解决jsp中文乱码问题
Posted 文洁丫头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解决jsp中文乱码问题相关的知识,希望对你有一定的参考价值。
1. 先解决响应中的乱码
何为响应中的乱码?把页面中的“username”改成“用户名”你就知道了。

所谓响应中的乱码,就是显示页面上的乱码,因为页面数据是从服务器一端放入响应(response)中,然后发送给浏览器,如果响应中的数据无法被正常解析,就会出现乱码问题。
为什么英文就没有问题呢?因为在iso-8859-1,gb2312, utf-8以及任意一种编码格式下,英文编码格式都是一样的,每个字符占8位,而中文就麻烦了,在gb2312下一个中文占16位,两字节,而在utf-8下一个中文要占24位,三字节。浏览器在不知道确定编码方式的情况下,就会把这些字符从中间截断,再显示的时候就乱掉了。所以,想要解决乱码问题,就是要告诉浏览器我们到底使用了什么样的编码方式。
为了获得正常显示的中文,需要注意以下几步:
-
因为服务器要先从本地读取jsp文件,然后经过处理后写入响应,所以我们首先要知道的就是jsp文件的编码格式。从问题的源头着手解决。
在咱们用的windowxp下,文件默认的编码格式是gb2312。
-
我们要在http的响应(response)中添加编码信息,使用如下方式:
<%@ page contentType="text/html; charset=gb2312"%>
这段要放在jsp页面的第一行,用来指定响应的类型和编码格式,contentType为text/html就是html内容,charset表示编码为gb2312。这样浏览器就可以从响应中获得编码格式了。
这种<%@ %>的形式叫做jsp指令(directive),现在接触到的是page指令。
- 还需要在html中指定编码格式
<head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> <title>title</title> </head>meta部分用来指定当前html的编码格式,注意这一段要放在head标签中,并且放到head标签的最前面,如果不是最前面ie下可能会出现问题,尤其是在title中有中文的情况下。
完成了以上三段检验,我们才能保证输出的jsp页面会正常显示中文。
2. POST乱码
先把form里加上method="POST",让form提交的时候使用POST方式。
发送请求的时候,使用的编码是iso-8859-1,意味着只有英文是有效字符,这个限制是因为当初指定http标准的成员都来自英语国家,所以如果使用默认的方式从请求获取数据,中文一定会全部变成乱码。
如果不信,你可以在刚才的例子里输入中文,然后提交:
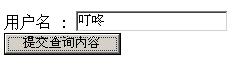
提交结果就会变成这样:
 怎么解决呢?我们要jsp最前面加上一条java语句,设置请求的字符编码。
怎么解决呢?我们要jsp最前面加上一条java语句,设置请求的字符编码。<% request.setCharacterEncoding("gb2312"); %>
于是,那些乱码都正常了:
 3. GET乱码
3. GET乱码警告
GET情况下,使用URLEncode()的确可以解决乱码问题,该部分需要补充。
直接点击超链接,form的默认提交方式都是GET。POST方式下的解决方式还算简单,因为POST方式下提交的数据都是以二进制的方式附加在http请求的body部分发送,只需要在后台指定编码格式就足矣解决。GET方式下会将参数直接附加到url后面,这部分参数无法使用request.setCharacterEncoding()处理,结果就是get形式的所有中文都变成了乱码。
这时再也没有简便方法了,只能对这些中文一个一个进行转换,使用new String(bytes, "gb2312")进行转码。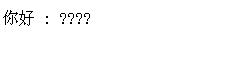
这时再也没有简便方法了,只能对这些中文一个一个进行转换,使用new String(bytes, "gb2312")进行转码。
<% String username = request.getParameter("username"); byte[] bytes = username.getBytes("iso-8859-1"); String result = new String(bytes, "gb2312"); out.print(result); %>
如我们所见,先从request中获得参数,接着把字符串按照iso-8859-1编码打散成byte数组,然后用gb2312编码组合成新字符串,最后打印出来就是正常的中文了。
写在一起就变成了:
<%=new String(new String(request.getParameter("username").getBytes("iso-8859-1"), "gb2312")%>这样做的缺点,是从请求中取得的所有中文都需要转码,非常烦琐。
这样解决中文乱码问题实在太繁琐,做一般的测试例子还可以,做大型项目时就会很麻烦,所以一般用过滤器解决。在spring框架下。例子1
<!-- spring的字符过滤器 ,不是必须的,可以其他方式解决 --> <filter> <filter-name>CharacterEncodingFilter</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>UTF-8</param-value> </init-param> <init-param> <param-name>forceEncoding</param-name> <param-value>true</param-value> </init-param> </filter> <filter-mapping> <filter-name>CharacterEncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>例子2 我们可以自定义一个过滤器来解决中文乱码问题
 View Code
View Code1 import java.io.IOException; 2 import javax.servlet.Filter; 3 import javax.servlet.FilterChain; 4 import javax.servlet.FilterConfig; 5 import javax.servlet.ServletException; 6 import javax.servlet.ServletRequest; 7 import javax.servlet.ServletResponse; 8 9 public class EncodingFilter implements Filter { 10 11 public void init(FilterConfig config) throws ServletException {} 12 13 public void destroy() {} 14 15 public void doFilter(ServletRequest request, 16 ServletResponse response, 17 FilterChain chain) 18 throws IOException, ServletException { 19 20 request.setCharacterEncoding("gb2312"); 21 chain.doFilter(request, response); 22 } 23 24 }
在此EncodingFilter实现了Filter接口,Filter接口中定义的三个方法都要在EncodingFilter中实现,其中doFilter()的代码实现主要的功能:为请求设置gb2312编码并执行chain.doFilter()继续下面的操作。
与servlet相似,为了让filter发挥作用还需要在web.xml进行配置。
<filter> <filter-name>EncodingFilter</filter-name> <filter-class>anni.EncodingFilter</filter-class> </filter> <filter-mapping> <filter-name>EncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>filter标签部分定义使用的过滤器,filter-mapping标签告诉服务器把哪些请求交给过滤器处理。这里的/*表示所有请求,/表示根路径,*(星号)代表所有请求,加在一起就变成了根路径下的所有请求。
这样,所有的请求都会先被EncodingFilter拦截,并在请求里设置上指定的gb2312编码。

以上是关于解决jsp中文乱码问题的主要内容,如果未能解决你的问题,请参考以下文章