请问JAVA中正则表达式匹配怎么实现的!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了请问JAVA中正则表达式匹配怎么实现的!相关的知识,希望对你有一定的参考价值。
String s=new String("0.0.0.0 0.255.255.255 CHINA 中国1");
String s1=s.replaceFirst("([0-9])\\s+ ","\1, ");
这样子在JAVA中实现不了,我是想把上面的字符串数字后的空格改为逗号,不知道在JAVA怎么实现,哪位高手能指点迷津!
不好意思,可能上面的String s=new String("0.0.0.0 0.255.255.255 CHINA 中国1"); 里面的空格不是很明显,意思就是把0.0.0.0后面的几个空格和0.255.255.255后面的几个空格换成逗号,而CHINA后面的空格不变,就是CHINA 中国1为一个字符串的!
Java中正则表达式匹配的语法规则:
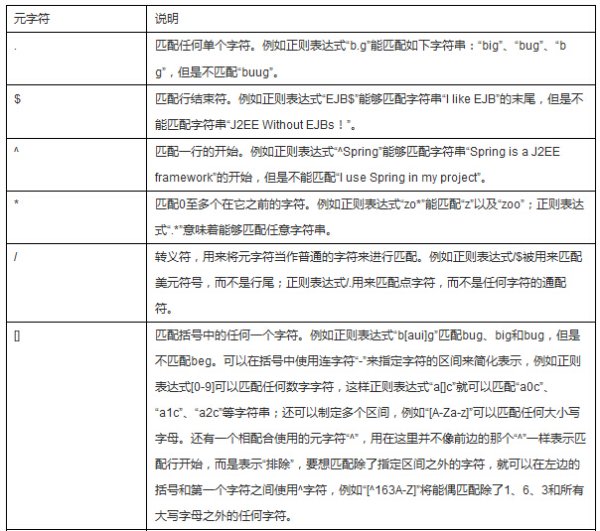

以下是整理出来的Java下运用正则表达式实现匹配的程序案例,代码如下:
package org.luosijin.test;import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 正则表达式
* @version V5.0
* @author Admin
* @date 2015-7-25
*/
public class Regex
/**
* @param args
* @author Admin
* @date 2015-7-25
*/
public static void main(String[] args)
Pattern pattern = Pattern.compile("b*g");
Matcher matcher = pattern.matcher("bbg");
System.out.println(matcher.matches());
System.out.println(pattern.matches("b*g","bbg"));
//验证邮政编码
System.out.println(pattern.matches("[0-9]6", "200038"));
System.out.println(pattern.matches("//d6", "200038"));
//验证电话号码
System.out.println(pattern.matches("[0-9]3,4//-?[0-9]+", "02178989799"));
getDate("Nov 10,2009");
charReplace();
//验证身份证:判断一个字符串是不是身份证号码,即是否是15或18位数字。
System.out.println(pattern.matches("^//d15|//d18$", "123456789009876"));
getString("D:/dir1/test.txt");
getChinese("welcome to china,江西奉新,welcome,你!");
validateEmail("luosijin123@163.com");
/**
* 日期提取:提取出月份来
* @param str
* @author Admin
* @date 2015-7-25
*/
public static void getDate(String str)
String regEx="([a-zA-Z]+)|//s+[0-9]1,2,//s*[0-9]4";
Pattern pattern = Pattern.compile(regEx);
Matcher matcher = pattern.matcher(str);
if(!matcher.find())
System.out.println("日期格式错误!");
return;
System.out.println(matcher.group(1)); //分组的索引值是从1开始的,所以取第一个分组的方法是m.group(1)而不是m.group(0)。
/**
* 字符替换:本实例为将一个字符串中所有包含一个或多个连续的“a”的地方都替换成“A”。
*
* @author Admin
* @date 2015-7-25
*/
public static void charReplace()
String regex = "a+";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher("okaaaa LetmeAseeaaa aa booa");
String s = matcher.replaceAll("A");
System.out.println(s);
/**
* 字符串提取
* @param str
* @author Admin
* @date 2015-7-25
*/
public static void getString(String str)
String regex = ".+/(.+)$";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(str);
if(!matcher.find())
System.out.println("文件路径格式不正确!");
return;
System.out.println(matcher.group(1));
/**
* 中文提取
* @param str
* @author Admin
* @date 2015-7-25
*/
public static void getChinese(String str)
String regex = "[//u4E00-//u9FFF]+";//[//u4E00-//u9FFF]为汉字
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(str);
StringBuffer sb = new StringBuffer();
while(matcher.find())
sb.append(matcher.group());
System.out.println(sb);
/**
* 验证Email
* @param email
* @author Admin
* @date 2015-7-25
*/
public static void validateEmail(String email)
String regex = "[0-9a-zA-Z]+@[0-9a-zA-Z]+//.[0-9a-zA-Z]+";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(email);
if(matcher.matches())
System.out.println("这是合法的Email");
else
System.out.println("这是非法的Email");
参考技术A java中正则表达式的匹配其实是利用不确定的有穷自动机(NFA)结合向上追溯的算法来实现的。
以下是示例代码:
import java.util.* ;
/*
* An NFAState is a node with a set of outgoing edges to other
* NFAStates.
*
* There are two kinds of edges:
*
* (1) Empty edges allow the NFA to transition to that state without
* consuming a character of input.
*
* (2) Character-labelled edges allow the NFA to transition to that
* state only by consuming the character on the label.
*
*/
class NFAState
/*
* WARNING:
*
* The maximum integer character code we'll match is 255, which
* is sufficient for the ASCII character set.
*
* If we were to use this on the Unicode character set, we'd get
* an array index out-of-bounds exception.
*
* A ``proper'' implementation of this would not use arrays but
* rather a dynamic data structure like Vector.
*/
public static final int MAX_CHAR = 255 ;
public boolean isFinal = false ;
private ArrayList<NFAState> onChar[] = new ArrayList[MAX_CHAR] ;
private ArrayList<NFAState> onEmpty = new ArrayList() ;
/*
* Add a transition edge from this state to next which consumes
* the character c.
*/
public void addCharEdge(char c, NFAState next)
onChar[(int)c].add(next) ;
/*
* Add a transition edge from this state to next that does not
* consume a character.
*/
public void addEmptyEdge(NFAState next)
onEmpty.add(next) ;
public NFAState ()
for (int i = 0; i < onChar.length; i++)
onChar[i] = new ArrayList() ;
public boolean matches(String s)
return matches(s,new ArrayList()) ;
private boolean matches(String s, ArrayList visited)
/*
* When matching, we work character by character.
*
* If we're out of characters in the string, we'll check to
* see if this state if final, or if we can get to a final
* state from here through empty edges.
*
* If we're not out of characters, we'll try to consume a
* character and then match what's left of the string.
*
* If that fails, we'll ask if empty-edge neighbors can match
* the entire string.
*
* If that fails, the match fails.
*
* Note: Because we could have a circular loop of empty
* transitions, we'll have to keep track of the states we
* visited through empty transitions so we don't end up
* looping forever.
*/
if (visited.contains(this))
/* We've found a path back to ourself through empty edges;
* stop or we'll go into an infinite loop. */
return false ;
/* In case we make an empty transition, we need to add this
* state to the visited list. */
visited.add(this) ;
if (s.length() == 0)
/* The string is empty, so we match this string only if
* this state is a final state, or we can reach a final
* state without consuming any input. */
if (isFinal)
return true ;
/* Since this state is not final, we'll ask if any
* neighboring states that we can reach on empty edges can
* match the empty string. */
for (NFAState next : onEmpty)
if (next.matches("",visited))
return true ;
return false ;
else
/* In this case, the string is not empty, so we'll pull
* the first character off and check to see if our
* neighbors for that character can match the remainder of
* the string. */
int c = (int)s.charAt(0) ;
for (NFAState next : onChar[c])
if (next.matches(s.substring(1)))
return true ;
/* It looks like we weren't able to match the string by
* consuming a character, so we'll ask our
* empty-transition neighbors if they can match the entire
* string. */
for (NFAState next : onEmpty)
if (next.matches(s,visited))
return true ;
return false ;
/*
* Here, an NFA is represented by an entry state and an exit state.
*
* Any NFA can be represented by an NFA with a single exit state by
* creating a special exit state, and then adding empty transitions
* from all final states to the special one.
*
*/
public class NFA
public NFAState entry ;
public NFAState exit ;
public NFA(NFAState entry, NFAState exit)
this.entry = entry ;
this.exit = exit;
public boolean matches(String str)
return entry.matches(str);
/*
* c() : Creates an NFA which just matches the character `c'.
*/
public static final NFA c(char c)
NFAState entry = new NFAState() ;
NFAState exit = new NFAState() ;
exit.isFinal = true ;
entry.addCharEdge(c,exit) ;
return new NFA(entry,exit) ;
/*
* e() : Creates an NFA which matches the empty string.
*/
public static final NFA e()
NFAState entry = new NFAState() ;
NFAState exit = new NFAState() ;
entry.addEmptyEdge(exit) ;
exit.isFinal = true ;
return new NFA(entry,exit) ;
/*
* rep() : Creates an NFA which matches zero or more repetitions
* of the given NFA.
*/
public static final NFA rep(NFA nfa)
nfa.exit.addEmptyEdge(nfa.entry) ;
nfa.entry.addEmptyEdge(nfa.exit) ;
return nfa ;
/*
* s() : Creates an NFA that matches a sequence of the two
* provided NFAs.
*/
public static final NFA s(NFA first, NFA second)
first.exit.isFinal = false ;
second.exit.isFinal = true ;
first.exit.addEmptyEdge(second.entry) ;
return new NFA(first.entry,second.exit) ;
/*
* or() : Creates an NFA that matches either provided NFA.
*/
public static final NFA or(NFA choice1, NFA choice2)
choice1.exit.isFinal = false ;
choice2.exit.isFinal = false ;
NFAState entry = new NFAState() ;
NFAState exit = new NFAState() ;
exit.isFinal = true ;
entry.addEmptyEdge(choice1.entry) ;
entry.addEmptyEdge(choice2.entry) ;
choice1.exit.addEmptyEdge(exit) ;
choice2.exit.addEmptyEdge(exit) ;
return new NFA(entry,exit) ;
/* Syntactic sugar. */
public static final NFA re(Object o)
if (o instanceof NFA)
return (NFA)o ;
else if (o instanceof Character)
return c((Character)o) ;
else if (o instanceof String)
return fromString((String)o) ;
else
throw new RuntimeException("bad regexp") ;
public static final NFA or(Object... rexps)
NFA exp = rexps[0] ;
for (int i = 1; i < rexps.length; i++)
exp = or(exp,re(rexps[i])) ;
return exp ;
public static final NFA s(Object... rexps)
NFA exp = e() ;
for (int i = 0; i < rexps.length; i++)
exp = s(exp,re(rexps[i])) ;
return exp ;
public static final NFA fromString(String str)
if (str.length() == 0)
return e() ;
else
return s(re(str.charAt(0)),fromString(str.substring(1))) ;
public static void main(String[] args)
NFA pat = s(rep(or("foo","bar")),"") ;
String[] strings =
"foo" , "bar" ,
"foobar", "farboo", "boofar" , "barfoo" ,
"foofoobarfooX" ,
"foofoobarfoo" ,
;
for (String s : strings)
System.out.println(s + "\t:\t" +pat.matches(s)) ;
详细参考:http://matt.might.net/articles/implementation-of-nfas-and-regular-expressions-in-java/ 参考技术B 正则表达式是匹配响应的字符串,但这个字符串可能比较复杂,用一般的表达可能不是很清晰,简单点说就是正则表达式表达的东西无二义性,
从你的:
String s=new String("0.0.0.0 0.255.255.255 CHINA 中国1");
来看,你只要用简单的:
String s1 = s.replaceFirst("255 ","255,");就可以解决问题啊!
为什么要用正则呢?
如果想用,可以参考我写的IPV4匹配规则:
IPV4地址匹配,可以检查每个段在0-255,可以检测非法IP
测试数据:
192.168.1.1,
135.0.0.0,
1.1.1.1
178.153.558,259
12.12.12.12
1023.2562.12.10,
14.15.213.2555
正则表达式:
((2[0-5][0-5]|1\d\d|\d\d|\d)\.)3(2[0-5][0-5]|1\d\d|\d\d|\d)
匹配结果:
127.0.0.1,
192.168.1.1,
135.0.0.0,
1.1.1.1
12.12.12.12 参考技术C String subjectString=new String("0.0.0.0 0.255.255.255 CHINA 中国1");
String resultString = null;
try
Pattern regex = Pattern.compile("(\\d) ");
Matcher regexMatcher = regex.matcher(subjectString);
try
resultString = regexMatcher.replaceAll("$1,");
catch (IllegalArgumentException ex)
// Syntax error in the replacement text (unescaped $ signs?)
catch (IndexOutOfBoundsException ex)
// Non-existent backreference used the replacement text
catch (PatternSyntaxException ex)
// Syntax error in the regular expression
本回答被提问者采纳
java正则表达式
在JAVA中我想匹配一个字符串“00-18-F3-3E-89-EA”,当中的字符是十六进制的,也就是说只能是0~F之间的字符,该怎么写正则表达式呢。顺便问下正则表达式在JAVA中怎么用啊。
参考技术A [\dABCDEFabcdef]2(-[\dABCDEFabcdef]2)5此正则表达式可以匹配
在Java中使用正则表达式需要使用java.util.regex命名空间下的Pattern和Matcher类,具体使用方式请参考API
不过你可以直接使用String的方法,诸如split,replace等都是使用正则表达式,测试一个字符串是否匹配一个正则表达式请使用matches方法,如:
“00-18-F3-3E-89-EA”.matches("[\\dABCDEFabcdef]2(-[\\dABCDEFabcdef]2)5"); 参考技术B String reg = "([0-9a-fA-F]2-)5[0-9a-fA-F]2";
String test = "00-18-F3-3E-89-EA";
Pattern p = Pattern.compile(reg);
Matcher m = p.matcher(test);
boolean b = m.matches();
System.out.println(b);
简单写写本回答被提问者采纳
以上是关于请问JAVA中正则表达式匹配怎么实现的!的主要内容,如果未能解决你的问题,请参考以下文章