如何在python列表中查找某个元素的索引
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在python列表中查找某个元素的索引相关的知识,希望对你有一定的参考价值。
参考技术A一、创建一个列表
只要把逗号分隔的不同的数据项使用方括号括起来即可。与字符串的索引一样,列表索引从0开始。列表可以进行截取、组合等。如下所示:

二、访问列表中的值
使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符,如下所示:
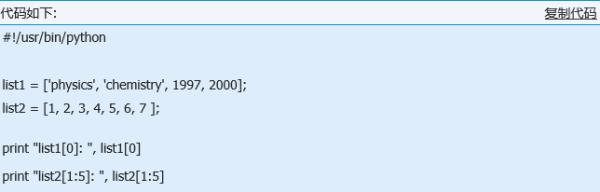
以上实例输出结果:

三、更新列表
你可以对列表的数据项进行修改或更新,你也可以使用append()方法来添加列表项,如下所示:

以上实例输出结果:

四、删除列表元素
可以使用 del 语句来删除列表的的元素,如下实例:

以上实例输出结果:

五、Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
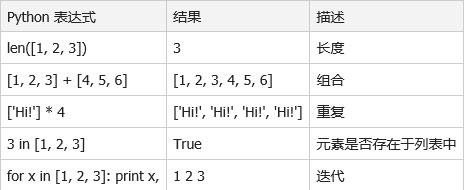
六、Python列表截取
Python的列表截取与字符串操作类型,如下所示:

操作:

七、Python列表操作的函数和方法
列表操作包含以下函数:1、cmp(list1, list2):比较两个列表的元素
2、len(list):列表元素个数
3、max(list):返回列表元素最大值
4、min(list):返回列表元素最小值
5、list(seq):将元组转换为列表
列表操作包含以下方法:
1、list.append(obj):在列表末尾添加新的对象
2、list.count(obj):统计某个元素在列表中出现的次数
3、list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
4、list.index(obj):从列表中找出某个值第一个匹配项的索引位置
5、list.insert(index, obj):将对象插入列表
6、list.pop(obj=list[-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
7、list.remove(obj):移除列表中某个值的第一个匹配项
8、list.reverse():反向列表中元素
9、list.sort([func]):对原列表进行排序。
在Python中查找列表中匹配元素的索引
【中文标题】在Python中查找列表中匹配元素的索引【英文标题】:Finding the indices of matching elements in list in Python 【发布时间】:2013-05-17 03:04:26 【问题描述】:我有一长串从 1 到 5 的浮点数,称为“平均值”,我想返回小于 a 或大于 b 的元素的索引列表
def find(lst,a,b):
result = []
for x in lst:
if x<a or x>b:
i = lst.index(x)
result.append(i)
return result
matches = find(average,2,4)
但令人惊讶的是,“matches”的输出中有很多重复,例如[2, 2, 10, 2, 2, 2, 19, 2, 10, 2, 2, 42, 2, 2, 10, 2, 2, 2, 10, 2, 2, ...]。
为什么会这样?
【问题讨论】:
How to find all occurrences of an element in a list?的可能重复 【参考方案1】:您正在使用.index(),它只会在列表中找到您的值的第一次出现。因此,如果您在索引 2 和索引 9 处具有值 1.0,那么 .index(1.0) 将始终返回 2,无论 1.0 在列表中出现多少次。
改为使用enumerate() 为循环添加索引:
def find(lst, a, b):
result = []
for i, x in enumerate(lst):
if x<a or x>b:
result.append(i)
return result
你可以把它折叠成一个列表理解:
def find(lst, a, b):
return [i for i, x in enumerate(lst) if x<a or x>b]
【讨论】:
现在我完全明白了。列表推导真的很好用,我还在尝试在 Python 中适应这种紧凑的形式。您的回答非常好,非常感谢! 有趣的是,重复的错误结果似乎对我以后的使用效果很好,因为我想用它来提取大矩阵的列。似乎重复不会影响切片。 您仍然会从列表中获得正确的值,相同的值位于索引 2 和任何后面的索引处。但这是一个等待发生的错误,它会在代码中的其他位置咬你。【参考方案2】:如果你经常做这种事情,你应该考虑使用numpy。
In [56]: import random, numpy
In [57]: lst = numpy.array([random.uniform(0, 5) for _ in range(1000)]) # example list
In [58]: a, b = 1, 3
In [59]: numpy.flatnonzero((lst > a) & (lst < b))[:10]
Out[59]: array([ 0, 12, 13, 15, 18, 19, 23, 24, 26, 29])
针对Seanny123的问题,我使用了这个计时码:
import numpy, timeit, random
a, b = 1, 3
lst = numpy.array([random.uniform(0, 5) for _ in range(1000)])
def numpy_way():
numpy.flatnonzero((lst > 1) & (lst < 3))[:10]
def list_comprehension():
[e for e in lst if 1 < e < 3][:10]
print timeit.timeit(numpy_way)
print timeit.timeit(list_comprehension)
numpy 版本快 60 倍以上。
【讨论】:
与仅进行列表理解相比,性能比较是什么?另外,为什么使用numpy.flatnonzero 而不是numpy.where?
在我手中快了 60 倍以上。 flatnonzero 比 where 简单,这里;您不需要从元组中提取索引数组。【参考方案3】:
>>> average = [1,3,2,1,1,0,24,23,7,2,727,2,7,68,7,83,2]
>>> matches = [i for i in range(0,len(average)) if average[i]<2 or average[i]>4]
>>> matches
[0, 3, 4, 5, 6, 7, 8, 10, 12, 13, 14, 15]
【讨论】:
这根本不是 OP 想要的。以上是关于如何在python列表中查找某个元素的索引的主要内容,如果未能解决你的问题,请参考以下文章