SparkSQL学习案例:使用DataFrame和Dataset操作json数据
Posted Liu_Yin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkSQL学习案例:使用DataFrame和Dataset操作json数据相关的知识,希望对你有一定的参考价值。
一、测试数据集(奥特曼.json)

二、源代码及代码分析
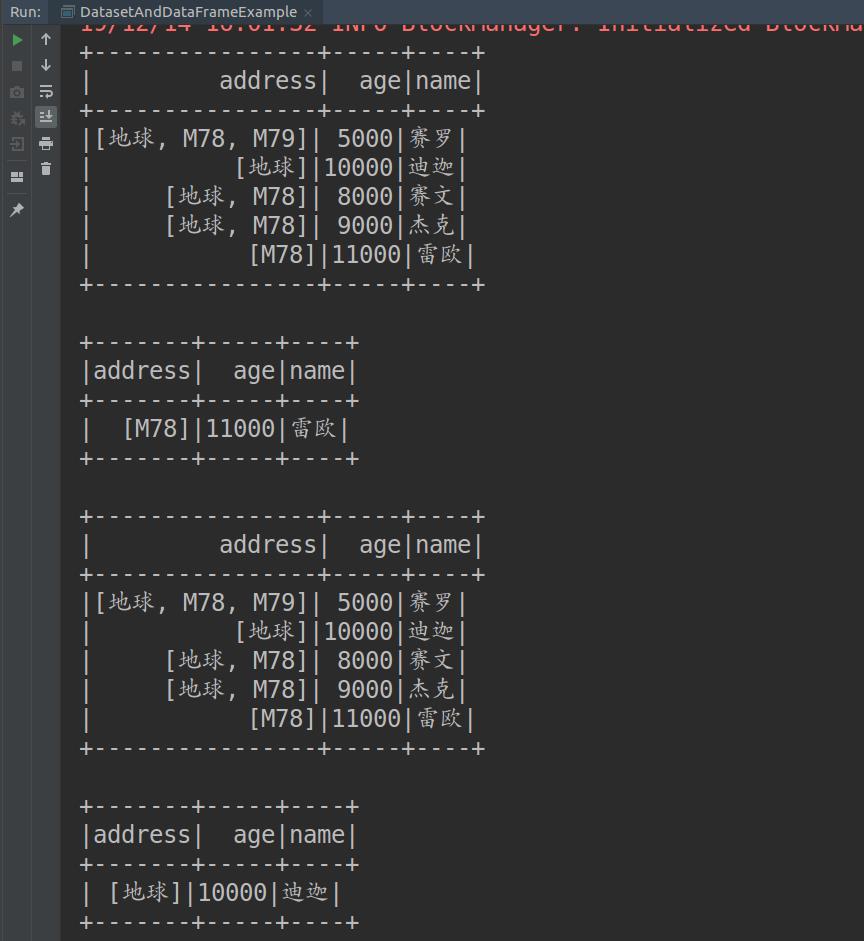
1 Scala版本 2 3 import org.apache.spark.sql.SparkSession 4 5 //根据分析数据写出相应的样例类 6 case class Ultraman(name: String, age: BigInt, address: Array[String]) 7 8 object DatasetAndDataFrameExample { 9 10 def main(args: Array[String]): Unit = { 11 12 //实例化SparkSession 13 val spark = SparkSession 14 .builder() 15 .master("local[*]") 16 .appName("DatasetAndDataFrameExample") 17 .getOrCreate() 18 19 //为避免影响查看输出结果,设置日志打印等级为"WARN" 20 spark.sparkContext.setLogLevel("WARN") 21 22 import spark.implicits._ 23 //使用SparkSession读取输入路径的json数据文件 24 val df1 = spark.read.json("/home/liuyin/IdeaProjects/Spark/src/main/scala/chap07_SparkSQL/奥特曼.json") 25 //打印当前表格内容 26 df1.show() 27 //筛选出符合条件的数据并打印出来 28 df1.filter($"address" === Array("M78")).filter($"age" > 10000).show() 29 30 val ds1 = spark.read.json("/home/liuyin/IdeaProjects/Spark/src/main/scala/chap07_SparkSQL/奥特曼.json").as[Ultraman] 31 ds1.show() 32 ds1.filter(_.name == "迪迦").show() 33 34 spark.stop() 35 } 36 }
相关的细节
(1)28行的$"address" === Array("M78")是SQLContext中的判断表达式,"==="是Column类中的一个方法,这个表达式也可以写成$"address".===(Array("M78"))
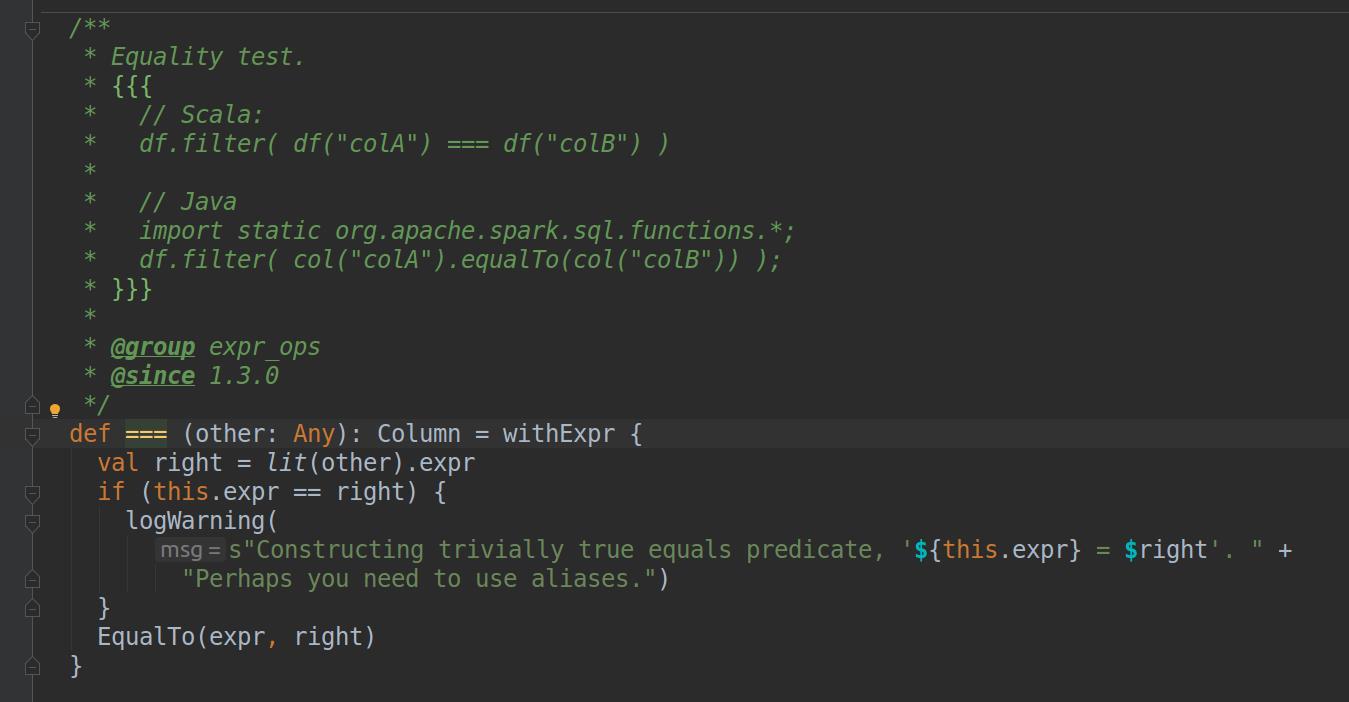
(2)使用"==="等表达式需要导入SOark隐式转换包,如22行所示
(3)第6行中的样例类是为了创建Dataset实例后,Dataset能识别出输入文件的每行数据各个元素的类型,样例类的属性名称应与输入数据的字段名一样
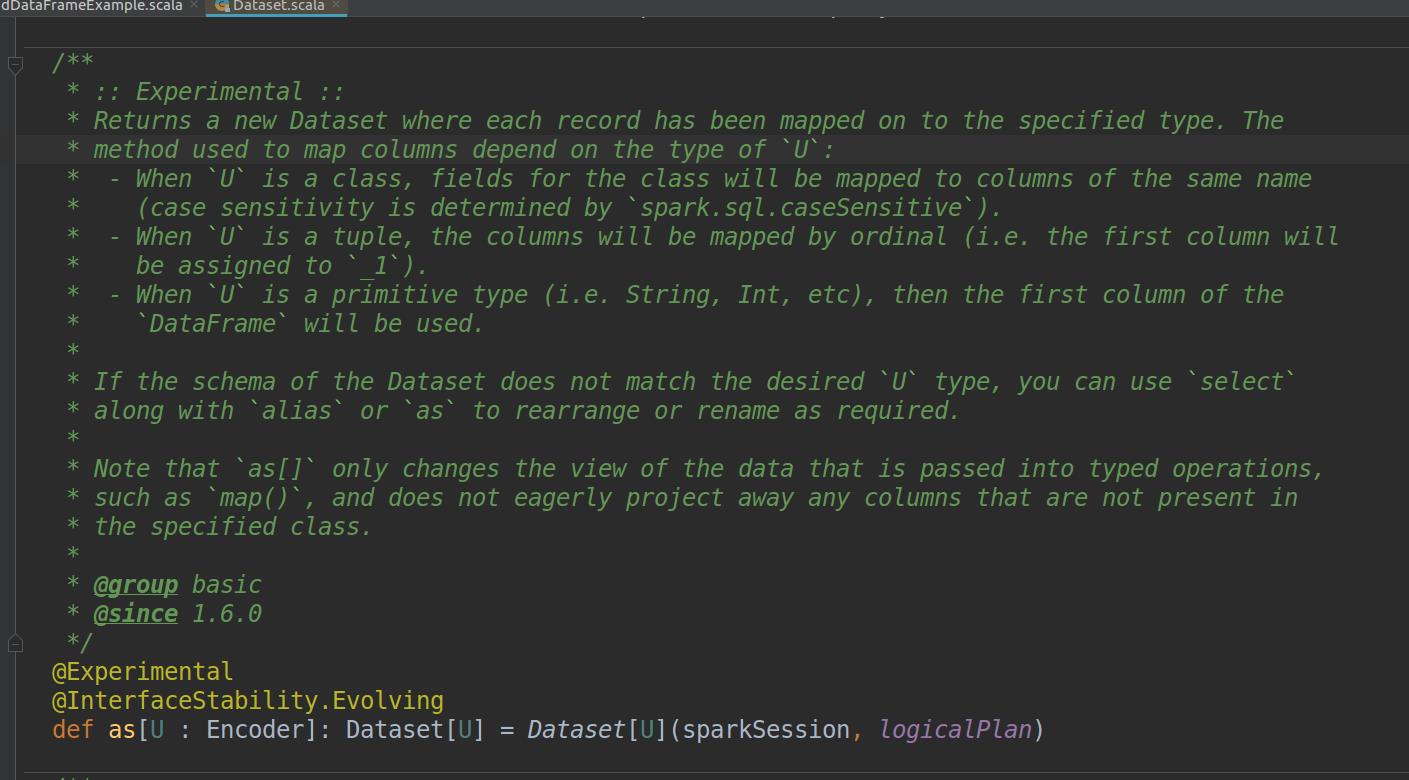
(4)第30行中,在调用.as[Ultraman]之前生成的还是一个DataFrame实例,调用之后会生成Dataset实例(其中的元素类型就是我们之前写的样例类Ultraman),as方法具体描述如下图
(5)样例类Ultraman在编译后会自动继承Product特质(类似于Java的接口),成为Product的子类,这么做的原因是as方法中的Ultraman类型必须是Encoder类型或其子类型,正巧隐式转换还有一个作用是将Dataset中的Product数据类型转换成Encoder类型的对象(调用了特质LowPrioritySQLImplicits里面的newProductEncoder方法),若样例类Ultraman在编译后不是Product类或子类则无法满足类型匹配
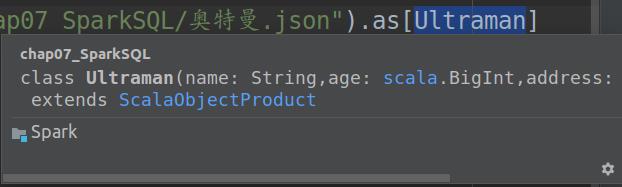
可以看出Ultraman在编译后已经继承了Product
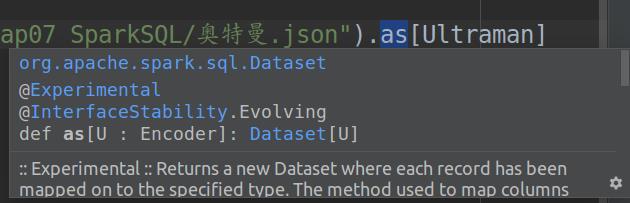
as方法的详细描述
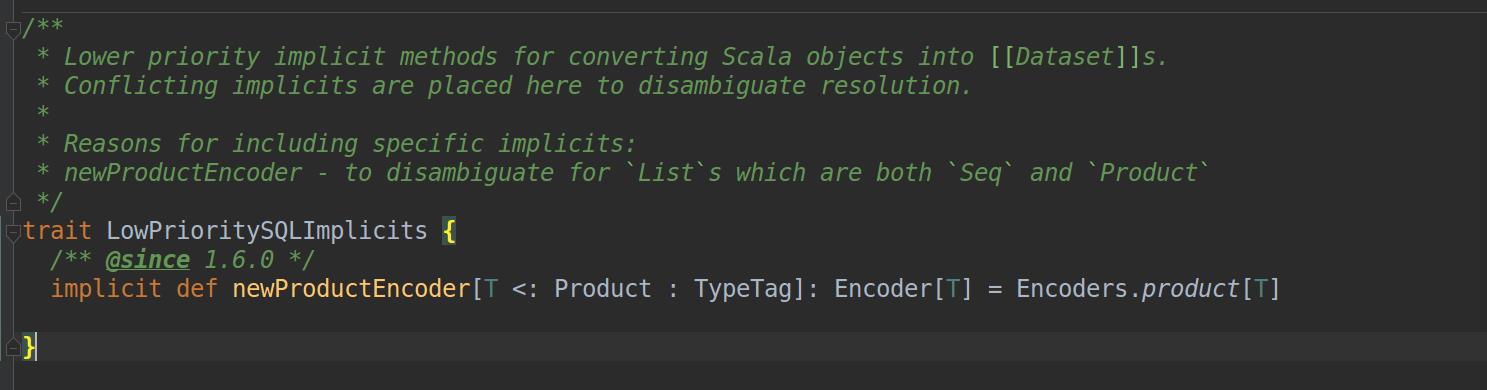
newProductEncoder方法的源代码
三、输出结果
以上是关于SparkSQL学习案例:使用DataFrame和Dataset操作json数据的主要内容,如果未能解决你的问题,请参考以下文章