我输入一个数字,想在awk里执行命令,把变量变为2进制,该如何做?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我输入一个数字,想在awk里执行命令,把变量变为2进制,该如何做?相关的知识,希望对你有一定的参考价值。
不用awk的方法示例:echo "ibase=10;obase=2; 123" | bc
则会输出1111011
其中ibase表示输入的进制,obase表示输出的进制,123就是你要转化的十进制数,
使用awk的方法,因为awk中有十进制、八进制、十六进制的格式化输出,恰好没有二进制的,所以需要自己转化一下,其中一种方法如下:
echo 235 | awk 'BEGINm[0]="000";m[1]="001";m[2]="010";m[3]="011";m[4]="100";m[5]="101";m[6]="110";m[7]="111" s = sprintf("%o",$0); for(i=1;i<=length(s);i++) printf ("%s", m[substr(s,i,1)]); printf("\n");'
前面的echo 235 就是把输入送给awk程序,235就是想要转化的十进制数,上面结果的输出为011101011
注意前置的0没有去掉,若想要去掉,可以考虑后面在对01串稍微处理一下。 参考技术A 使用printf打印,打印的每一位都按照转换格式转换好。 参考技术B 你是想输出这个二进制数呢,还是按位存储起来?写详细一点啦
shell命令三剑客之awk命令详解,cut命令,linux里记录行踪(操作记录)
1. 初识awk命令
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
AWK名字的来源:取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
shell命令三剑客的比较:
grep更适合单纯的查找或匹配文本;
sed更适合编辑匹配到的文本;
awk更适合格式化文本,对文本进行较复杂格式处理。
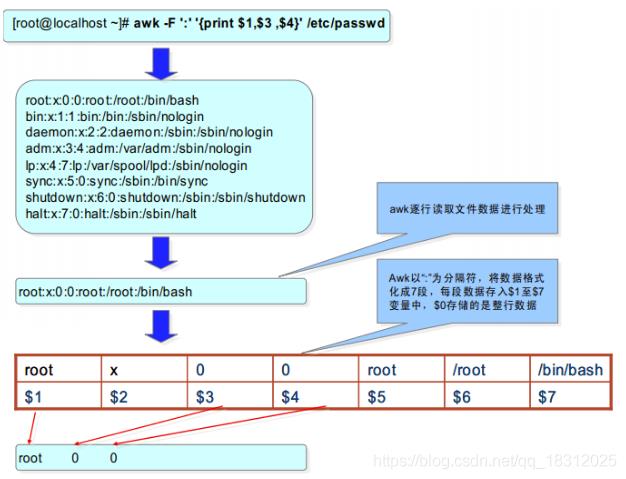
1.1 awk工作原理
awk命令与sed一样, 均是一行一行的读取、处理 。
sed作用于一整行的处理, 而awk将一行分成数个字段来处理 。
awk工作流程可分为三个部分:
读输入文件之前执行的代码段(由BEGIN关键字标识);
主循环执行输入文件的代码段;
读输入文件之后的代码段(由END关键字标识)。
图解:awk命令的简要处理流程:
- 执行BEGIN{commands}语句块中的语句;
- 从文件或stdin中读取第1行;
- 有无模式匹配,,若无则执行{}中的语句;
- 若有则检查该整行与pattern是否匹配,若匹配,则执行{}中的语句;
- 若不匹配则不执行{}中的语句,接着读取下一行;
- 重复这个过程,,直到所有行被读取完毕;
- 执行END{commands}语句块中的语句。
1.2 语法和参数说明
awk命令的完整语法
awk [选项参数] ‘BEGIN{commands} pattern{commands} END{commands}‘ file
选项参数:
-F 指定输入文件折分隔符,后面是一个字符串或者是一个正则表达式,如-F:。
-v 赋值一个用户定义变量。
-f 从脚本文件中读取awk命令。
-mf nnn and -mr nnn 对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
-W compact or --compat, -W traditional or --traditional 在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
-W copyleft or --copyleft, -W copyright or --copyright 打印简短的版权信息。
-W help or --help, -W usage or --usage 打印全部awk选项和每个选项的简短说明。
-W lint or --lint 打印不能向传统unix平台移植的结构的警告。
-W lint-old or --lint-old 打印关于不能向传统unix平台移植的结构的警告。
-W posix 打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符和=不能代替和=;fflush无效。
-W re-interval or --re-inerval 允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
-W source program-text or --source program-text 使用program-text作为源代码,可与-f命令混用。
-W version or --version 打印bug报告信息的版本。
简单例子:
例子:
# cat passwd|awk -F: ‘BEGIN{print "############"}$3<100{print $1,$3,$6}END{print "@@@@@@@@@@@@@@"}‘
############
root 0 /root
dbus 81 /
rpc 32 /var/cache/rpcbind
rpcuser 29 /var/lib/nfs
haldaemon 68 /
postfix 89 /var/spool/postfix
mysql 27 /var/lib/mysql
@@@@@@@@@@@@@@
1.3 awk基本用法
用法一:
awk ‘/模式/{动作}‘ 文件 #行匹配语句 awk ‘‘ 只能用单引号
awk的指令一定要用单引号括起。
awk的动作一定要用花括号括起。
模式可以是正则表达式、条件表达式或两种组合。
如果模式是正则表达式要用/定界符。
多个动作之间用分号分开。
分隔符在awk里有2种:
1.输入分隔符 -F指定
2.输出分隔符 OFS=
例子:
例1:只有模式时,相当于grep。
# cat passwd|awk ‘/liu/‘
liu1:x:508:508::/home/liu1:/bin/bash
liu2:x:509:509::/home/liu2:/bin/bash
例2:只有动作时,就直接执行动作。
# who|awk ‘{print $2}‘
tty1
pts/0
# who
root tty1 2016-06-24 23:20
root pts/0 2016-06-24 23:21 (liupeng.lan)
用法二:-F指定分隔符。
awk -F #指定分割字符
例1:输出以h开头的行的第一列和第七列。
# cat passwd|awk -F: ‘/^h/{print $1,$7}‘
haldaemon /sbin/nologin
例4:显示不是以h开头的行的第一列和第七列
awk -F: ‘/^[^h]/{print $1,$7}‘ /etc/passwd
例5:以冒号或者左斜杠作为分隔符显示第1列和第10列。
awk -F‘[:/]‘ ‘{print $1,$10}‘ /etc/passwd
用法三:设置变量。
awk -v #设置变量
例1:
# name=haha
# echo|awk -v abc=$name ‘{print abc,$name}‘
haha
# echo|awk -v abc=$name ‘{print $name}‘
# echo|awk -v abc=$name ‘{print abc}‘
haha --》引用awk变量无需加$
例2:
# name=haha;soft=xixi
# echo|awk -v abc=$name -v efg=$soft ‘{print abc,123}‘
haha 123
用法四:-f 脚本。
awk -f 脚本 文件名
1.4 awk命令的操作符
正则表达式和bash一致。
数学运算:+,-,*,/, %,++,--
逻辑关系符:&&, ||, !
比较操作符:>,<,>=,!=,<=,==,~(匹配正则表达式),!~(不匹配正则表达式)
文本数据表达式:== (精确匹配)
~波浪号表示匹配后面的模式
例1:在$2里查找匹配/pts/的,有就输出$1。
# who | awk ‘$2 ~ /pts/{$1}‘
例2:输出uid为两位的用户名和uid。
< 以什么开头。
>以什么结尾。
..正则里代表两个字符。
[root@liupeng ~]# cat passwd|awk -F: ‘$3 ~/<..>/{print $1,$3}‘
uucp 10
operator 11
games 12
gopher 13
......
[root@liupeng ~]#
例3:输出1~10能被5整除的或者以1开头的数字。
[root@liupeng ~]# seq 10 | awk ‘$1 % 5 == 0 || $1 ~ /^1/{print $1}‘
1
5
10
[root@liupeng ~]#
例4:显示uid大于等于50并且家目录在/home下同时shell为bash结尾的用户名,uid,家目录,shell。
[root@liupeng ~]# cat passwd|awk -F: ‘$3>=50 && $6 ~/^/home/ && $7 ~/bash/ {print $1,$3,$6,$7}‘
mysql 496 /home/mysql /bin/bash
[root@liupeng ~]#
例5:查找出用户名里包含liu的用户,输出用户名和uid及shell。
# cat passwd|awk -F‘:‘ ‘$1 ~/liu/{print $1,$3,$6}‘
liu1 508 /home/liu1
liu2 509 /home/liu2
liu3 510 /home/liu3
liu4 511 /home/liu4
liu5 512 /home/liu5
liu 539 /home/liu
例6:查找出/etc/passwd文件里用户名包含liu并且使用bash的用户。
# cat passwd|awk -F‘:‘ ‘$1 ~/liu/&&$7 ~/bash/{print $1,$7}‘
liu1 /bin/bash
liu2 /bin/bash
liu3 /bin/bash
liu4 /bin/bash
liu5 /bin/bash
liu /bin/bash
1.5 awk命令的内置变量
$0表示整行文本;
$n表示文本中第n个数据字段;
NF:number of field,表示一行里有多少字段;
NR:number of record,表示当前处理的行号;
FS:field separater,输入分隔符。默认为空白(空格和Tab);
OFS:out field separater,表示输出分隔符,输出时用指定的符号代替换行符;
ARGC 命令行参数的数目;
ARGIND 命令行中当前文件的位置(从0开始算);
ARGV 包含命令行参数的数组;
CONVFMT 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组;
ERRNO 最后一个系统错误的描述;
FIELDWIDTHS 字段宽度列表(用空格键分隔);
FILENAME 当前文件名;
FNR 各文件分别计数的行号;
IGNORECASE 如果为真,则进行忽略大小写的匹配;
OFMT 数字的输出格式(默认值是%.6g);
ORS 输出记录分隔符(默认值是一个换行符);
RLENGTH 由match函数所匹配的字符串的长度;
RS 记录分隔符(默认是一个换行符);
RSTART 由match函数所匹配的字符串的第一个位置;
SUBSEP 数组下标分隔符(默认值是/034)。
例1:显示/etc/passwd文件的行数。
[root@liupeng ~]# cat /etc/passwd|awk ‘BEGIN{i=0}{i++} END{print i}‘
35
[root@liupeng ~]#
分析:每取一行,i++。最后i的值就正好是passwd文件的行数。
例2:以默认分隔符,显示每行的字段数目。
[root@liupeng ~]# awk ‘{print NF}‘ /etc/passwd
1
1
1
1
......
[root@liupeng ~]#
(此处因为未指定分隔符,所以是默认分隔符为空格,自然很多字段数目为1的了。)
以冒号为分隔符,显示每行的字段数目。
[root@liupeng ~]# awk -F: ‘{print NF}‘ /etc/passwd
7
7
7
......
[root@liupeng ~]#
(指定了分隔符了,就是7咯)
例3:显示每行的第一字段和最后一个字段。
awk -F: ‘{print $1,$NF}‘ /etc/passwd
例4:显示每行的行号和内容。
[root@liupeng ~]# awk -F: ‘{print NR,$0}‘ /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
......
[root@liupeng ~]#
例5:显示第一列和第七列,中间用---隔开
awk -F: ‘BEGIN{OFS="---"}{print $1,$7}‘ /etc/passwd
简单写法:
[root@liupeng ~]# awk -F: ‘OFS="---"{print $1,$7}‘ /etc/passwd
root---/bin/bash
bin---/sbin/nologin
daemon---/sbin/nologin
......
[root@liupeng ~]#
例6:显示以bash为结尾的用户名和所在的行号,最后显示总行号。
[root@liupeng ~]# awk ‘BEGIN{FS=":"} /bash$/{print NR,$1} END{print NR}‘ /etc/passwd
1 root
35 mysql
35
[root@liupeng ~]#
例7:显示文件的3到5行(行号,内容)。
[root@liupeng ~]# awk ‘NR==3,NR==5{print NR,$0}‘ /etc/passwd
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@liupeng ~]#
显示4或7行(带行号,带内容)。
[root@liupeng ~]# awk ‘NR==4||NR==7{print NR,$0}‘ /etc/passwd
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
[root@liupeng ~]#
例8:显示文件的前3行(带行号,带内容)。
[root@liupeng ~]# awk ‘NR<=3{print NR,$0}‘ /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@liupeng ~]#
例9:显示文件的前10行和30到40行。
# awk ‘NR<=10||NR>30&&NR<=40{print NR,$0}‘ /etc/passwd
例10:显示passwd文件的第5行和第10行的行号和用户名。
[root@liupeng ~]# cat passwd|awk -F: ‘NR==5||NR==10{print NR,$1}‘
5 lp
10 uucp
[root@liupeng ~]#
例11:
1.分析下面三条命令的区别,为什么。
①
#awk ‘BEGIN{print NR}‘ /etc/passwd (执行一次)
[root@liupeng ~]# awk ‘BEGIN{print NR}‘ /etc/passwd
0
[root@liupeng ~]#
②
#awk ‘{print NR}‘ /etc/passwd (执行N次,N为行数)
(一直到35(最后一行))
[root@liupeng ~]# awk ‘{print NR}‘ /etc/passwd
1
2
3
......
35
[root@liupeng ~]#
③#awk ‘END{print NR}‘ /etc/passwd (执行一次,结果为文件的行数)
[root@liupeng ~]# awk ‘END{print NR}‘ /etc/passwd
35
[root@liupeng ~]#
2.分析下面命令的执行结果
①#awk -F: ‘{print $NR}‘/etc/passwd
(解析:第1行去第1个字段,第2行取第2个字段,第n行去第n个字段......)
②#awk -F: ‘{print NR, NF, $1, $NF, $(NF-1)}‘ /etc/passwd
(输出每行的行号,字段数,用户名,最后一个字段,倒数第二个字段)
[root@liupeng ~]# awk -F: ‘{print NR, NF, $1, $NF, $(NF-1)}‘ /etc/passwd
1 7 root /bin/bash /root
2 7 bin /sbin/nologin /bin
3 7 daemon /sbin/nologin /sbin
......
35 7 mysql /bin/bash /home/mysql
[root@liupeng ~]#
1.5.1 awk内置变量小练习:
1.使用NF变量显示passwd文件倒数第二列的内容。
cat passwd|awk -F: ‘{print $(NF-1)}‘
2.显示passwd文件中第5到第10行的用户名。
cat passwd|awk -F: ‘NR>=5&&NR<=10{print $1}‘
3.显示passwd文件中第7列不是bash的用户名。
cat passwd|awk -F: ‘$7 ~/[^bash]$/{print $1}‘
或者:
cat passwd|awk -F: ‘$7 !~/bash/{print $1}‘
4.显示passwd文件中行号是5结尾的行号和行。
cat passwd|awk -F: ‘NR%10==5{print NR,$0}‘
或者:
cat passwd|awk -F: ‘NR ~/5$/{print NR,$0}‘
5.用ifconfig只显示ip(不能使用tr或者cut命令)。
[root@liupeng ~]# ifconfig|awk -F: ‘/inet addr/{print $2}‘|awk ‘{print $1}‘
192.168.28.129
127.0.0.1
[root@liupeng ~]#
或者:
ifconfig |sed -n ‘/inet addr/p‘|awk -F[:" "] ‘{print $13}‘
6.使用awk显示eth0的入站流量和出站流量(字节)。
ifconfig eth0|awk -F‘[: ]‘ ‘/RX bytes/{print $13,$19}‘
或
ifconfig eth0|tr -s ‘ ‘|awk -F‘[: ]‘ ‘/RX bytes/{print $4,$9 }‘
7.使用awk命令统计以r开头的用户数目,显示如下效果。
查找结果
root
rpc
rtkit
rpcuser
4
[root@liupeng ~]# cat passwd|awk -F: ‘BEGIN{print "查找结果";i=0}/^r/{print $1;i++}END{print i}‘
查找结果
root
rpc
rtkit
rpcuser
4
[root@liupeng ~]#
1.6 awk命令的内置函数
awk编程语言内置了很多函数。
1.6.1 length函数
例1:利用length计算字符数目的函数来检查有无空口令用户。
awk -F: ‘length($2)==0{print $1}‘ /etc/passwd /etc/shadow
例2:显示文件中超过50个字符的行。
awk ‘length($0)>50{print NR,$0}‘ /etc/passwd
1.6.2 system函数
例1:利用system函数给文件中的用户配置密码。
# cat list.txt
xixi 123
haha 456
hehe 789
# awk ‘{system("useradd $1");print $1 "is add"}‘ list.txt
# awk ‘{system("echo "$2"|passwd --stdin "$1)}‘ list.txt
例2:利用awk的system命令在/tmp/lp下建立/etc/passwd中与用户名同名的目录 。
mkdir /tmp/lp/
awk -F: ‘{system("mkdir /tmp/lp/" $1)}‘ /etc/passwd
例3:用1条命令实现将指定目录下大于10K的对象复制到/tmp下(禁止使用find 和for) 。
cp $(du -a /boot | awk ‘$1>10240{print $2}‘) /tmp
1.7 awk命令的结构化语句
1.7.1 if语句
1.单分支
[root@liupeng ~]# awk -F: ‘{if($1 ~ /<...>/)print $0}‘ /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
gdm:x:42:42::/var/lib/gdm:/sbin/nologin
[root@liupeng ~]#
[root@liupeng ~]# awk -F: ‘{if($3 >= 500)print $1,$7}‘ /etc/passwd
nfsnobody /sbin/nologin
[root@liupeng ~]#
2.双分支
awk -F: ‘{if($3 != 0) print $1 ; else print $3}‘ /etc/passwd
3.多分支
awk -F: ‘{if($1=="root") print $1;else if($1=="ftp") print $2;else if($1=="mail") print $3;else print NR}‘ /etc/passwd
例2:利用awk的if多重分支判断用户的类型,root显示为管理员,uid在(0,500)显示为系统用户,uid在[500,60000]之间显示为普通用户,大于6万显示为其他用户。
[root@liupeng ~]# awk -F: ‘{if($3==0) print $1,"管理员";else if($3>0 && $3<500) print $1,"系统用户";else if($3>=500 && $3 <= 60000) print $1,"普通用户";else print $1,"其它用户"}‘ /etc/passwd
root 管理员
bin 系统用户
......
mysql 系统用户
[root@liupeng ~]#
补充:
三种获得uid大于500小于10000的方法:
# cat /etc/passwd|awk -F: ‘$3>500&&$3<10000{print $1,$3}‘
# cat /etc/passwd|awk -F: ‘($3>500&&$3<10000){print $1,$3}‘
# cat /etc/passwd|awk -F: ‘{if($3>500&&$3<10000)print $1,$3}‘
练习:监控多台主机的磁盘分区一旦某台被监控主机的任一分区使用率大于80%, 就给root发邮件报警。
#!/bin/bash
warn=10
ip=(10.10.10.2 10.10.10.3)
for i in "${ip[@]}"
do
ssh root@$i df -Ph | tr -s " "|awk -v w=10 -F "[ %]" ‘/^/dev/{if($5>w) print $1,$5"% useage is over 10%"}‘>
alert
if [ -s alert ]
then
sed -i "1i $i" alert && mail -s "$i hd usage" root < alert
fi
done
练习:检查/var/log/secure日志文件,如果有主机用root用户连接服务器的ssh服务失败次数超过10次(10次必须使用变量),就将这个IP地址加入/etc/hosts.deny文件拒绝其访问,如果这个IP已经存在就无需重复添加到/etc/hosts.deny文件(要求使用awk语句进行字符过滤、大小判断和变量赋值,禁止使用echo、sed、grep、cut、tr命令)
#/bin/bash
awk ‘/Failed password for root/{print $(NF-3)}‘ /var/log/secure|sort -nr| uniq -c > test --》sort 按降序排序,uniq -c统计次数
NUM=10
IP=$(awk ‘$1>num {print $2}‘ num=$NUM test) --》$1就是统计好的次数
for i in $IP
do
DENY=$(awk ‘$2==var {print $2}‘ var=$i /etc/hosts.deny)
if [[ -z $DENY ]]
then
awk ‘$2==var {print "sshd: "$2}‘ var=$i test >> /etc/hosts.deny
awk ‘$2==var {print "错误次数"$1,"拒绝"$2"访问"}‘ var=$i test
else
awk ‘$2==var {print "已经拒绝"$2"访问"}‘ var=$i test
fi
done
1.7.2 awk对行和列的累加
1.awk进行列求和
统计/etc目录下以.conf结尾的文件的总大小。
[root@liupeng ~]# find /etc/ -type f -name "*.conf" |xargs ls -l | awk ‘{sum+=$5} END{print sum}‘
522341
[root@liupeng ~]#
- 如果要匹配第一列的才累加,需要用到awk的数组和for循环(难点)。
cat xferlog | awk ‘{print $7,$8}‘ | sort -n >/lianxi/123.txt
awk ‘{a[$1]+=$2}END{for(i in a) print i,a[i]}‘/lianxi/123.txt | sort -rn -k2
a[$1]=a[$1]+$2
【xferlog是ftp服务器上的一个日志文件!】
【awk里的数组支持shell里讲的关联数组!!】
【sort -rn -k2是统计出下载量最大的ip并排序】
3 awk进行行求和。
例1:求1~5的累加和。
# echo 1 2 3 4 5 | awk ‘{for(i=1;i<=NF;i++) sum+=$i; print sum}‘
15
例2:求1~100的累加和。
# seq -s ‘ ‘ 100 | awk ‘{for(i=1;i<=NF;i++) sum+=$i; print sum}‘
5050
1.8 怎么理解awk里面的数组是关联数组:
1.8.1 awk里如何使用数组来存放数据?
1.将所有的/etc/passwd所有的用户存放在user数组里。
cat /etc/passwd|awk -F: ‘{user[$1]}‘
解析:此时user[root]里面没有值,只是下标或者说索引变成了user[用户名]。
cat /etc/passwd|awk -F: ‘{user[$1]=$3}‘
解析:此时,将$3的值(也就是uid)赋给user[$1]数组。
这样,就把用户和用户对应的uid关联起来了,用户名做下标关键字,uid做数组元素对应的值。
1.8.2 awk里如何从数组里取出数据?
将user数组里的所有值取出来:
# cat /etc/passwd|awk -F: ‘{user[$1]=$3}END{for(i in user)print user[i],i}‘
42 gdm
38 ntp
32 rpc
......
1.8.3 awk里关联数组的理解(难点):
{a[$1]+=$2}
将$1对应的字段作为下标,将$2对应字段赋值给下标为$1对应的字段的元素。awk每读取一行就执行一次,重新又将$1对应的字段作为下标,执行a[$1]=a[$1]+$2,将上一行的a[$1]的值加上第2行$2值,实现累加的效果。$1对应的字段还是那个字段,但是值已经累加了。
适用情景:某一列不变,而对应的另一列的内容不同的场景。
小练习:
统计每个人总共花了多少钱,并按总金额降序排序。
money.txt:
feng 100
feng 200
feng 360
li 100
li 150
zhang 90
zhang 88
# cat money.txt|awk ‘{username[$1]+=$2}END{for(i in username)print i,username[i]}‘|sort -nr -k2
feng 660
li 250
zhang 178
1.8.4 awk里的关联数组之if判断
例:将/etc/passwd里的所有的用户的uid存放到一个数组,如果用户输入的用户名在数组里,就输出这个用户对应的uid。用户名做下标;uid做元素值。
cat vim awk_user.sh:
[root@liupeng lp]# cat awk_user.sh
#!/bin/bash
read -p "Please input the username:" u_name
cat /etc/passwd|awk -v U_name=$u_name -F: ‘{user[$1]=$3}END{if (U_name in user)print user[U_name]}‘
[root@liupeng lp]#
[root@liupeng lp]# sh awk_user.sh
Please input the username:root
0
[root@liupeng lp]# sh awk_user.sh
Please input the username:zhao
[root@liupeng lp]#
2. cut命令
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
cut 的参数:
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除。
3. linux里记录行踪(操作记录)的地方
①history -c
②~/.bash_history
③/var/log/secure
④/var/log/lastlog
⑤/var/log/wtmp

以上是关于我输入一个数字,想在awk里执行命令,把变量变为2进制,该如何做?的主要内容,如果未能解决你的问题,请参考以下文章