access 查询条件 能否用自定义的函数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了access 查询条件 能否用自定义的函数相关的知识,希望对你有一定的参考价值。
表达式那能不能用vbA定义的全局变量 比如定义一个X 使id=x。我试了一下不行。是写的方法不对呢,还是根本就不能用?
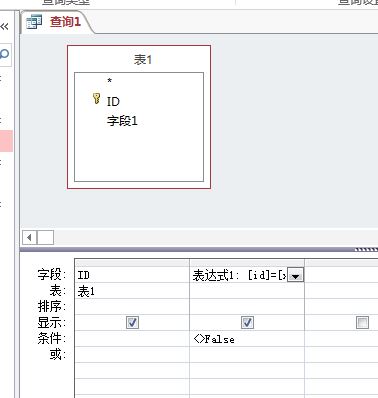
access查询不需要使用到函数,具体操作方法如下:
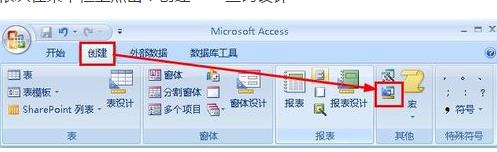
1.依次在菜单栏上点击:创建——查询设计。
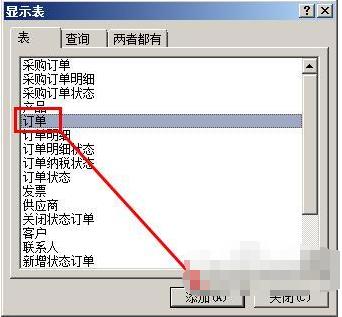
2.在弹出的显示表对话框中,选择订单这个表,然后点击添加。
3.在点击员工字段,然后拖拽到下面的设计表格。
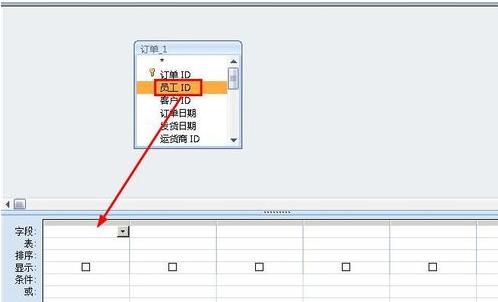
4.同样的方法将其他表格拖拽到下面的设计字段。
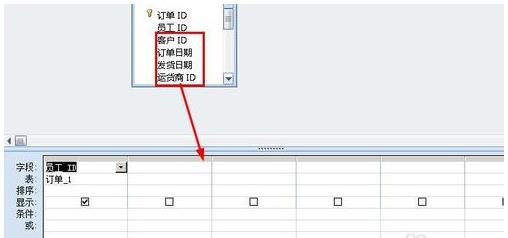
5.然后在条件这一栏输入 条件:=1。
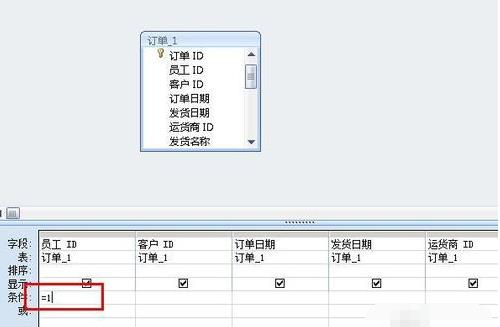
6.点击菜单栏上面的生成表按钮,打开生成表的设计窗口。
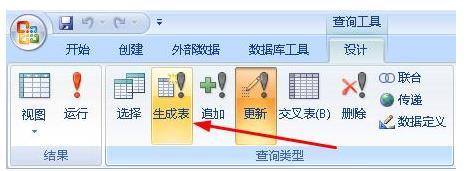
7.弹出了对话框,要填写生成的表的名称。
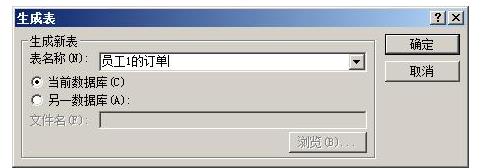
8.接着点击保存按钮。
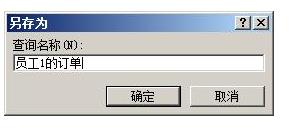
9.在弹出的对话框中,输入保存的查询的名称。
10.点击运行按钮就可以生成表。
11.这就是员工1的订单表了。
参考技术A 你是要把ID字段值为X的查询出来还是要把ID字段的值改写为X?如果是要查询出来,只需在条件中输入“X”就行了,如是要把ID的值改写在X,则可以用更新查询。更新到“X” 参考技术B 表达式不能用全局变量不过可以用全局函数
你可以用全局函数返回你那个变量值就可以达到你的目的
比如[id] = getX()追问
再请问一下如何才能使getX返回不同的值呢?我试了一下里面一加变量就不行。请您再帮忙解释一下好吗?
本回答被提问者采纳MySQL巧用自定义函数进行查询优化
用户自定义变量是一个很容易被遗忘的MySQL特性,但是用的好,发挥其潜力,在很多场景都可以写出非常高效的查询语句。
一. 实现一个按照actorid排序的列
1 mysql> set @rownum :=0; 2 Query OK, 0 rows affected (0.00 sec) 3 4 mysql> select actor_id ,@rownum :=@rownum + 1 as rownum 5 -> from sakila.actor limit 3; 6 +----------+--------+ 7 | actor_id | rownum | 8 +----------+--------+ 9 | 58 | 1 | 10 | 92 | 2 | 11 | 182 | 3 | 12 +----------+--------+ 13 3 rows in set (0.00 sec)
二. 扩展一下,现在需要获取演过最多电影的前十位,针对数量作一个排名,如果数量一样,则排名相同
1 mysql> set @curr_cnt :=0 ,@pre_cnt :=0 ,@rank :=0; 2 Query OK, 0 rows affected (0.00 sec) 3 4 mysql> select actor_id, 5 -> @prev_cnt :=@curr_cnt as dummy, 6 -> @curr_cnt := cnt as cnt, 7 -> @rank := IF(@prev_cnt <> @curr_cnt,@rank+1,@rank) as rank 8 -> FROM( 9 -> SELECT actor_id ,count(*) as cnt 10 -> FROM sakila.film_actor 11 -> GROUP BY actor_id 12 -> ORDER BY cnt DESC 13 -> LIMIT 10 14 -> )as der; 15 +----------+-------+-----+------+ 16 | actor_id | dummy | cnt | rank | 17 +----------+-------+-----+------+ 18 | 107 | 0 | 42 | 1 | 19 | 102 | 42 | 41 | 2 | 20 | 198 | 41 | 40 | 3 | 21 | 181 | 40 | 39 | 4 | 22 | 23 | 39 | 37 | 5 | 23 | 81 | 37 | 36 | 6 | 24 | 158 | 36 | 35 | 7 | 25 | 144 | 35 | 35 | 7 | 26 | 37 | 35 | 35 | 7 | 27 | 106 | 35 | 35 | 7 | 28 +----------+-------+-----+------+ 29 10 rows in set (0.00 sec)
三. 避免重复查询刚更新的数据
如果想要高效的更新一条记录的时间戳 ,又想返回更新的数据
1 mysql> create table t2 (id int,lastUpdated datetime); 2 Query OK, 0 rows affected (0.03 sec) 3 4 mysql> insert into t2 (id ,lastupdated)values(1,sysdate()); 5 Query OK, 1 row affected (0.02 sec) 6 7 mysql> select * from t2; 8 +------+---------------------+ 9 | id | lastUpdated | 10 +------+---------------------+ 11 | 1 | 2017-07-24 16:03:34 | 12 +------+---------------------+ 13 1 row in set (0.01 sec) 14 15 mysql> update t2 set lastUpdated=NOW() WHERE id =1 and @now :=Now(); 16 Query OK, 1 row affected (0.02 sec) 17 Rows matched: 1 Changed: 1 Warnings: 0 18 19 20 mysql> select @now, sysdate(); 21 +---------------------+---------------------+ 22 | @now | sysdate() | 23 +---------------------+---------------------+ 24 | 2017-07-24 16:05:42 | 2017-07-24 16:06:06 | 25 +---------------------+---------------------+ 26 1 row in set (0.00 sec)
四. 统计更新和插入的数量
使用 INSERT ON DUPLICATE KEY UPDATE 时,查询插入成功的条数,冲突的条数
1 mysql> set @x :=0; 2 Query OK, 0 rows affected (0.00 sec) 3 4 mysql> INSERT INTO t3(c1,c2) values(1,2),(1,3),(2,2) 5 -> ON DUPLICATE KEY UPDATE 6 -> c2=VALUES(c2)+(0*(@x:=@x+1)); 7 Query OK, 4 rows affected (0.01 sec) 8 Records: 3 Duplicates: 1 Warnings: 0 9 10 mysql> select @x; 11 +------+ 12 | @x | 13 +------+ 14 | 1 | 15 +------+ 16 1 row in set (0.00 sec) 17 18 mysql> select * from t3; 19 +----+------+ 20 | c1 | c2 | 21 +----+------+ 22 | 1 | 3 | 23 | 2 | 2 | 24 +----+------+ 25 2 rows in set (0.00 sec)
五. 确定取值的顺序
想要获取sakila.actor中的一个结果
错误的查询一:
下面的查询看起来好像只返回一个结果,实际呢:
1 mysql> set @row_num :=0; 2 Query OK, 0 rows affected (0.00 sec) 3 4 mysql> SELECT actor_id,@row_num :=@row_num+1 AS cnt 5 -> FROM sakila.actor 6 -> WHERE @row_num <=1 7 -> ; 8 +----------+------+ 9 | actor_id | cnt | 10 +----------+------+ 11 | 58 | 1 | 12 | 92 | 2 | 13 +----------+------+ 14 2 rows in set (0.00 sec) 15 16 看一下执行计划: 17 +----+-------------+-------+-------+---------------+---------------------+---------+------+------+--------------------------+ 18 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | 19 +----+-------------+-------+-------+---------------+---------------------+---------+------+------+--------------------------+ 20 | 1 | SIMPLE | actor | index | NULL | idx_actor_last_name | 137 | NULL | 200 | Using where; Using index | 21 +----+-------------+-------+-------+---------------+---------------------+---------+------+------+--------------------------+ 22 1 row in set (0.00 sec)
这是因为where 和 select 是在 查询的不同阶段执行的造成的。
错误的查询二:
如果加上按照 first_name 排序呢 :
1 mysql> set @row_num :=0; 2 Query OK, 0 rows affected (0.00 sec) 3 4 mysql> SELECT actor_id,@row_num :=@row_num+1 AS cnt 5 -> FROM sakila.actor 6 -> WHERE @row_num <=1 7 -> order by first_name; 8 +----------+------+ 9 | actor_id | cnt | 10 +----------+------+ 11 | 71 | 1 | 12 | 132 | 2 | 13 | 165 | 3 | 14 | 173 | 4 | 15 | 125 | 5 | 16 | 146 | 6 | 17 | 29 | 7 | 18 | 65 | 8 | 19 | 144 | 9 | 20 | 76 | 10 | 21 | 49 | 11 | 22 | 34 | 12 | 23 | 190 | 13 | 24 | 196 | 14 | 25 | 83 | 15 | 26 .. ... 27 返回了所有行,再看下查询计划: 28 29 +----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+ 30 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | 31 +----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+ 32 | 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 200 | Using where; Using filesort | 33 +----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+ 34 1 row in set (0.00 sec)
可以看出原因是 Using where 是在排序操作之前取值的,所以输出了全部的行。
解决这个问题的方法是:让变量的赋值和取值发生在执行查询的统一阶段:
正确的查询:
1 mysql> set @row_num :=0; 2 Query OK, 0 rows affected (0.00 sec) 3 4 mysql> SELECT actor_id,@row_num AS cnt 5 -> FROM sakila.actor 6 -> WHERE (@row_num :=@row_num+1) <=1 7 -> ; 8 +----------+------+ 9 | actor_id | cnt | 10 +----------+------+ 11 | 58 | 1 | 12 +----------+------+ 13 1 row in set (0.00 sec) 14 15 看一下执行计划 16 17 +----+-------------+-------+-------+---------------+---------------------+---------+------+------+--------------------------+ 18 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | 19 +----+-------------+-------+-------+---------------+---------------------+---------+------+------+--------------------------+ 20 | 1 | SIMPLE | actor | index | NULL | idx_actor_last_name | 137 | NULL | 200 | Using where; Using index | 21 +----+-------------+-------+-------+---------------+---------------------+---------+------+------+--------------------------+ 22 1 row in set (0.00 sec)
想一想 如果加上ORDER BY 该怎么写?
1 mysql> set @row_num :=0; 2 Query OK, 0 rows affected (0.00 sec) 3 4 mysql> SELECT actor_id,first_name ,@row_num AS row_num 5 -> FROM sakila.actor 6 -> WHERE @row_num<=1 7 -> ORDER BY first_name , least(0, @row_num :=@row_num+1) 8 -> ; 9 10 +----------+------------+---------+ 11 | actor_id | first_name | row_num | 12 +----------+------------+---------+ 13 | 2 | NICK | 2 | 14 | 1 | PENELOPE | 1 | 15 +----------+------------+---------+ 16 2 rows in set (0.00 sec) 17 18 19 mysql> select @row_num; 20 +----------+ 21 | @row_num | 22 +----------+ 23 | 2 | 24 +----------+ 25 1 row in set (0.00 sec) 26 27 看一下执行计划: 28 29 +----+-------------+-------+------+---------------+------+---------+------+------+----------------------------------------------+ 30 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | 31 +----+-------------+-------+------+---------------+------+---------+------+------+----------------------------------------------+ 32 | 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 200 | Using where; Using temporary; Using filesort | 33 +----+-------------+-------+------+---------------+------+---------+------+------+----------------------------------------------+ 34 1 row in set (0.00 sec) 35 36 SELECT actor_id,first_name ,@row_num:=@row_num+1 AS row_num 37 FROM sakila.actor 38 WHERE @row_num<=1 39 ORDER BY first_name , least(0, @row_num :=@row_num+1)
六. UNION的巧妙改写
假设有两张用户表,一张主用户表,存放着活跃用户;一些归档用户表,存放着长期不活跃的用户。现在需要查找id 为123的客户。
先看下这个语句
1 select id from users where id= 123 2 union all 3 select id from users_archived where id =123
上面的语句是可以执行的,但是效率不好,因为两张表都必须查询一次
引入自定义变量的改写:
1 SELECT GREATEST(@found:=-1,id) AS id ,‘users‘ AS which_tbl 2 FROM users WHERE id =123 3 UNION ALL 4 SEELCT id,‘users_archived‘ FROM users_archived WHERE id = 123 AND @found IS NULL 5 UNION ALL 6 SELECT 1,‘reset‘ FROM DUAL WHERE (@found:=NULL) IS NOT NULL
上面的改写非常巧妙:
第一段,如果在users查询到记录,则为@found赋值,也不会查询第二段;如果没有查询到记录,@found 为 null ,执行第二段。
第三段没有输出 ,只是简单的重置@found 为null。另外 GREATEST(@found:=-1,id) 也不会影响输出!
以上是关于access 查询条件 能否用自定义的函数的主要内容,如果未能解决你的问题,请参考以下文章