imblearn 使用笔记
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了imblearn 使用笔记相关的知识,希望对你有一定的参考价值。
参考技术A 在做机器学习相关项目时,通常会出现样本数据量不均衡操作,这时可以使用 imblearn 包进行重采样操作,可通过 pip install imbalanced-learn 命令进行安装。注 在 imblearn 包使用过程中,通常输入项 x 多为 2D 的结构。否则会包 ``
在数据化运营过程中,以下场景会经常产生样本分布不均衡的问题:
抽样是解决样本分布不均衡相对简单且常用的方法,包括过抽样和欠抽样两种。
过抽样(也叫上采样、over-sampling)方法通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本形成多条记录,这种方法的缺点是如果样本特征少而可能导致过拟合的问题;经过改进的过抽样方法通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本,例如SMOTE算法。
欠抽样(也叫下采样、under-sampling)方法通过减少分类中多数类样本的样本数量来实现样本均衡,最直接的方法是随机地去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类样本中的一些重要信息。
总体上,过抽样和欠抽样更适合大数据分布不均衡的情况,尤其是第一种(过抽样)方法应用更加广泛。
本文中使用开放的微博4种情绪数据集 simplifyweibo_4_modes.csv 作为样本数据进行数据处理操作,其中所有的预操作如下:
过抽样方法通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本。
经过 RandomUnderSampler 重采样之后,。
注 SMOTE 算法与 ADASYN 都是基于同样的算法来合成新的少数类样本
注 每一个类别的样本都会用K-Means算法的中心点来进行合成, 而不是随机从原始样本进行抽取.
应用最近邻算法来编辑(edit)数据集, 找出那些与邻居不太友好的样本然后移除. 对于每一个要进行下采样的样本, 那些不满足一些准则的样本将会被移除; 他们的绝大多数(kind_sel='mode')或者全部(kind_sel='all')的近邻样本都属于同一个类, 这些样本会被保留在数据集中.
更新 sklearn 版本即可 pip install --upgrade git+https://github.com/jpmml/sklearn2pmml.git
pip install imblearn安装失败已解决
报错:
ERROR: Could not install packages due to an EnvironmentError: [WinError 5] 拒绝访问。: ‘d:\\anaconda3\\lib\\site-packages\\~klearn\\linear_model\\_cd_fast.cp37-win_amd64.pyd’
Consider using the --user option or check the permissions.
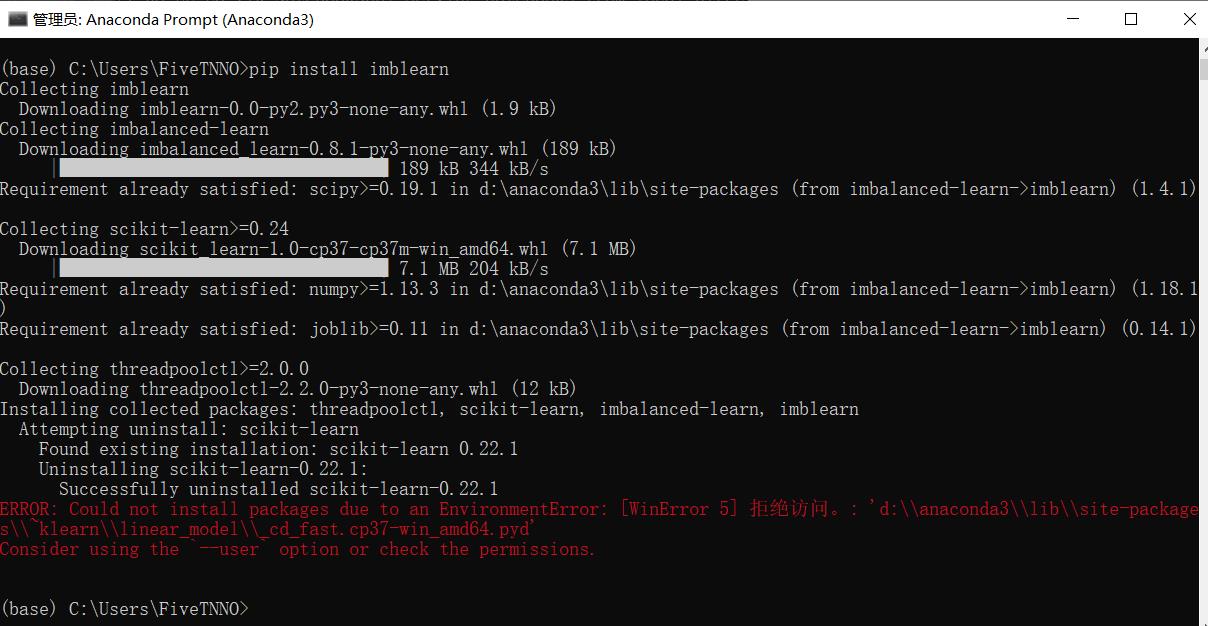
注意报错的最后一句话:Consider using the --user option or check the permissions.
看来加个 --user好像能解决的样子
然后我重新Win+R→cmd后输入:pip install --user imblearn
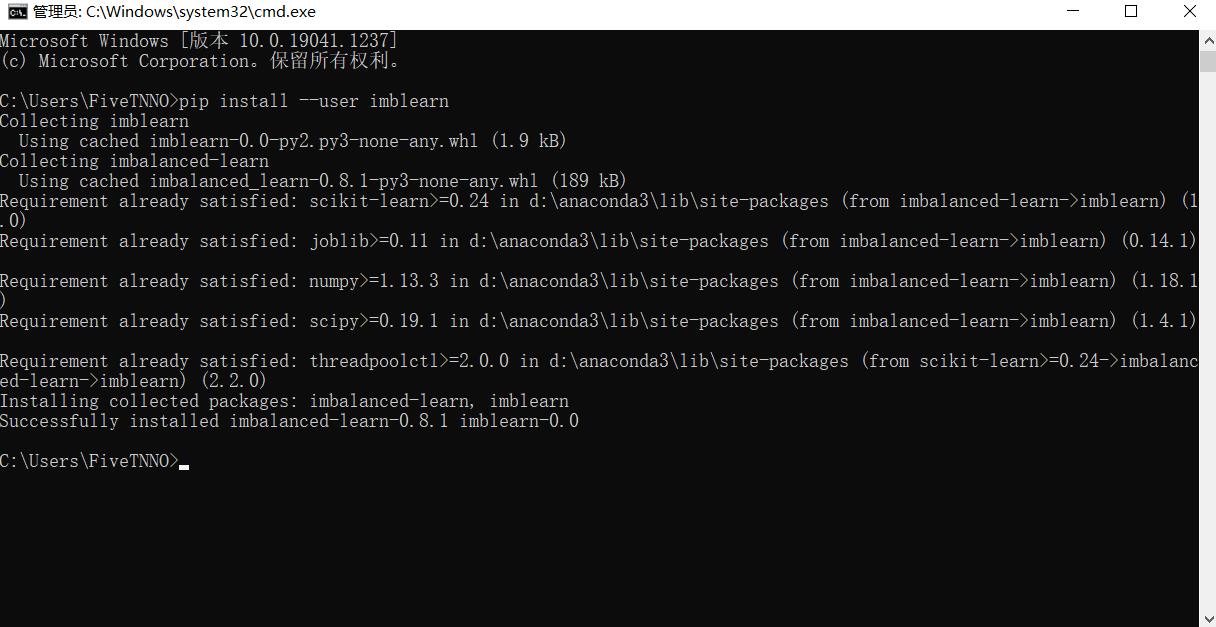
安装成功!
以上是关于imblearn 使用笔记的主要内容,如果未能解决你的问题,请参考以下文章