如果mysql里面的数据过多,查询太慢怎么办?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如果mysql里面的数据过多,查询太慢怎么办?相关的知识,希望对你有一定的参考价值。
问题
我们有一个 SQL,用于找到没有主键 / 唯一键的表,但是在 mysql 5.7 上运行特别慢,怎么办?
实验
我们搭建一个 MySQL 5.7 的环境,此处省略搭建步骤。
写个简单的脚本,制造一批带主键和不带主键的表:
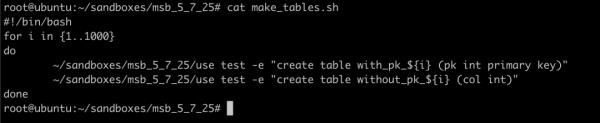
执行一下脚本:

现在执行以下 SQL 看看效果:
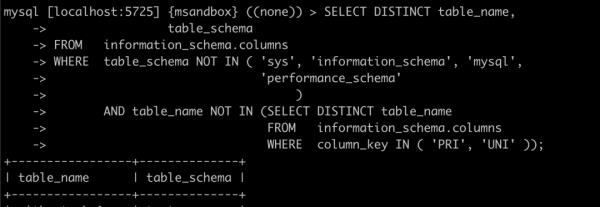
...
执行了 16.80s,感觉是非常慢了。
现在用一下 DBA 三板斧,看看执行计划:
感觉有点惨,由于 information_schema.columns 是元数据表,没有必要的统计信息。
那我们来 show warnings 看看 MySQL 改写后的 SQL:

我们格式化一下 SQL:
可以看到 MySQL 将
select from A where A.x not in (select x from B) //非关联子查询
转换成了
select from A where not exists (select 1 from B where B.x = a.x) //关联子查询
如果我们自己是 MySQL,在执行非关联子查询时,可以使用很简单的策略:
select from A where A.x not in (select x from B where ...) //非关联子查询:1. 扫描 B 表中的所有记录,找到满足条件的记录,存放在临时表 C 中,建好索引2. 扫描 A 表中的记录,与临时表 C 中的记录进行比对,直接在索引里比对,
而关联子查询就需要循环迭代:
select from A where not exists (select 1 from B where B.x = a.x and ...) //关联子查询扫描 A 表的每一条记录 rA: 扫描 B 表,找到其中的第一条满足 rA 条件的记录。
显然,关联子查询的扫描成本会高于非关联子查询。
我们希望 MySQL 能先"缓存"子查询的结果(缓存这一步叫物化,MATERIALIZATION),但MySQL 认为不缓存更快,我们就需要给予 MySQL 一定指导。
...

可以看到执行时间变成了 0.67s。
整理
我们诊断的关键点如下:
\\1. 对于 information_schema 中的元数据表,执行计划不能提供有效信息。
\\2. 通过查看 MySQL 改写后的 SQL,我们猜测了优化器发生了误判。
\\3. 我们增加了 hint,指导 MySQL 正确进行优化判断。
但目前我们的实验仅限于猜测,猜中了万事大吉,猜不中就无法做出好的诊断。
参考技术A 这个有很多方法,第一种优化查询sql,尽量避免全表检索,第二种添加联合索引,第三种采用表分区来存放数据,sql直接查对应的分区表 参考技术B 在数据库服务器上面的mysql窗口里面执行,很快就导出了100多W记录到excel里面。mysql> SELECT * into outfile '/tmp/rpt_style1_0.xls' FROM `csf_pub`.`rpt_style1_0` ;
Query OK, 1628696 rows affected (4.70 sec)
mysql数据库的最大连接数怎么查询?
参考技术A怎么查询mysql的最大连接数
查询命令为:
MySQL 默认的最大连接数为 100,可以在 mysql 客户端使用上述命令查看
此命令将得到类似以下的输出结果:
要对 mysql 的最大连接数进行修改,只需要在 my.cnf 配置文件里面修改 max_connections 的值,然后重启 mysql 就行。如果 my.ini 文件中没有找到 max_connections 条目,可自行添加以下条目
重启Mysql即可!
以上是关于如果mysql里面的数据过多,查询太慢怎么办?的主要内容,如果未能解决你的问题,请参考以下文章