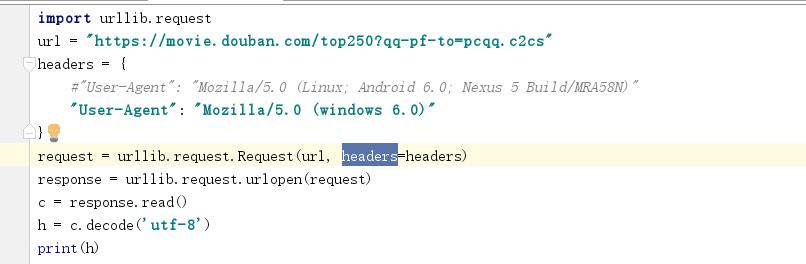
确定下载目标,找到网页,找到网页中需要的内容。对数据进行处理。保存数据。
2、知识点说明:
1)确定网络中需要的信息,打开网页后使用F12打开开发者模式。
在Network中可以看到很多信息,我们在页面上看到的文字信息都保存在一个html文件中。点击文件后可以看到response,文字信息都包含在response中。
对于需要输入的信息,可以使用ctrl+f,进行搜索。查看信息前后包含哪些特定字段。
对于超链接的提取,可以使用最左边的箭头点击超链接,这时Elements会打开有该条超链接的信息,从中判断需要提取的信息。从下载小说来看,在目录页提取出小说的链接和章节名。
2)注意编码格式
输入字符集一定要设置成utf-8。页面大多为GBK字符集。不设置会乱码。 参考技术A
使用 BeautifulSoup 进行解析 html,需要安装 BeautifulSoup
#coding=utf-8import urllib2
import socket
import httplib
from bs4 import BeautifulSoup
UserAgent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36'
def downloadPage(url):
try:
opener = urllib2.build_opener()
headers = 'User-Agent': UserAgent
req = urllib2.Request(url = url, headers = headers)
resp = opener.open(req, timeout = 30)
result = resp.read()
return result
except urllib2.HTTPError, ex:
print ex
return ''
except urllib2.URLError, ex:
print ex
return ''
except socket.error, ex:
print ex
return ''
except httplib.BadStatusLine, ex:
print ex
return ''
if __name__ == '__main__':
content = downloadPage("这填douban的地址")
#print content
soap = BeautifulSoup(content, 'lxml')
lst = soap.select('ol.grid_view li')
for item in lst:
# 电影详情页链接
print item.select('div.item > div.pic a')[0].attrs['href']
# 图片链接
print item.select('div.item > div.pic a img')[0].attrs['src']
# 标题
print item.select('div.item > div.info > div.hd > a > span.title')[0].get_text()
# 评分
print item.select('div.item > div.info > div.bd > div.star > span.rating_num')[0].get_text()
print '-------------------------------------------------------------------------'本回答被提问者和网友采纳 参考技术B 最简单的还是用DW,贴到里面,然后就能做了,也不是很难追问
我现在学的又不是DW,你和我说DW干啥?
以上是关于python抓取局域网内数据的主要内容,如果未能解决你的问题,请参考以下文章