Elasticsearch系列(13)Query之全文查询
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch系列(13)Query之全文查询相关的知识,希望对你有一定的参考价值。
参考技术A 全文查询(Full text queries)能够搜索已分析的text字段,如电子邮件的正文。全文查询支持以下方式的查询:匹配(match)查询返回与字段匹配的文档,支持字段类型包括文本、数字、日期或布尔值,对于文本值,在匹配之前对所提供的文本需进行分析。简单示例如下:
查询文本值“Brown Fox”,字段经过分析器分析后的分词(Brown和Fox),在文档字段值上必须全部匹配,示例如下:
查询文本值“Foaax”,模糊匹配查询,允许2个编辑距离,可以匹配到“Fox”,示例如下:
定义停止词过滤器“my_stop_words_filter”, 将zero_terms_query设置为all,match查询停用词,预期返回所有文档,示例如下:
匹配布尔前缀(match_bool_prefix)查询会首先分析输入的文本值,然后将分词后词条构造一个bool查询,除了最后一个词条外,每个词条都在term查询中使用,最后一个词条用于前缀查询。示例如下:
匹配文档字段content中包含“Quick”或前缀为“Brow”的文档,返回结果片段:
匹配短语(match_phrase)查询分析文本并且从分析的文本中创建一个短语查询。
匹配短语查询,在content字段中查询文本“White Fox”,不会拆分“White Fox”,如果文档中content字段包含“White Fox”,那么此文档匹配成功返回,示例如下:
返回结果片段如下:
匹配短语前缀(match_phrase_prefix)查询返回包含所输入文本中单词的文档,其顺序与所输入的相同,所输入的文本的最后一个词被视为前缀,并且返回的文档必须包含与该词开头的匹配的词条。
返回结果片段如下:
多值匹配(multi_match)查询建立在匹配(match)查询之上,允许多字段查询。
例如,在字段“content”或“user.name”上,查询文本“White Fox”,示例如下:
fields支持通配符查询。例如,在后缀为name的所有字段中查询,示例如下:
fields支持通过插入符号(^) 来提升单个字段。例如,content字段的相关性比字段user.name重要3倍,示例如下:
multi_match查询内部执行的方式取决于类型参数,其类型参数值包括:
首先创建索引my_index_03并且索引数据,示例如下:
most_fields使用示例如下:
phrase_prefix使用示例如下:
类似于
查询字符串(query_string)查询根据操作符(如AND或NOT)来解析和分割所提供的查询字符串,然后独立分析每个分割文本,最后返回匹配的文档,query_string查询严格按照查询语法,如果查询字符串包含任何无效语法,则返回错误。
例如,在my_index_03索引content字段上,查询“Brown”或“Quick White”文本值,示例如下:
通配符搜索可以在单个词条上运行,使用?替换单个字符,*替换零个或多个字符:
Qu?ck Bro*
正则表达式模式可以嵌入到查询字符串中,使用前斜杠中("/")包装:
content:/Qu.c[ki]/
使用模糊操作符进行模糊查询,默认编辑距离是2:
Quikc~
可修改编辑距离来控制拼写错误范围,如下修改编辑距离为1:
Quikc~1
可以为日期、数字或字符串字段指定范围。包含范围用方括号[min TO max]指定,排除范围用大括号min TO max指定。
使用boost操作符^使一个词条比另一个词条更相关。
默认情况下,只要有一个词条匹配,整个文档匹配。不过可以通过布尔操作符来更细粒度的控制。
首选操作符是+(该词条必须存在)和-(该词条必须不存在),其他词条可选的,例如,查询Fox必须存在、White必须不存在,示例如下:
Quick +Fox -White
多个词条或子句可以用括号组合在一起,形成子查询:
message:(Brown OR Fox) content:(White Fox)^2
如果需要在查询中使用作为操作符的字符(而不是作为操作符),那么应该使用前导反斜杠“\”对它们进行转义。例如,要搜索 (1+1)=2 ,需要将查询编写为 \(1\+1\)\=2 ,当为请求体使用JSON时,需要两个前面的反斜杠( \\ )。
可以使用fields参数在多个字段之间执行query_string搜索(用法参考多值匹配查询)。
简单查询字符串(simple_query_string)查询使用具有有限但容错语法的解析器,根据提供的查询字符串返回匹配文档。
它的语法比query_string查询简单,但是simple_query_string查询不会返回无效语法的错误。相反,它忽略查询字符串中任何无效的部分。
示例如下:
simple_query_string支持下列操作符:
根据匹配词条的顺序和接近度返回文档。间隔(intervals)查询使用一系列定义组成的匹配规则,将这些规则应用于来自指定字段的词条。
简单示例如下:
匹配(match)规则匹配分析的文本。
前缀(prefix)规则用来匹配以指定的一组字符开头的词条,这个前缀可以扩展到最多匹配128个词条,如果前缀匹配超过128词条,Elasticsearch将返回一个错误,可以在字段映射中使用index-prefixes选项来修改此限制。
通配符(wildcard)规则使用通配符模式匹配词条。此模式可以扩展到最多匹配128项,如果模式匹配超过128项,Elasticsearch将返回一个错误。
模糊(fuzzy)规则在由模糊性定义的编辑距离内匹配与所提供的词条相似的词条。如果模糊展开匹配的项超过128项,Elasticsearch将返回一个错误。
all_of规则返回跨其他规则组合的匹配项。
any_of规则返回其任一个子规则生成的intervals。
过滤(filter)规则基于查询返回间隔(intervals)。
下面的intervals查询中包含一个match规则,规则定义了查询文本为“Quick Fox”, 单词 Quick 和 Fox 之间的位置最大不超过10,match规则里包含一个filter规则,用来排除字段含有单词“Brown”的文档,具体如下:
返回结果片段如下:
下面的intervals查询中包含一个match规则,match规则里包含一个filter规则,filter规则使用脚本来定义规则(根据间隔的开始位置、结束位置和内部间隔计数来筛选间隔),具体如下:
下面的intervals查询中包含一个match规则,规则定义了查询文本为“Fox”,match规则里包含一个filter规则,filter规则使用contained_by参数定义了只查询“Brown Fox”的短语匹配,用其来过滤间隔,具体如下:
下面的intervals查询中包含子intervals,子intervals中包含两个match规则,具体如下:
Elasticsearch Query DSL之全文检索(Full text queries)上篇
全文查询包括如下几种模式:
- match query
- match_phrase query
- match_phrase_prefix query
- multi_match query
- common terms query
- query_string query
- simple_query_string query
接下来我们详细介绍上述查询模式。
1、match query
标准的全文检索模式,包含模糊匹配、前缀或近似匹配等。
2、match_phrase query
与match query类似,但只是用来精确匹配的短语。
3、match_phrase_prefix query
与match_phrase查询类似,但是在最后一个单词上执行通配符搜索。
4、multi_match query
支持多字段的match query。
5、common terms query
相比match query,消除停用词与高频词对相关度的影响。
6、query_string query
查询字符串方式
7、simple_query_string query
简单查询字符串方式
本篇主要介绍前四种全文检索方式。
1、match query详解
1.1 match query使用示例与基本工作原理
全文索引查询,这意外着首先会对待查字符串(查询条件)进行分词,然后再去匹配,返回结果中会待上本次匹配的关联度分数。
例如存在这样一条数据:
"_source":{
"post_date":"2009-11-16T14:12:12",
"message":"trying out Elasticsearch",
"user":"dingw2"
}查询字符串:
"query": {
"match" : {
"message" : "this out Elasticsearch"
}
}其JAVA代码对应:
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchQuery("message", "this out elasticsearch"));其大体步骤如下:
首先对this out Elasticsearch分词,最终返回结果为 this、out、Elasticsearch,然后分别去库中进行匹配,默认只要一个匹配,就认为匹配,但会加入一个匹配程度(关联度),用scoce分数表示。
1.2 match query常用参数详解
- operator(操作类型)
可选值为:Operator.OR 和 Operator.AND。表示对查询字符串分词后,返回的词根列表,OR只需一个满足及认为匹配,而AND则需要全部词根都能匹配,默认值为:Operator.OR。
- minimum_should_match
最少需要匹配个数。在操作类型为Operator.OR时生效,指明分词后的词根,至少minimum_should_match 个词根匹配,则命中。
"match" : {
"message" : "this out Elasticsearch",
“minimum_should_match ”:“3”
}此时由于this词根并不在原始数据"trying out Elasticsearch"中,又要求必须匹配的词根个数为3,故本次查询,无法命中。minimum_should_match 可选值如下: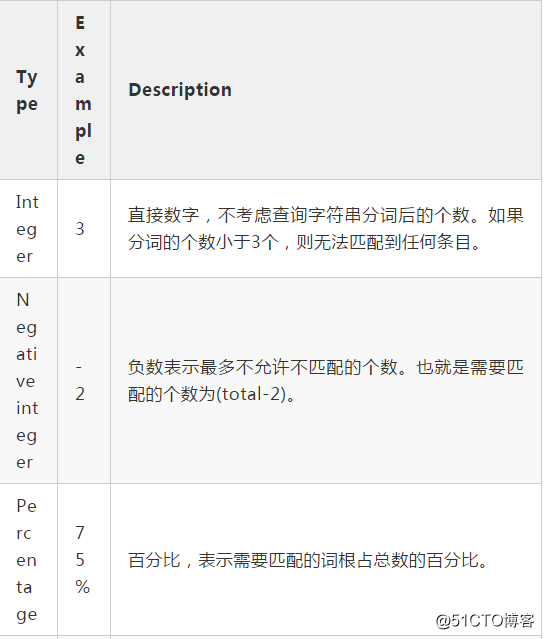

-
analyzer
设置分词器,默认使用字段映射中定义的分词器或elasticsearch默认的分词器。 -
lenient
是否忽略由于数据类型不匹配引起的异常,默认为false。例如尝试用文本查询字符串查询数值字段,默认会抛出错误。 -
fuzziness
模糊匹配。 -
zero_terms_query
默认情况下,如果分词器会过滤查询字句中的停用词,可能会造成查询字符串分词后变成空字符串,此时默认的行为是无法匹配到任何文档,如果想改变该默认情况,可以设置zero_terms_query=all,类似于match_all,默认值为none。 -
cutoff_frequency
match查询支持cutoff_frequency,允许指定绝对或相对的文档频率: -
OR:高频单词被放入“或许有”的类别,仅在至少有一个低频(低于cutoff_frequency)单词满足条件时才积分;
- AND:高频单词被放入“或许有”的类别,仅在所有低频(低于cutoff_frequency)单词满足条件时才积分。该查询允许在运行时动态处理停用词而不需要使用停用词文件。它阻止了对高频短语(停用词)的评分/迭代,并且只在更重要/更低频率的短语与文档匹配时才会考虑这些文档。然而,如果所有查询条件都高于给定的cutoff_frequency,则查询将自动转换为纯连接(and)查询,以确保快速执行。
cutoff_frequency取值是相对于文档的总数的小数[0..1),也可以是绝对值[1, +∞)。
- Synonyms(同义词)
可在分词器中定义同义词,具体同义词将在后续章节中会单独介绍。
1.3 match query示例
public static void testMatchQuery() {
RestHighLevelClient client = EsClient.getClient();
try {
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("twitter");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(
QueryBuilders.matchQuery("message", "is out Elasticsearch")
.zeroTermsQuery(ZeroTermsQuery.ALL)
.operator(Operator.OR)
.minimumShouldMatch("4<90%")
).sort(new FieldSortBuilder("post_date").order(SortOrder.DESC))
.docValueField("post_date", "epoch_millis");
searchRequest.source(sourceBuilder);
SearchResponse result = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(result);
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
2、match_phrase query
与match query类似,但只是用来精确匹配的短语。
其主要工作流程:
首先,Elasearch(lucene)会使用分词器对全文本进行分词(返回一个一个的词根(顺序排列)),然后同样使用分词器对查询字符串进行分析,返回一个一个的词根(顺序性)。如果能在全字段中能够精确找到与查询字符串通用的词根序列,则认为匹配,否则认为不匹配。
举例如下:
如果原文字段message:"quick brown fox test we will like to you",则使用标准分词器(analyzer=standard)返回的结果如下:
使用命令:
curl -X GET "192.168.1.10:9200/_analyze" -H ‘Content-Type: application/json‘ -d‘
{
"tokenizer" : "standard",
"text" : "quick brown fox test we will like to you",
"attributes" : ["keyword"]
}‘得出如下结果:
{
"tokens":[
{
"token":"quick",
"start_offset":0,
"end_offset":5,
"type":"<ALPHANUM>",
"position":0
},
{
"token":"brown",
"start_offset":6,
"end_offset":11,
"type":"<ALPHANUM>",
"position":1
},
{
"token":"fox",
"start_offset":12,
"end_offset":15,
"type":"<ALPHANUM>",
"position":2
},
{
"token":"test",
"start_offset":16,
"end_offset":20,
"type":"<ALPHANUM>",
"position":3
},
{
"token":"we",
"start_offset":21,
"end_offset":23,
"type":"<ALPHANUM>",
"position":4
},
{
"token":"will",
"start_offset":24,
"end_offset":28,
"type":"<ALPHANUM>",
"position":5
},
{
"token":"like",
"start_offset":29,
"end_offset":33,
"type":"<ALPHANUM>",
"position":6
},
{
"token":"to",
"start_offset":34,
"end_offset":36,
"type":"<ALPHANUM>",
"position":7
},
{
"token":"you",
"start_offset":37,
"end_offset":40,
"type":"<ALPHANUM>",
"position":8
}
]
}其词根具有顺序性(词根序列)为quick、brown、fox、test 、we 、will、 like、 to 、you
如果查询字符串为 quick brown,分词后的词根序列为 quick brown,则是原词根序列的子集,则匹配。
如果查询字符串为 quick fox,分词后的词根序列为 quick fox,与原词根序列不匹配。如果指定slop属性,设置为1,则匹配,其表示每一个词根直接跳过一个词根形成新的序列,与搜索词根进行比较,是否匹配。
如果查询字符串为quick fox test,其特点是quick与原序列跳过一个词brown,但fox后面不跳过任何次,与test紧挨着,如果指定slop=1,同样能匹配到文档,但查询字符串quick fox test will,却匹配不到文档,说明slop表示整个搜索词根中为了匹配流,能跳过的最大次数。
按照match_phrase的定义,与match query的区别一个在与精确匹配,一个在于词组term(理解为词根序列),故match_phrase与match相比,不会有如下参数:fuzziness、cutoff_frequency、operator、minimum_should_match 这些参数。
3、match phrase prefix query
与match phrase基本相同,只是该查询模式会对最后一个词根进行前缀匹配。
GET /_search
{
"query": {
"match_phrase_prefix" : {
"message" : {
"query" : "quick brown f",
"max_expansions" : 10
}
}
}
}其工作流程如下:首先先对除最后一个词进行分词,得到词根序列 quick brown,然后遍历整个elasticsearch倒排索引,查找以f开头的词根,依次组成多个词根流,例如(quick brown fox) (quick brown foot),默认查找50组,受参数max_expansions控制,在使用时请设置合理的max_expansions,该值越大,查询速度将会变的更慢。该技术主要完成及时搜索,指用户在输入过程中,就根据前缀返回查询结果,随着用户输入的字符越多,查询的结果越接近用户的需求。
4、multi match query
multi_match查询建立在match查询之上,允许多字段查询。
GET /_search
{
"query": {
"multi_match" : {
"query": "this is a test",
"fields": [ "subject", "message" ] // @1
}
}
}@1执行作用(查询)的字段,有如下几种用法:
1、[ "subject", "message" ] ,表示针对查询自动对subject,message字段进行查询匹配。
2、[ "title", "*name" ],支持通配符,表示对title,以name结尾的字段进行查询匹配。
3、[ "subject^3", "message" ],表示subject字段是message的重要性的3倍,类似于字段权重。
4.1 multi_query重要参数详解
4.1.1 type 属性
指定multi_query内部的执行方式,取值如下:best_fields、most_fields、cross_fields、phrase、phrase_prefix。
1、best_fields
type默认值,只要其中一个字段匹配则匹配文档(match query)。但是使用最佳匹配的字段的score来表示文档的分数,会影响文档的排序。
例如有如下两个文档,id,title,context字段值分别如下:
doc1 : 1 "Quick brown rabbits" "Brown rabbits are commonly seen brown."
doc2:2 "Keeping pets healthy", "My quick brown as fox eats rabbits on a regular basis."如果查询字段“brown fox”字符串,两个文档的匹配度谁高呢?初步分析如下:查询字符串"brown fox"会被分词为brown、fox两个词根,首先brown在doc1的title、context中都能匹配brown,而且次数为3次,在doc2中,只有在context字段中匹配到brown fox各一次,那哪个相关度(评分score)。
best_fields类型,认为在同一个字段能匹配到更多的查询字符串词根,则认为该字段更佳。由于doc2的context字段能匹配到两个查询词根,故doc2的匹配度更高,doc2会优先返回,对应测试代码:
public static void testMultiQueue_best_fields() {
RestHighLevelClient client = EsClient.getClient();
try {
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("esdemo");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(
QueryBuilders.multiMatchQuery("brown fox", "title","context")
.type(Type.BEST_FIELDS)
);
searchRequest.source(sourceBuilder);
SearchResponse result = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(result);
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
执行的查询结果如下:
{
"took":4,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"skipped":0,
"failed":0
},
"hits":{
"total":2,
"max_score":0.5753642,
"hits":[
{
"_index":"esdemo",
"_type":"matchquerydemo",
"_id":"2",
"_score":0.5753642,
"_source":{
"context":"My quick brown as fox eats rabbits on a regular basis.",
"title":"Keeping pets healthy"
}
},
{
"_index":"esdemo",
"_type":"matchquerydemo",
"_id":"1",
"_score":0.2876821,
"_source":{
"context":"Brown rabbits are commonly seen.",
"title":"Quick brown rabbits"
}
}
]
}
}best_fields类型内部会转换为(dis_max):
GET /_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "subject": "brown fox" }},
{ "match": { "message": "brown fox" }}
],
"tie_breaker": 0.3
}
}
}通常best_fields类型使用单个最佳匹配字段的分数,但如果指定了tie_breaker,则其计算结果如下:最佳匹配字段的分数加上 tie_breaker * _score(其他匹配字段分数)。该查询模式支持match query相关的参数,例如analyzer, boost, operator, minimum_should_match, fuzziness, lenient, prefix_length, max_expansions, rewrite, zero_terms_query, cutoff_frequency, auto_generate_synonyms_phrase_query 、fuzzy_transpositions等参数。
best_fields和大多数字段类型都是以字段为中心的——它们为每个字段生成匹配查询。这意味着运算符和minimum_should_match参数将分别应用于每个字段。
2、most_fields
查找匹配任何字段并结合每个字段的_score的文档,Elasticsearch会为每个字段生成一个match查询,然后将它们包含在一个bool查询中。其算法的核心是各个字段的评分相加作为文档的最终得分参与排序。其建议场景是不同字段对同一关键字的存储维度不一样,例如字段一可能包含同义词、词干、变音符等;字段二可能包含原始词根,这种情况下综合各个字段的评分就会显的更加具有相关性。
该查询模式支持match query相关的参数,例如analyzer, boost, operator, minimum_should_match, fuzziness, lenient, prefix_length, max_expansions, rewrite, zero_terms_query, cutoff_frequency, auto_generate_synonyms_phrase_query 、fuzzy_transpositions等参数。
3、phrase、phrase_prefix
这两种类型score的计算采用best_fields方法,但是其查询方式分别为match_phrase、match_phrase_prefix。
4、cross_fields
交叉字段,对于需要匹配多个字段的结构化文档,cross_fields类型特别有用。例如,在查询“Will Smith”的first_name和last_name字段时,在一个字段中可能会有“Will”,而在另一个字段中可能会有“Smith”。这听起来很象most_fields,cross_fields与most_fields的两个明显区别如下:
- 对于opreator、minimum_should_match的作用域不一样,most_fields是针对字段的,(遍历每个字段,然后遍历查询词根列表,进行逐一匹配),而cross_fields是针对词根的,即遍历词根列表,搜索范围是所有字段。
- 相关性的考量不相同,cross_fields重在这个交叉匹配,对于一组查询词根,一部分出现在其中一个字段,另外一部分出现在另外一个字段中,其相关性计算评分将更高。
举例说明:例如有如下查询语句:
{
"query": {
"multi_match" : {
"query": "Will Smith",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}其执行操作时,首先对查询字符串分析得出will、smith两个词根,然后遍历这两个词根,一次对first_name,last_name进行匹配,也就是说opreator、minimum_should_match这些参数作用2次,而most_fields方式,是一个嵌套循环,先遍历字段,然后对每一个词根在该字段上进行匹配,在该示例中,opreator、minimum_should_match这些参数作用4次。
4.1.2 tie_breaker属性
默认情况下,每个词汇混合查询将使用组中任何字段返回的最佳分数,然后将这些分数相加,以给出最终分数。tie_breaker参数可以改变每项混合查询的默认行为。tie_breaker可选值如下:
-
0.0 : 默认行为,使用最佳字段的score。
-
1.0 :所有匹配字段socre的和。
- 0.0 ~ 1.0 : 使用最佳匹配字段的score + (其他匹配字段score) * tie_breaker。
4.1.3 multi_query支持其他match query参数
其他诸如analyzer, boost, operator, minimum_should_match, fuzziness, lenient, prefix_length, max_expansions, rewrite, zero_terms_query, cutoff_frequency, auto_generate_synonyms_phrase_query 、fuzzy_transpositions等参数,multi_query同样支持。
由于篇幅的原因,本节就只介绍全文检索方式的前4种方式,全文检索的其他查询方式将在下一节详细介绍。
更多文章请关注公众号:中间件兴趣圈。

以上是关于Elasticsearch系列(13)Query之全文查询的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch系列(14)Query之地理空间查询
Elasticsearch Query DSL 整理总结—— Match Phrase Query 和 Match Phrase Prefix Query
十三.net core(.NET 6)搭建ElasticSearch(ES)系列之dotnet操作ElasticSearch进行存取的方法
Elasticsearch的javaAPI之query dsl-queries