如何加速Oracle大批量数据处理?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何加速Oracle大批量数据处理?相关的知识,希望对你有一定的参考价值。
参考技术A 一、 提高DML操作的办法:\\x0d\\x0a简单说来:\\x0d\\x0a1、暂停索引,更新后恢复.避免在更新的过程中涉及到索引的重建.\\x0d\\x0a2、批量更新,每更新一些记录后及时进行提交动作.避免大量占用回滚段和或临时表空间.\\x0d\\x0a3、创建一临时的大的表空间用来应对这些更新动作.\\x0d\\x0a\\x0d\\x0a4、批量更新,每更新一些记录后及时进行提交动作.避免大量占用回滚段和或临时表空间.\\x0d\\x0a\\x0d\\x0a5、创建一临时的大的表空间用来应对这些更新动作.\\x0d\\x0a\\x0d\\x0a6、加大排序缓冲区\\x0d\\x0a alter session set sort_area_size=100000000;\\x0d\\x0a insert into tableb select * from tablea;\\x0d\\x0a commit;\\x0d\\x0a\\x0d\\x0a如果UPDATE的是索引字段,就会涉及到索引的重建,暂停索引不会提高多少的速度,反而有可能降低UPDATE速度,\\x0d\\x0a因为在更新是索引可以提高数据的查询速度,重建索引引起的速度降低影响不大。\\x0d\\x0a\\x0d\\x0aORACLE优化修改参数最多也只能把性能提高15%,大部分都是SQL语句的优化!\\x0d\\x0a\\x0d\\x0aupdate总体来说比insert要慢 :\\x0d\\x0a几点建议: \\x0d\\x0a 1、如果更新的数据量接近整个表,就不应该使用index而应该采用全表扫描 \\x0d\\x0a 2、减少不必要的index,因为update表通常需要update index \\x0d\\x0a 3、如果你的服务器有多个cpu,采用parellel hint,可以大幅度的提高效率\\x0d\\x0a 另外,建表的参数非常重要,对于更新非常频繁的表,建议加大PCTFREE的值,以保证数据块中有足够的空间用于UPDATE, 从而降低CHAINED_ROWS。 \\x0d\\x0a\\x0d\\x0a二、 各种批量DML操作:\\x0d\\x0a(1)、oracle批量拷贝:\\x0d\\x0aset arraysize 20\\x0d\\x0a set copycommit 5000\\x0d\\x0a copy from username/password@oraclename append table_name1\\x0d\\x0a using select * from table_name2;\\x0d\\x0a (2)、常规插入方式:\\x0d\\x0a insert into t1 select * from t;\\x0d\\x0a 为了提高速度可以使用下面方法,来减少插入过程中产生的日志:\\x0d\\x0a alter table t1 nologging;\\x0d\\x0ainsert into t1 select * from t;\\x0d\\x0acommit;\\x0d\\x0a (3)、CTAS方式:\\x0d\\x0a create table t1\\x0d\\x0aas\\x0d\\x0aselect * from t;\\x0d\\x0a为了提高速度可以使用下面方法,来减少插入过程中产生的日志,并且可以制定并行度:\\x0d\\x0acreate table t1 nologging parallel(degree 2) as select * from t;\\x0d\\x0a (4)、Direct-Path插入:\\x0d\\x0a insert /*+append*/ into t1 select * from t;\\x0d\\x0a commit;\\x0d\\x0a 为了提高速度可以使用下面方法,来减少插入过程中产生的日志:\\x0d\\x0a alter table t1 nologging;\\x0d\\x0a insert /*+append*/ into t1 select * from t;\\x0d\\x0a \\x0d\\x0a Direct-Path插入特点:\\x0d\\x0a1、 append只在insert ? select ?中起作用,像insert /*+ append */ into t values(?)这类的语句是不起作用的。在update、delete操作中,append也不起作用。\\x0d\\x0a2、 Direct-Path会使数据库不记录直接路径导入的数据的重做日志,会对恢复带来麻烦。\\x0d\\x0a3、 Direct-Path直接在表段的高水位线以上的空白数据块中写数据,不会重用高水位线以下的空间,会对空间的使用造成一定的浪费,对查询的性能也会造成一定的影响。而常规插入会优先考虑使用高水位线之下有空闲空间存在的数据块。因此理论上Direct-Path插入会比常规插入速度更快,因为Direct-Path直接使用新数据块,而常规插入要遍历freelist获取可用空闲数据块,如果同 nologging 配合,这种速度优势会更加明显。\\x0d\\x0a4、 以append方式插入记录后,要执行commit,才能对表进行查询。否则会出现错误:ORA-12838: 无法在并行模式下修改之后读/修改对象。\\x0d\\x0a5、 用append导入数据后,如果没有提交或者回滚,在其他会话中任何对该表的DML都会被阻塞(不会报错),但对该表的查询可以正常执行。\\x0d\\x0a6、 在归档模式下,要把表设置为nologging,然后以append方式批量添加记录,才会显著减少redo数量。在非归档模式下,不必设置表的 nologging属性,即可减少redo数量。如果表上有索引,则append方式批量添加记录,不会减少索引上产生的redo数量,索引上的redo 数量可能比表的redo数量还要大。\\x0d\\x0a7、 数据直接插入数据文件,绕过buffer cache并且忽略了引用完整性约束。\\x0d\\x0a8、 不管表是否在nologging 下,只要是 direct insert,就不会对数据内容生成undo。\\x0d\\x0a9、 Oracle在Direct-Path INSERT 操作末尾,对具有索引的表执行索引维护,这样就避免了在drop掉索引后,再rebuild。\\x0d\\x0a10、 Direct-Path INSERT比常规的插入需要更多的空间。因为它将数据插入在高水位之上。并行插入非分区表需要更多的空间,因为它需要为每一个并行线程创建临时段。\\x0d\\x0a11、 在插入期间,数据库在表上获得排他锁,用户不能在表上执行并行插入、更新或者删除操作,并行的索引创建和build也不被允许。但却可以并行查询,但查询返回的是插入之前的结果集。\\x0d\\x0a (5)、并行DML:\\x0d\\x0a 如果你的服务器有多个cpu,采用parellel hint,可以大幅度的提高效率\\x0d\\x0a ALTER SESSION ENABLE PARALLEL DML;\\x0d\\x0a\\x0d\\x0a INSERT /*+ PARALLEL(tableA, 2) */INTO tableA \\x0d\\x0a SELECT * FROM tableB;\\x0d\\x0a\\x0d\\x0a 为了提高速度可以使用下面方法,来减少插入过程中产生的日志:\\x0d\\x0a\\x0d\\x0a INSERT /*+ PARALLEL(tableA, 2) */INTO tableA NOLOGGING\\x0d\\x0a SELECT * FROM tableB;\\x0d\\x0a\\x0d\\x0aoracle默认并不会打开PDML,对DML语句必须手工启用。即需要执行\\x0d\\x0aalter table enable parallel dml命令。\\x0d\\x0a \\x0d\\x0a并行DML特点:\\x0d\\x0a1、在并行DML模式中,默认的就是DIRECT-PATH插入,为了运行并行DML模式,必须满足以下条件:\\x0d\\x0aa、必须是Oracle企业版;\\x0d\\x0ab、必须在session中使并行DML生效,执行以下sql语句:\\x0d\\x0aALTER SESSION ENABLE | FORCE PARALLEL DML;\\x0d\\x0ac、必须指定table的并行属性,在创建的时候或者其他时候,或者在insert操作时使用“PARALLEL”提示。\\x0d\\x0ad、为了使Direct-Path Insert模式失效,在INSERT语句中指定“NOAPPEND”提示,覆盖并行DML模式。\\x0d\\x0a 2、并行Direct-Path INSERT到分区表:\\x0d\\x0a 类似于serial Direct-Path INSERT,每个并行操作分配给一个或者多个分区,每个并行操作插入数据到各自的分区段的高水位标志之上,commit之后,用户就能看到更新的数据。\\x0d\\x0a 3、并行Direct-Path INSERT到非分区表:\\x0d\\x0a 每个并行执行分配一个新的临时段,并插入数据到临时段。当commit运行后,并行执行协调者合并新的临时段到主表段,用户就能看到更新的数据。\\x0d\\x0a 4、Direct-Path INSERT可以使用Log或者不使用Log。\\x0d\\x0a 5、另外不得不说的是,并行不是一个可扩展的特性,只有在数据仓库或作为DBA等少数人的工具在批量数据操作时利于充分利用资源,而在OLTP环境下使用并行需要非常谨慎。事实上PDML还是有比较多的限制的,例如不支持触发器,引用约束,高级复制和分布式事务等特性,同时也会带来额外的空间占用,PDDL同 样是如此。oracle数据库字段内容如何批量替换?
oracle数据库字段内容如何让符合条件的内容批量替换?
我的数据库里表As_user字段名uflag里的内容0,要改成1,请问这个语句要怎么写?
还有就是想请教一下如果想查询表as_user字段名uflag里的内容为0和1的句子怎么写。
请高手请教下!!
条件是:字段名uflag里的内容为0的,要全部改成1
直接用update语句替换即可。
如test表中有如下数据:

现要将sal中的数字都替换成10,用以下语句:
commit;
更新后结果:
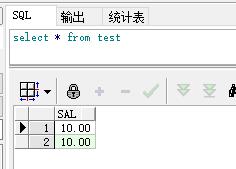
注意:执行update语句后,需要进行commit,也就是提交,这样才会使update生效。
select * from as_user where uflag in(0,1) order by uflag;本回答被提问者采纳
以上是关于如何加速Oracle大批量数据处理?的主要内容,如果未能解决你的问题,请参考以下文章