LoadRunner HTTP响应正文中乱码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LoadRunner HTTP响应正文中乱码相关的知识,希望对你有一定的参考价值。
Loadrunner版本 11.00
网站页面编码:UTF-8
录制选项字符集已经选择支持和UTF-8
为什么响应原文中中文乱码?
求大神指教,小弟不胜感激
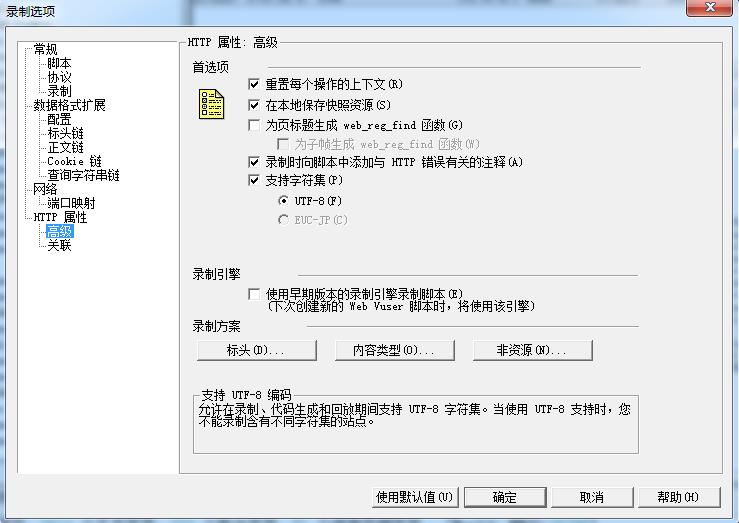
1。首先声明一个字符串数组msg用来保存转换后的内容
2。然后在脚本中使用该函数进行转码,
lr_convert_string_encoding( “乱码文字内容”,LR_ENC_UTF8,LR_ENC_SYSTEM_LOCALE,"msg" );
3。你可以用lr_output_message(msg)输出下结果查看本回答被提问者和网友采纳
如何在 HTTP 响应正文中使用正则表达式搜索短语
【中文标题】如何在 HTTP 响应正文中使用正则表达式搜索短语【英文标题】:How to use a regex search phrase in HTTP response body 【发布时间】:2013-05-15 13:56:51 【问题描述】:我正在尝试在 HTTP 响应正文中搜索这样的短语:
>> myvar1
<HTML>
<HEAD> <TITLE>TestExample [Date]</TITLE></HEAD>
</HTML>
当我这样做时,我没有得到任何结果:
>> myvar.scan(/<HEAD> <TITLE>TestExample [Date]<\/TITLE><\/HEAD>/)
[]
这里,[Date] 是一个动态变量,通过循环迭代获取其值。
我应该在正则表达式中添加/更改什么?
我正在使用 Nokogiri 扫描 HTTP 响应正文中的关键字。
【问题讨论】:
不要使用正则表达式解析 HTML。您无法使用正则表达式可靠地解析 HTML,并且您将面临悲伤和挫败感。一旦 HTML 与您的期望发生变化,您的代码就会被破坏。请参阅下面的 nokogiri 回复。 @Andy Lester Thnx 提醒大家。 【参考方案1】:请不要使用正则表达式解析任何标记,例如 HTML。出于这样的目的,将其提供给适当的 SAX 或 DOM 解析器并以这种方式提取您想要的内容会更易于维护。这样做的原因是,无论你如何巧妙地制定正则表达式,总会有你可能忘记的极端情况。
require 'nokogiri'
response = "<HTML> <HEAD> <TITLE>TestExample [Date]</TITLE></HEAD> </HTML>"
doc = Nokogiri::HTML( response )
doc.css( "title" ).text
【讨论】:
小心使用css('title')。 css 返回一个 NodeSet,其作用类似于一个数组。相反,因为您正在搜索 title,所以请使用 at 或其别名来返回匹配的第一个节点。
感谢@Bjoern。我现在尝试使用 Nokogiri 并收到错误消息。请查看我对问题的更新。
您可以使用 irb 来验证答案中的代码是否有效。错误在您的代码中的其他地方。请打开一个新问题。
Nokogiri 解析 HTML/XML,但不幸的是没有归结为 javascript 级别。为此,您需要选择每个脚本节点并使用正则表达式来查找您要查找的内容。这是一个讨论类似***.com/questions/14461931/…的SO。
非常感谢@BjoernRennhak 和所有响应帮助的人。【参考方案2】:
这会起作用
<HEAD> <TITLE>TestExample (.*?)<\/TITLE><\/HEAD>
http://rubular.com/r/latepMqrjx
您可能不需要像<HEAD> <TITLE> 这样具体的东西,因为我怀疑会有多个标题。区分大小写和换行也可能是一个问题。我可能会使用
/<title>TestExample (.*?)<\//im
【讨论】:
什么是实际输入? 谢谢,对不起。我发消息太快了。以上两个都返回 [["[Date]"]]。但是,我试图在响应正文中找到 - TestExample [Date] -。它是“if”检查的一部分 - if (not res or not res.scan(TestExample [Date])) -> 然后失败操作,否则通过操作。除了正则表达式之外,这里需要注意的一件事是,这个“日期”实际上是一个参数,它从一开始就来自循环并在每次传递时分配值。 不要使用正则表达式。虽然它适用于简单的任务,但对于任何中等复杂性的东西来说它都太脆弱了,而且如果页面发生变化,它很可能会崩溃。 DOM 解析器更加健壮且更易于维护。【参考方案3】:你做得太难了。使用Nokogiri,您可以轻松解析和搜索 HTML 和/或 XML。
要获取<title> 文本,只需使用Nokogiri 的HTML::Document#title 方法:
require 'nokogiri'
doc = Nokogiri::HTML('<HTML> <HEAD> <TITLE>TestExample [Date]</TITLE></HEAD> </HTML>')
doc.title # => "TestExample [Date]"
没有需要编写或维护的正则表达式,只要 HTML 合理有效,这将起作用。
由于您正在尝试获取看起来像日期模板的内容,您可能想要重写该字符串,Nokogiri 也可以使用title = 轻松实现:
require 'date'
require 'nokogiri'
doc = Nokogiri::HTML('<HTML> <HEAD> <TITLE>TestExample [Date]</TITLE></HEAD> </HTML>')
title = doc.title
title['[Date]'] = Date.today.to_s
doc.title = title
puts doc.to_html
# >> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd">
# >> <html> <head>
# >> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <title>TestExample 2020-03-18</title>
# >> </head> </html>
【讨论】:
以上是关于LoadRunner HTTP响应正文中乱码的主要内容,如果未能解决你的问题,请参考以下文章
loadrunner录制脚本后,进行参数化设置,回放脚本报错
使用loadrunner回放脚本时,页面出现乱码怎么办,已经在Recording options 选中UTF-8,但还是出现乱码,
loadrunner tree 的 server response中 中文乱码怎么解决?