多目标优化在推荐中的应用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多目标优化在推荐中的应用相关的知识,希望对你有一定的参考价值。
参考技术A 多目标排序通常是指有两个或两个以上的目标函数,寻求一种排序使得所有的目标函数都达到最优或满意。在推荐系统中,大多产品都是基于隐式反馈进行推荐,导致评估用户满意度的时候有不同的偏差:
1)不同目标表达不同的满意程度:在电商应用中,购买行为表达的满意度高于点击、浏览;
2)单个目标衡量不全面:在信息流应用中,仅以点击率为目标,可能会存在标题党;在招聘应用中,仅以投递转化率为目标,可能存在招聘方不活跃或者对候选者不满意度下降。
3)用户表达满意的方式不同:在电商应用中,用户喜欢商品的表达可能会以收藏或者加购的形式,取决于用户偏好;在招聘应用中,招聘方对候选者的满意方式可能以在线沟通、电话沟通、直接面试邀请等形式,取决于招聘方偏好。
推荐系统中有多个业务指标,可以通过一些手段使得多个业务的综合目标收益最大化。比如说,电商场景,希望能够在优化GMV的基础上提高点击率,提高用户粘性;信息流场景,希望提高用户点击率的基础上提高用户关注、点赞、评论等行为,提高留存;招聘场景,希望提高求职者投递转化率的基础上提高招聘方的体验满意度,从而使得双方的满足度均提高。因此推荐系统做到后期,往往会向多目标方向演化,承担起更多的业务目标。
多目标排序问题的解决方案:多模型分数融合、通过样本权重进行多目标优化、排序学习(Learning To Rank,LTR)、多任务学习(Multi-Task Learning,MTL)。
1.多模型分数融合
多模型融合的方式也是比较经典传统的做法,每个目标训练一个模型,每个模型算出一个分数,然后根据自身业务的特点,通过某种方式将这些分数综合起来,计算出一个总的分数再进行排序,综合分数的计算通常会根据不同目标的重要性设定相应的参数来调节。
最常见的是weighted sum融合多个目标,给不同的目标分配不同的权重。当然,融合的函数可以有很多,比如连乘或者指数相关的函数,可以根据自己面临的场景不断去探索。
1.1 规则公式法
以电商推荐系统为例,假定有五个预估目标,分别是点击率 CTR、购买转化率 CVR、收藏率 collect,加购率 cart、停留时长 stay,这五个目标分别对应五个模型,排序阶段的作用就是利用模型根据各自目标来给候选 Item 计算一个预估值(分数),排序阶段结束每个 Item 都会有五个不同的目标预估分数,如何用这些分数进行融合,是交给下一个流程--重排序模块来处理的。
分数融合的一种思路是利用一个带参数公式来实现,如下:
有了公式,那么超参数(α,β,a,b,c 等)如果进行学习获取?目前工业界就是人工调参,通过线上AB实验不断调整参数,一个很繁琐的工作。
1.2 线性回归法
如果经验公式,我们很容易想到的一种思路是类似于集成学习中一种多模型融合方法 Stacking,即将多个目标模型预估出的结果作为输入,然后用一个简单的线性回归进行线性加权融合,学习到各个目标的权重,这样我们就可以预估综合分数了。但是我们却忽略了一个重要的问题,该如何设置样本的 Label 呢?事实上,并没有一个真实的综合分数可供我们去训练学习,因此,这种办法很难真正去实现。而在工业界,更多的做法是人工调试,但如此又会带来很多问题,比如模型灵活度不够。
2.样本权重(sample weight)
如果主目标是点击率,分享功能是我们希望提高的功能。那么点击和分享都是正样本(分享是点击行为的延续),分享的样本可以设置更高的样本权重。模型训练在计算梯度更新参数时,对于sample weight大的样本,如果预测错误就会带来更大的损失,梯度要乘以权重。通过这种方法能够在优化点击率的基础上,优化分享率。实际AB测试会发现,这样的方法,目标点击率会受到一定的损失换取目标分享率的增长。通过线上AB测试和sample weight调整的联动,可以保证在可接受的A目标损失下,优化目标B,实现初级的多目标优化。
优点:模型简单,仅在训练时通过梯度上乘sample weight实现对某些目标的boost或者decay带有sample weight的模型和线上的base模型完全相同,不需要架构的额外支持。
缺点:本质上没有对多目标的建模,而是将不同的目标折算成同一个目标。折算的程度需要多次AB测试才能确定。
3. 排序学习(Learning To Rank,LTR)
多模型融合中我们通过模型计算预估值或者是综合打分,其根本目的是为了给推荐物品排序,而不是真正的打分。因此我们可以使用排序学习方法来解决多目标问题。再由于是多个目标,可以排除pointwise方案,可以考虑pairwise和listwise方案。具体,模型可以考虑 BPR 或者 LambdaMART 等算法。
相比多模型融合中 Label 标注,排序学习模型的的 Label 标注相对更容易一点,因为只关心相对关系,而不需要真实的打分数据。一种常见的标注方法是对多目标产生的物品构建 Pair,比如用户对物品 i产生的购买,对物品j产生了点击,假定我们觉得购买的目标比点击的目标更重要,就可以让i>uj,其他目标以此类推。有了顺序对后,我们便可以训练排序学习模型,这样一个模型便可以融合多个目标,而不用训练多个模型。
4. 多任务学习(Multi-Task Learning,MTL)
4.1 概念
多任务学习是基于共享表示,把多个相关的任务放在一起学习的一种机器学习方法。多任务学习涉及多个相关的任务同时并行学习,梯度同时反向传播,利用包含在相关任务训练信号中的特定领域的信息来改进泛化能力。
一般来说,优化多个损失函数就等同于进行多任务学习。 即使只优化一个损失函数,也有可能借助辅助任务来改善原任务模型。
多任务学习的前提条件:多个任务之间必须具有相关性以及拥有可以共享的底层表示。
在多任务学习的定义中,共享表示是一个非常重要的限定,个人认为共享表示对于最终任务的学习有两类作用:
促进作用——通过浅层的共享表示互相分享、互相补充学习到的领域相关信息,从而互相促进学习,提升对信息的穿透和获取能力;
约束作用——在多个任务同时进行反向传播时,共享表示则会兼顾到多个任务的反馈,由于不同的任务具有不同的噪声模式,所以同时学习多个任务的模型就会通过平均噪声模式从而学习到更一般的表征,这个有点像正则化的意思,因此相对于单任务,过拟合风险会降低,泛化能力增强。
因此在深度神经网络中,执行多任务学习有两种最常用的方法:
参数的硬共享机制
共享 Hard 参数是神经网络 MTL 最常用的方法。在实际应用中, 通常通过在所有任务之间共享隐藏层,同时保留几个特定任务的输出层来实现, 如下图所示:
共享 Hard 参数大大降低了过拟合的风险。
参数的软共享机制
共享 Soft 参数,每个任务都有自己的参数和模型。模型参数之间的距离是正则化的,以便鼓励参数相似化,例如使用 L2 距离进行正则化。
多任务学习之所以有效,是因为多任务学习的方式引入了归纳偏置(inductive bias),归纳偏置有两个效果:
1)互相促进,可以把多任务模型之间的关系看作是互相先验知识,也称归纳迁移(inductive transfer),有了对模型的先验假设,可以更好的提升模型的效果;
2)约束作用,借助多任务间的噪声平衡以及表征偏置来实现更好的泛化性能。
4.2 主流多任务学习模型
主流模型有ESMM模型、EMS2模型、MMoE模型等。本文以阿里ESMM模型为例进行介绍。
用户的行为可以抽象为一个序列模式:浏览 -> 点击 -> 购买。
CVR 是指从点击到购买的转化,传统的 CVR 预估会存在两个问题:样本选择偏差和稀疏数据。
样本选择偏差:模型用户点击的样本来训练,但是预测却是用的整个样本空间。
数据稀疏问题:用户点击到购买的样本太少。
ESMM是一个多任务学习模型,它同时学习学习点击率和转化率两个目标,即模型直接预测展现转换(pCTCVR):单位流量获得成交的概率,把 pCVR 当做一个中间变量,模型结构如下 :
该网络结构共有三个子任务,分别用于输出 pCTR、pCVR 和 pCTCVR。
对于 pCTR 来说可将有点击行为的曝光事件作为正样本,没有点击行为的曝光事件作为负样本,对于 PCTCVR 来说,将同时有点击行为和购买行为的曝光事件作为正样本,其他作为负样本。上面公式可以转化为
我们可以通过分别估计pCTCVR和pCTR,然后通过两者相除来解决。而pCTCVR和pCTR都可以在全样本空间进行训练和预估。但是这种除法在实际使用中,会引入新的问题。因为在预测阶段pCTR其实是一个很小的值,范围一般在百分之几,预估时会出现pCTCVR>pCTR的情况,导致pCVR预估值大于1。ESMM巧妙的通过将除法改成乘法来解决上面的问题。
它引入了pCTR和pCTCVR两个辅助任务,训练时,loss为两者相加。
在CTR有点击行为的展现事件构成的样本标记为正样本,没有点击行为发生的展现事件标记为负样本;在CTCVR任务中,同时有点击和购买行为的展现事件标记为正样本,否则标记为负样本。
另外两个子网络的 embedding 层是共享的,由于 CTR 任务的训练样本量要远超过 CVR 任务的训练样本量,ESMM 模型中 embedding 层共享的机制能够使得 CVR 子任务也能够从只有展现没有点击的样本中学习,从而能够极缓解训练数据稀疏性问题。
MTL可以使得多个模型特性互相弥补:点击率预估模型善于学习表面特征,其中包括标题党,图片带来的点击诱惑;而转化模型学习更深层的特征,比如体验、服务质量。
4.3构建所有loss的pareto
多任务学习本质上是一个多目标问题,因为不同任务之间可能产生冲突,需要对其进行取舍。
帕累托最优所指的情况要求有多个优化目标,指的是不能在不损失其他目标的情况下优化一个目标。
4.3.1 Multi-Task Learning as Multi-Objective Optimization
定义如下:
优化目标:
5.多目标优化实践
【参考文献】
1. https://arxiv.org/pdf/1810.04650v1.pdf Multi-Task Learning as Multi-Objective Optimization
2.
遗传算法学习--多目标优化中的遗传算法
转:https://www.cnblogs.com/lomper/p/3831428.html
在工程运用中,经常是多准则和对目标的进行择优设计。解决含多目标和多约束的优化问题称为:多目标优化问题。经常,这些目标之间都是相互冲突的。如投资中的本金最少,收益最好,风险最小~~
多目标优化问题的一般数学模型可描述为:
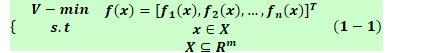
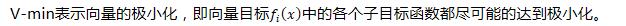
Pareto最优解(Pareto Optimal Solution)
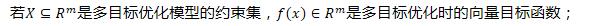
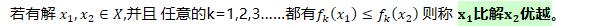
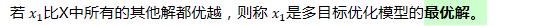

使用遗传算法进行求解Pareto最优解:
- 权重系数变换法:

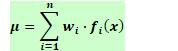

- 并列选择法:
基本思想:
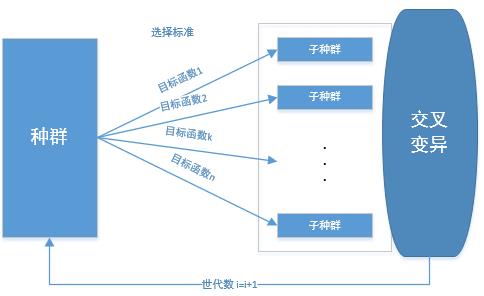
将种群全体按子目标函数的数目等分为子群体,对每一个子群体分配一个目标函数,进行择优选择,各自选择出适应度高的个体组成一个新的子群体,然后将所有这些子群体合并成一个完整的群体,在这个群体里进行交叉变异操作,生成下一代完整群体,如此循环,最终生成Pareto最优解。如下图:
- 排列选择法:
基于Pareto最优个体的前提上,对群体中的各个个体进行排序,依据排序进行选择,从而使拍在前面的Pareto最优个体将有更大的可能性进入下一代群体中。
- 共享函数法:
利用小生境遗传算法的技术。算法对相同个体或类似个体是数目加一限制,以便能够产生出种类较多的不同的最优解。
对于一个个体X,在它的附近还存在有多少种、多大程度相似的个体,是可以度量的,这种度量值称为小生境数。计算方法:
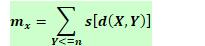
s(d)为共享函数,它是个体之间距离d的单调递减函数。d(X,Y)为个体X,Y之间的海明距离。
在计算出小生境数后,可以是小生境数较小的个体能够有更多的机会被选中,遗传到下一代群体中,即相似程度较小的个体能够有更多的机会被遗传到下一代群体中。
解决了多目标最优化问题中,使解能够尽可能的分散在整个Pareto最优解集合内,而不是集中在其Pareto最优解集合内的某一个较小的区域上的问题。
- 混合法:
- 并列选择过程:按所求多目标优化问题的子目标函数的个数,将整个群体均分为一些子群体,各个子目标函数在相应的子群体中产生其下一代子群体。
- 保留Pareto最优个体过程:对于子群体中的Pareto最优个体,不让其参与个体的交叉和变异运算,而是直接保留到下一代子群体中。
- 共享函数处理过程:若所得到的Pareto最优个体的数量已经超过规定的群体规模,则使用共享函数来对它们进行挑选,以形成规定规模的新一代群体。
以上是关于多目标优化在推荐中的应用的主要内容,如果未能解决你的问题,请参考以下文章