js反爬:请开启JavaScript并刷新该页
Posted 肃木易
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了js反爬:请开启JavaScript并刷新该页相关的知识,希望对你有一定的参考价值。
中国人民银行网站中的这个栏目为例:http://www.pbc.gov.cn/zhengcehuobisi/125207/125217/125925/17105/index1.html
如果直接用request.get(url),就会得到下图的javascript并刷新该页,跟着一堆乱七八糟代码。

简单来说,就是html文件中包含cookie设置和动态跳转网址的js代码,访问这个网页时js会设置cookie然后重定向到另一个网页,所以只是get这个url是不行的。
同理,如果清除cookie,在浏览器中f12,然后按f1禁用js

刷新页面,就会出现下图乱码,其实就是之前跑代码得到的 “请开启JavaScript并刷新该页” 提示。

因此,要爬取这个网站的关键问题有两个,一个是用js重定向,一个是保存cookie。
先看看返回的网页的js代码。
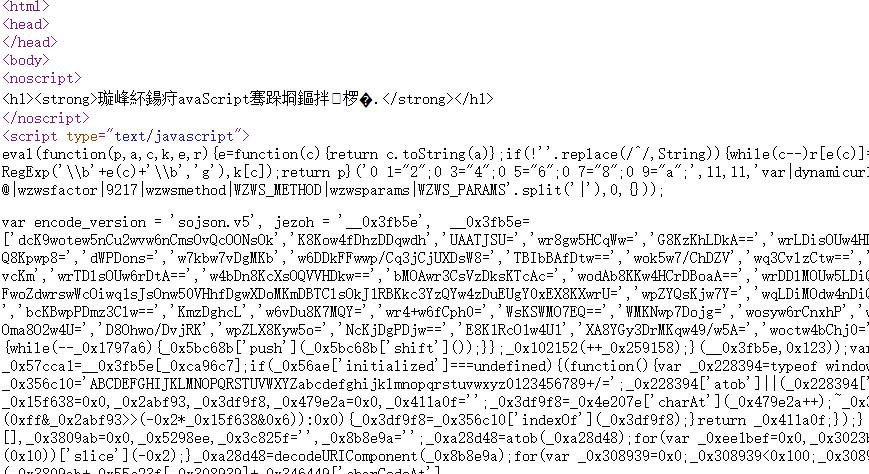
这就很乱了,随便用个js代码格式化网站,比如 https://www.bm8.com.cn/jsConfusion/
这样就可以比较清晰的看到js代码。
一顿分析之后,实现抓取的过程如下:
先get之前能得到的带有js的html。
将其中的js代码正则提取出来。
将里面的atob替换为window["atob"],增加window对象,函数getURL()返回window["location"],即跳转的链接尾缀。
将这个修改后js代码执行,得到尾缀,与原URL链接,得到重定向的URL。
还有就是cookie问题,直接用requests的session处理就好。
def getPage(URL):
sess = requests.session()
jsPage = sess.get(URL).text
js = re.findall(r\'<script type="text/javascript">([\\w\\W]*)</script>\', jsPage)[0]
js = re.sub(r\'atob\\(\', \'window["atob"](\', js)
js2 = \'function getURL(){ var window = {};\' + js + \'return window["location"];}\'
ctx = execjs.compile(js2)
tail = ctx.call(\'getURL\')
URL2 = urljoin(URL, tail)
page = sess.get(URL2)
page.encoding = \'UTF-8\'
return page
最后,在连续抓取页面时有时会报错,加了一两秒延迟就好了。还是会偶尔报错,用异常抛出让它重试即可。
以上是关于js反爬:请开启JavaScript并刷新该页的主要内容,如果未能解决你的问题,请参考以下文章