利用awk命令提取其中一列包括特定字符的所有行怎么办
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用awk命令提取其中一列包括特定字符的所有行怎么办相关的知识,希望对你有一定的参考价值。
比如想用利用awk命令提取文件中第3列包含“GK”字符的所有行,应该怎样输入命令?
awk:用于一行中分成数个“字段”来处理。适合处理 小型数据。运行模式:awk '条件类型1动作1 条件类型2动作2 ...' filename
# last | awk 'print $1 "\t" $3' <== 查看登录者的数据,只显示登录名和ip地址,并以[tab]隔开
awk 的内置变量
变量名称 代表的含义
NF 每一行($0)拥有的字段总数
NR 当前 awk 所处理的是 “第几行” 数据
FS 当前分隔符,默认空格键
awk 的逻辑运算符
运算单元 代表含义
> 大于
< 小于
>= 大于或等于
<= 小于或等于
== 等于
!= 不等于
范例:
cat /etc/passwd | awk 'FS=":" $3 < 10 print $1 "\t" $3' <== 文件/etc/passwd是以":"分隔的,查看第三栏小于10的数据,并且只显示帐号与第三栏追问
例如我的文件第三列是我提取内容的依据,第三列是“GK001”"GK002"..."GK040" "LK003"“AP983”等,我需要把含“GK”字段的行全部提取出来,此时用awk怎么提取呢?
参考技术A 在Unity3d游戏程序运行时所有附加到游戏对象上的脚本组件都会运行, Awake方法和Start方法都只会运行一次,多用于数据初始化。 这两个方法的执行顺序是: 先执行Awake方法,再执行Start方法当脚本设置为不可用时
Awake方法仍然会执行一次,而Start方法则不会执行!
在游戏开始之前Awake用来初始化变量或游戏状态。 Awake方法在脚本生命周期中只会被调用一次。Awake方法在所有游戏对象初始化完之后才会被调用,所以可以安全的在Awake方法中引用或请求其它游戏对象数据。 所有游戏对象的Awake方法调用顺序是随机的。所以应该全用Awake方法来设置脚本之间的引用,而使用Start方法来互相来回传递信息。Awake方法总是在任何的Start方法调用之前调用。Awake不能做为协同(coroutine)使用
在Unity中使用Awake方法做为初始化器,而不是使用C#语法中的构造函数。在构造函数中进行初始化组件的序列化状态是未定义的。就像构造函数一样,Awake只调用一次。 参考技术B 好久没有用了,还得查查笔记咯
linux 查日志神器 - awk 相关常用命令
文章目录
前言
如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。
而且听说点赞的人每天的运气都不会太差,实在白嫖的话,那欢迎常来啊!!!
linux 查日志神器 - awk 相关常用命令
常用命令选项
-F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:,默认的分隔符是连续的空格或制表符
-v var=value 赋值一个用户定义变量,将外部变量传递给awk
-f scripfile 从脚本文件中读取awk命令
-m[fr] val 对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
awk内置变量
$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 这个变量包含执行过程中当前行的文本内容。
[N] ARGC 命令行参数的数目。
[G] ARGIND 命令行中当前文件的位置(从0开始算)。
[N] ARGV 包含命令行参数的数组。
[G] CONVFMT 数字转换格式(默认值为%.6g)。
[P] ENVIRON 环境变量关联数组。
[N] ERRNO 最后一个系统错误的描述。
[G] FIELDWIDTHS 字段宽度列表(用空格键分隔)。
[A] FILENAME 当前输入文件的名。
[P] FNR 同NR,但相对于当前文件。
[A] FS 字段分隔符(默认是任何空格)。
[G] IGNORECASE 如果为真,则进行忽略大小写的匹配。
[A] NF 表示字段数,在执行过程中对应于当前的字段数。
[A] NR 表示记录数,在执行过程中对应于当前的行号。
[A] OFMT 数字的输出格式(默认值是%.6g)。
[A] OFS 输出字段分隔符(默认值是一个空格)。
[A] ORS 输出记录分隔符(默认值是一个换行符)。
[A] RS 记录分隔符(默认是一个换行符)。
[N] RSTART 由match函数所匹配的字符串的第一个位置。
[N] RLENGTH 由match函数所匹配的字符串的长度。
[N] SUBSEP 数组下标分隔符(默认值是34)。
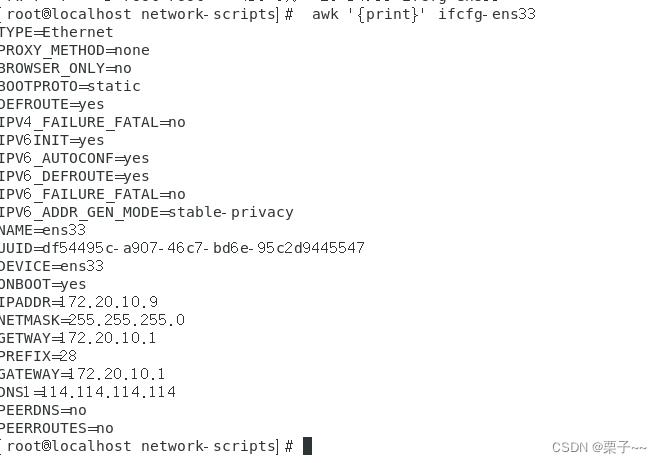
01 默认打印所有行
awk 'print' ifcfg-ens33
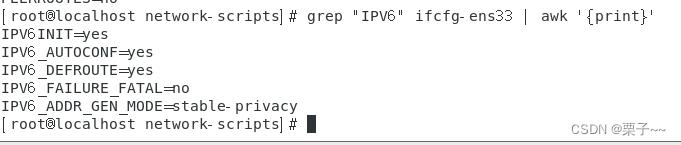
02 与grep过滤联用
grep “过滤内容” 文件 | awk ‘print’
示例:
grep "IPV6" ifcfg-ens33 | awk 'print'
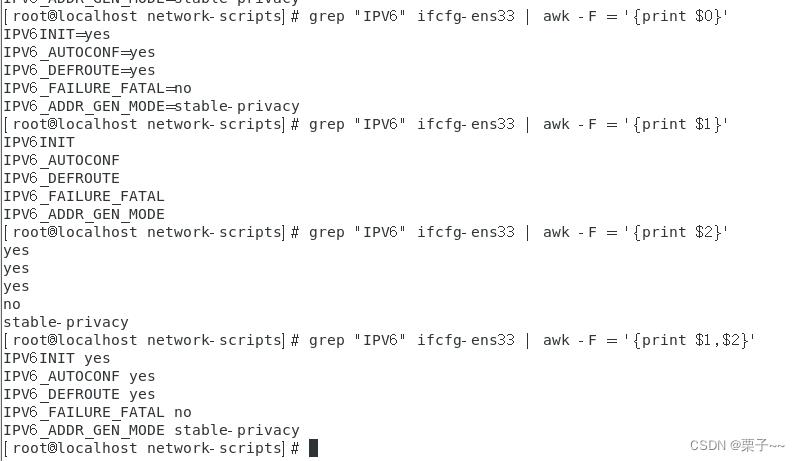
03 除了print 默认的行为,我们也可以将一行 split 成多个 field,根据所需进行打印
grep “过滤内容” 文件 | awk -F 拆分依据 ‘print $拆分游标’
示例:
grep "IPV6" ifcfg-ens33 | awk -F = 'print $0'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"="拆分成数组data ,打印data.toString()
grep "IPV6" ifcfg-ens33 | awk -F = 'print $1'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"="拆分成数组data ,打印data[0]
grep "IPV6" ifcfg-ens33 | awk -F = 'print $2'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"="拆分成数组data ,打印data[1]
grep "IPV6" ifcfg-ens33 | awk -F = 'print $1,$2'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"="拆分成数组data ,打印data[0]与data[1]
04 使用 NR 命令来输出指定行
示例:
首先第一步添加行号
grep "IPV6" ifcfg-ens33 | awk -F = 'print NR,$1'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"="拆分成数组data ,打印行号 +data[0]

也可以这样
grep "IPV6" ifcfg-ens33 | awk -F = 'print NR "-" $1'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"="拆分成数组data ,打印行号 -data[0]

第二步:指定行号进行输出
grep "IPV6" ifcfg-ens33 | awk -F = ' NR==2,NR==4 print NR "-" $1'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"="拆分成数组data ,打印行号为2到4区间的数据(行号 -data[0])

或者输出第三号的数据
grep "IPV6" ifcfg-ens33 | awk -F = ' NR==3 print NR "-" $1'

05 获取查询出来的总数-END
grep "IPV6" ifcfg-ens33 | awk -F = ' END print NR'
其实这里边的END的意思是打印最后一行,因为在这里我们进行了行号关联,因此也可以表示查询的数量;

06 $NF 命令- 表示最后一列
验证:
grep "IPV6" ifcfg-ens33 | awk -F = ' print NR "-" $0'
等于
grep "IPV6" ifcfg-ens33 | awk -F = ' print NR "-" $1,$NF'

07 awk -length函数计算字符串长度
示例:
grep "IPV6" ifcfg-ens33 | awk -F = ' print NR "-" $0'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"=“拆分成数组data ,打印"行号-data.toString()”
grep "IPV6" ifcfg-ens33 | awk -F = 'length($0) >20 print NR "-" $0'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"="拆分成数组data ,打印字符串长度大于20的数据【行号-data.toString()】

08 awk-if 函数判断打印
示例:
grep "IPV6" ifcfg-ens33 | awk -F = ' print NR "-" $0'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"=“拆分成数组data ,打印"行号-data.toString()”
grep "IPV6" ifcfg-ens33 | awk -F = ' if($2 == "yes") print NR "-" $0'
说明: 查询ifcfg-ens33里面过滤"IPV6"后的数据,并以"="拆分成数组data ,只打印data[1]==yes的数据【“行号-data.toString()”】

09 awk + uniq 显示或忽略重复的行
grep "IPV6" ifcfg-ens33 | awk -F = ' print $2'| uniq -c

10 awk + sort
排序选项:
-b, --ignore-leading-blanks 忽略开头的空白。
-d, --dictionary-order 仅考虑空白、字母、数字。
-f, --ignore-case 将小写字母作为大写字母考虑。
-g, --general-numeric-sort 根据数字排序。
-i, --ignore-nonprinting 排除不可打印字符。
-M, --month-sort 按照非月份、一月、十二月的顺序排序。
-h, --human-numeric-sort 根据存储容量排序(注意使用大写字母,例如:2K 1G)。
-n, --numeric-sort 根据数字排序。
-R, --random-sort 随机排序,但分组相同的行。
–random-source=FILE 从FILE中获取随机长度的字节。
-r, --reverse 将结果倒序排列。
–sort=WORD 根据WORD排序,其中: general-numeric 等价于 -g,human-numeric 等价于 -h,month 等价于 -M,numeric 等价于 -n,random 等价于 -R,version 等价于 -V。
-V, --version-sort 文本中(版本)数字的自然排序。
grep "IPV6" ifcfg-ens33 | awk -F = ' print $2'| uniq -c | sort -rn

11 扩展 zgrep
zgrep命令可以在压缩文件中调用grep按正则表达式来搜索
zgrep -A 100 a file.zip 查询压缩文件file.zip中包含a字符的内容的后面100行
zgrep -B 100 a file.zip 查询压缩文件file.zip中包含a字符的内容的前面100行
zgrep -C 100 a file.zip 查询压缩文件file.zip中包含a字符的内容的前后100行
zgrep -c a file.zip 查询压缩文件file.zip中包含a字符的行数
zgrep -i a file.zip 查询压缩文件file.zip中包含a或A字符的内容
以上是关于利用awk命令提取其中一列包括特定字符的所有行怎么办的主要内容,如果未能解决你的问题,请参考以下文章