python统计个单词数目
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python统计个单词数目相关的知识,希望对你有一定的参考价值。
要求是get_word_frequencies(file_name) 打开了FILE NAME这文件后运用dictionary统计出文章中各单词的数目 效果如下:
'all': 1, 'forget': 1, '-': 3, 'years': 1, 'proposition': 1, 'continent': 1, 'liberty,': 1, 'We': 2, ...
PS:‘-’这种不属于单词的东西不要统计在内
请问楼主要区分大小写吗?如果区分的话,就按照下面的来:
import re
def get_word_frequencies(file_name):
dic =
txt = open(filename, 'r').read().splitlines()
#下面这句替换了除了'-'外的所有标点,因为'-'可能存在于单词中。
txt = re.sub(r'[^\u4e00-\u94a5\w\d\-]', ' ', txt)
#替换单独的'-'
txt = re.sub(r' - ', ' ', txt)
for line in :
for word in line.split():
#如果不区分大小写,那就一律按照小写处理,下面那句改为dic.setdefault(word.lower(), 0)
dic.setdefault(word, 0)
dic[word] += 1
print dic
if __name__ = '__main__':
get_word_frequencies('test.txt')
有问题继续追问吧 参考技术A 思路大概是这样:
将文件内容读到一个链表里边,用链表count()函数统计空格数量n,然后循环n次,每次做好单词前后空格标记,将该单词取出来,放到一个word【】空链表里,再用count()函数统计出现数,放到另外一个number【】空链表里,循环执行完之后,结果output=dict(zip(word,number))即为最后字典输出;
或者可以利用re正则表达式直接查找出空格中间的单词,输出到一个新链表里边,然后直接统计每个单词就行了 参考技术B dic =
for line in open(FILENAME):
for word in line.split():
dic.setdefault(word, 0)
dic[word] += 1
dic
大约这样吧,dic就是你要的了,横线这种东西自己处理一下就行了;
弄个[‘-’,‘其他不要的’]...... 参考技术C a = str("")
print len(a)
Python|Leetcode《1220》|统计元音字母序列的数目
专栏《LeetCode|一刷到底》
打卡每天leetcode精选每日一题(尽量不断更!)
点击关注不迷路!!!
一、题目描述
- 题目:统计元音字母序列的数目
- 难度:困难
- 地址:《统计元音字母序列的数目》
- 描述:给你一个整数 n,请你帮忙统计一下我们可以按下述规则形成多少个长度为 n 的字符串:
字符串中的每个字符都应当是小写元音字母('a', 'e', 'i', 'o', 'u')
每个元音'a'后面都只能跟着'e'
每个元音'e'后面只能跟着'a'或者是'i'
每个元音'i'后面 不能 再跟着另一个'i'
每个元音'o'后面只能跟着'i'或者是'u'
每个元音'u'后面只能跟着'a'
由于答案可能会很大,所以请你返回 模 10^9 + 7 之后的结果。
- 示例1
输入:n = 1
输出:5
解释:所有可能的字符串分别是:"a", "e", "i" , "o"和"u"。
- 示例2
输入:n = 2
输出:10
解释:所有可能的字符串分别是:"ae", "ea", "ei", "ia", "ie", "io", "iu", "oi", "ou"和"ua"。
- 示例3
输入:n = 5
输出:68
提示:
- 1 <= n <= 2 * 1 0 4 10^4 104
二、题目解析
此题虽为难题,但是本质上可以看作是动态规划问题的一般形态。
初始形态为字符串长度为1的时候的形态(n=1),后续随着n的增大,我们不断的替换每一层的字符中有几个a、e、i、o、u即可,例如第二层的字符中,在第一层字符e、i、u的后面会出现字符a。图解如下:
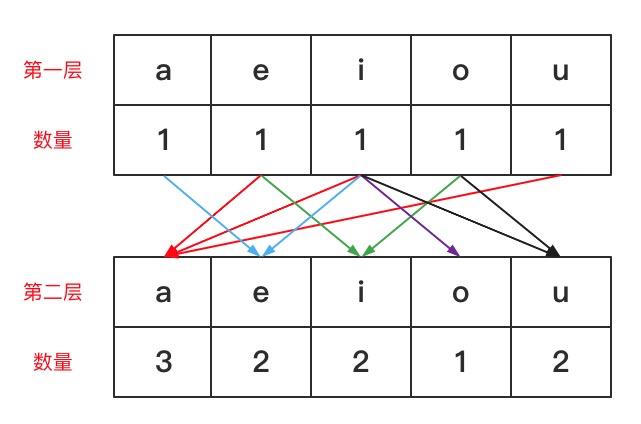
不同颜色的连线代表第二层中的各个字符会由上一层中的哪些字符得到,上一层中有几个这样的字符数量就为几,后面依次类推即可。
三、解题代码
解法
class Solution:
def countVowelPermutation(self, n: int) -> int:
a, e, i, o, u = 1, 1, 1, 1, 1
for _ in range(n - 1):
a, e, i, o, u = e + u + i, a + i, o + e, i, i + o
return (a + e + i + o + u) % (10**9 + 7)
以上是关于python统计个单词数目的主要内容,如果未能解决你的问题,请参考以下文章
C语言:输入一行字符,统计其中有多少个单词,单词之间用空格分隔开
统计一段文章的单词频率,取出频率最高的5个单词和个数(python)