Python数据分析案例-药店销售数据分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析案例-药店销售数据分析相关的知识,希望对你有一定的参考价值。
参考技术A最近学习了Python数据分析的一些基础知识,就找了一个药品数据分析的小项目来练一下手。
数据分析的目的:
本篇文章中,假设以朝阳医院2018年销售数据为例,目的是了解朝阳医院在2018年里的销售情况,通过对朝阳区医院的药品销售数据的分析,了解朝阳医院的患者的月均消费次数,月均消费金额、客单价以及消费趋势、需求量前几位的药品等。
数据分析基本过程包括:获取数据、数据清洗、构建模型、数据可视化以及消费趋势分析。
数据准备
数据是存在Excel中的,可以使用pandas的Excel文件读取函数将数据读取到内存中,这里需要注意的是文件名和Excel中的sheet页的名字。读取完数据后可以对数据进行预览和查看一些基本信息。
获取数据:朝阳医院2018年销售数据.xlsx(非真实数据) 提取码: 6xm2
导入原始数据
数据准备
数据是存在Excel中的,可以使用pandas的Excel文件读取函数将数据读取到内存中,这里需要注意的是文件名和Excel中的sheet页的名字。读取完数据后可以对数据进行预览和查看一些基本信息。
获取数据:朝阳医院2018年销售数据.xlsx(非真实数据) 提取码: 6xm2
导入原始数据
数据清洗
数据清洗过程包括:选择子集、列名重命名、缺失数据处理、数据类型转换、数据排序及异常值处理
(1)选择子集
在我们获取到的数据中,可能数据量非常庞大,并不是每一列都有价值都需要分析,这时候就需要从整个数据中选取合适的子集进行分析,这样能从数据中获取最大价值。在本次案例中不需要选取子集,暂时可以忽略这一步。
(2)列重命名
在数据分析过程中,有些列名和数据容易混淆或产生歧义,不利于数据分析,这时候需要把列名换成容易理解的名称,可以采用rename函数实现:
(3)缺失值处理
获取的数据中很有可能存在缺失值,通过查看基本信息可以推测“购药时间”和“社保卡号”这两列存在缺失值,如果不处理这些缺失值会干扰后面的数据分析结果。
缺失数据常用的处理方式为删除含有缺失数据的记录或者利用算法去补全缺失数据。
在本次案例中为求方便,直接使用dropna函数删除缺失数据,具体如下:
(4)数据类型转换
在导入数据时为了防止导入不进来,会强制所有数据都是object类型,但实际数据分析过程中“销售数量”,“应收金额”,“实收金额”,这些列需要浮点型(float)数据,“销售时间”需要改成时间格式,因此需要对数据类型进行转换。
可以使用astype()函数转为浮点型数据:
在“销售时间”这一列数据中存在星期这样的数据,但在数据分析过程中不需要用到,因此要把销售时间列中日期和星期使用split函数进行分割,分割后的时间,返回的是Series数据类型:
此时时间是没有按顺序排列的,所以还是需要排序一下,排序之后索引会被打乱,所以也需要重置一下索引。
其中by:表示按哪一列进行排序,ascending=True表示升序排列,ascending=False表示降序排列
先查看数据的描述统计信息
通过描述统计信息可以看到,“销售数量”、“应收金额”、“实收金额”这三列数据的最小值出现了负数,这明显不符合常理,数据中存在异常值的干扰,因此要对数据进一步处理,以排除异常值的影响:
数据清洗完成后,需要利用数据构建模型(就是计算相应的业务指标),并用可视化的方式呈现结果。
月均消费次数 = 总消费次数 / 月份数(同一天内,同一个人所有消费算作一次消费)
月均消费金额 = 总消费金额 / 月份数
客单价 = 总消费金额 / 总消费次数
从结果可以看出,每天消费总额差异较大,除了个别天出现比较大笔的消费,大部分人消费情况维持在1000-2000元以内。
接下来,我销售时间先聚合再按月分组进行分析:
结果显示,7月消费金额最少,这是因为7月份的数据不完整,所以不具参考价值。
1月、4月、5月和6月的月消费金额差异不大.
2月和3月的消费金额迅速降低,这可能是2月和3月处于春节期间,大部分人都回家过年的原因。
d. 分析药品销售情况
对“商品名称”和“销售数量”这两列数据进行聚合为Series形式,方便后面统计,并按降序排序:
截取销售数量最多的前十种药品,并用条形图展示结果:
结论:对于销售量排在前几位的药品,医院应该时刻关注,保证药品不会短缺而影响患者。得到销售数量最多的前十种药品的信息,这些信息也会有助于加强医院对药房的管理。
每天的消费金额分布情况:一横轴为时间,纵轴为实收金额画散点图。
结论: 从散点图可以看出,每天消费金额在500以下的占绝大多数,个别天存在消费金额很大的情况。
</article>
数据分析实战 | 探寻销售额下降的原因
大家好,我是丁小杰。
本文案例的来源为《数据分析实战》一书,书中使用的是 R 语言,接下来一段时间,我会用 Python + Tableau 尽可能的将案例复现出来,以供大家学习。
场景描述
某公司经营的一款 APP 小游戏,每月销售额稳定上涨,但是在 7 月却突然下降,无论从市场环境或是游戏本身的环境来看,这个游戏的销售额都还有继续增长的空间
,影响该游戏销售额的主要影响因素可能有两点:
- 游戏活动上新
- 商业宣传力度更改
经了解发现
- 游戏活动与上月活动并无较大改变
- 由于预算紧缺,宣传力度有所下降
接下来我们会根据数据分析来证实上述结论,并提出恢复销售额的方法。
数据描述
DAU(Daily Active User)
每天至少来访 1 次的用户数据,139112 行。
| 字段 | 类型 | 含义 |
|---|---|---|
| log_date | str | 访问时间 |
| app_name | str | 应用名 |
| user_id | numpy.int64 | 用户 ID |
DPU(Daily Payment User)
每天至少消费 1 日元的用户数据(0.056 元),884 行。
| 字段 | 类型 | 含义 |
|---|---|---|
| log_date | str | 访问时间 |
| app_name | str | 应用名 |
| user_id | numpy.int64 | 用户 ID |
| payment | numpy.int64 | 消费金额 |
Install
记录每个用户首次登录游戏的时间,29329 行。
| 字段 | 类型 | 含义 |
|---|---|---|
| install_date | str | 首次登录时间 |
| app_name | str | 应用名 |
| user_id | numpy.int64 | 用户 ID |
数据分析
数据读取
读取三个数据集。
import pandas as pd
DAU_data = pd.read_csv('DAU.csv')
DPU_data = pd.read_csv('DPU.csv')
install_data = pd.read_csv('install.csv')
显示 DAU 数据集前五行。
DAU_data.head()
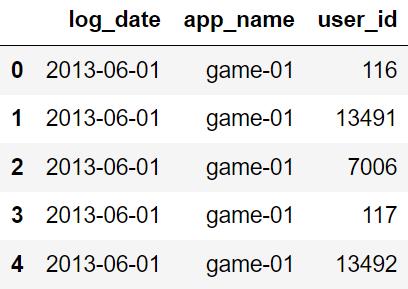
显示 DPU 数据集前五行。
DPU_data.head()
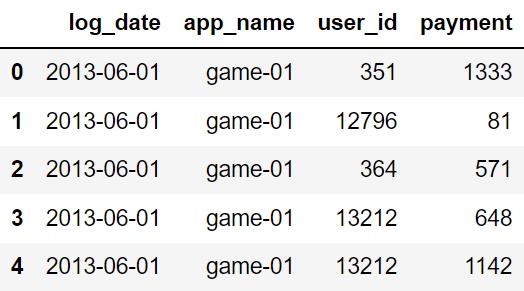
显示 Install 数据集前五行。
install_data.head()
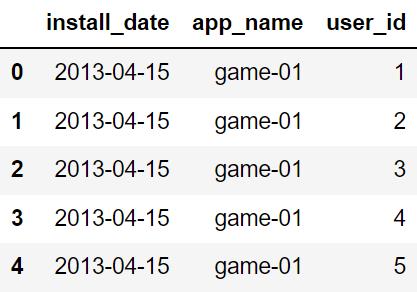
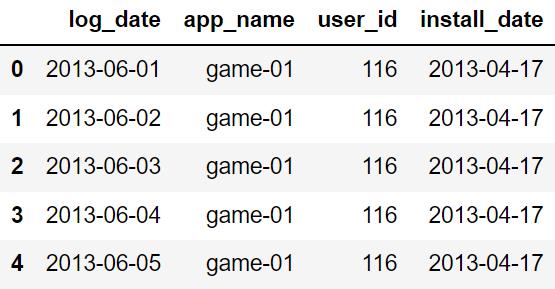
数据合并
将每日活跃用户数据 DAU 与用户首次登录数据 Install 进行合并,将 user_id 与
app_name 作为参照 key。这样就可以得到用户的首次登录时间。
all_data = pd.merge(DAU_data,
install_data,
on=['user_id', 'app_name'])
all_data.head()
得到用户首次登录时间后,再与每日消费用户数据 DPU 进行合并,使用左连接的方式,保留 all_data 中的所有数据,缺失值默认为 NaN。
all_data = pd.merge(all_data,
DPU_data,
on=['log_date', 'app_name', 'user_id'],
how='left')
all_data.head()
数据处理
将 payment 列中的空值填充为 0。
all_data['payment'] = all_data['payment'].fillna('0')
all_data
将 payment 列的单位转换为元,log_date 与 install_date 都只保留月份即可。
all_data['payment'] = all_data['payment'].astype(float)
all_data['payment'] = all_data['payment'] * 0.056
all_data['log_date'] = pd.to_datetime(all_data['log_date']).map(lambda x : x.strftime("%m")[1] + '月')
all_data['install_date'] = pd.to_datetime(all_data['install_date']).map(lambda x : x.strftime("%m")[1] + '月')
all_data.head()
新老用户划分
将 登录月份 > 首次登录月份 的用户定义为老用户,其他则定义为新用户。
all_data['user'] = all_data['log_date'] > all_data['install_date']
all_data['user'] = all_data['user'].map(False: '新用户', True: '老用户')
all_data.head()
按照 log_date, user 分组对 payment 求和,统计各月新老用户的带来的销售额。
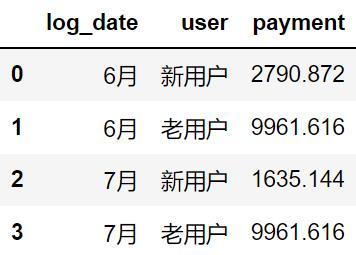
user_category = all_data.groupby(['log_date', 'user'])['payment'].sum().reset_index()
user_category.head()
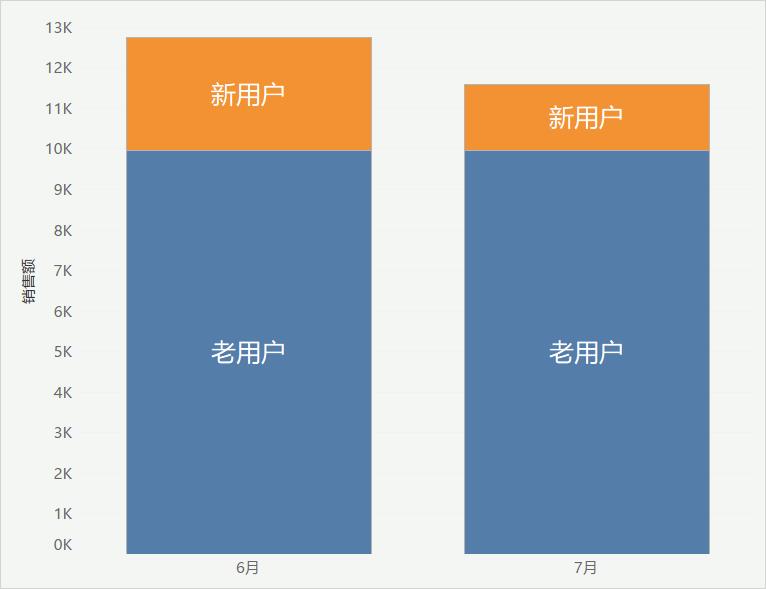
可以看到 6 月和 7 月的老用户带来的销售额基本相同,但 7 月新用户带来的销售额明显少于 6 月。
将销售额划分区域,看看哪个层次的用户消费在减少。
import numpy as np
sale_df = all_data.loc[all_data['payment'] > 0, ['log_date', 'payment']].copy()
bins = list(range(0, 101, 30)) + [np.inf]
labels = [str(n) + '-' + str(n + 30) for n in bins[:-2]] + ['>90']
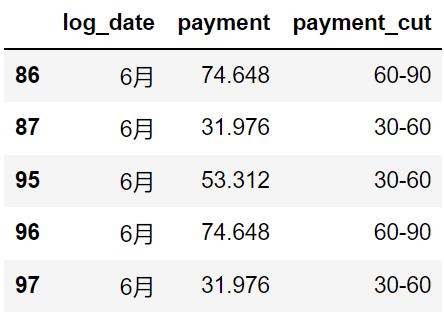
sale_df['payment_cut'] = sale_df['payment'].apply(lambda x : pd.cut([x], bins=bins, labels=labels)[0])
sale_df.head()
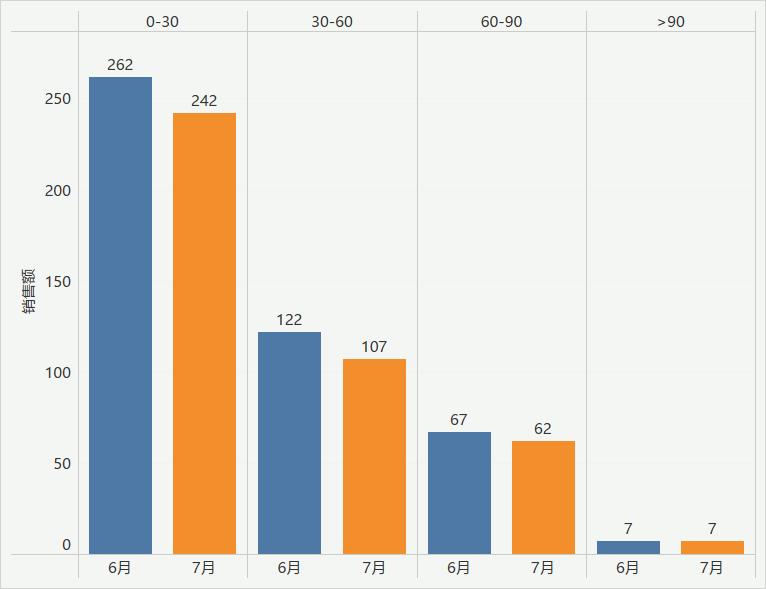
根据上面柱状图可以看出,和 6 月相比,7 月消费额在 60 元以下的用户数量减少了一部分。
到此我们就可以得到一些结论。
结论
新用户中的产生消费的用户发生了减少,特别是消费金额较少的小额消费用户。因此,公司需要再次开展商业宣传活动并恢复到之前的水平,这样才有可能提升潜在用户对公司产品的认知度,增加新的用户。
案例参考
[1]《数据分析实战》 [日] 酒卷隆志 里洋平/著 肖峰/译
对于刚入门 Python 或是想要入门 Python 的小伙伴,可以通过下方小卡片联系作者,一起交流学习,都是从新手走过来的,有时候一个简单的问题卡很久,但可能别人的一点拨就会恍然大悟,由衷的希望大家能够共同进步。另有整理的近千套简历模板,几百册电子书等你来领取哦!
以上是关于Python数据分析案例-药店销售数据分析的主要内容,如果未能解决你的问题,请参考以下文章