spark sql架构和原理——和Hive类似 dataframe无非是内存中的table而已 底层原始数据存储可以是parquet hive json avro等
Posted 将者,智、信、仁、勇、严也。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark sql架构和原理——和Hive类似 dataframe无非是内存中的table而已 底层原始数据存储可以是parquet hive json avro等相关的知识,希望对你有一定的参考价值。
from:https://blog.csdn.net/zhanglh046/article/details/78505038
一 Spark SQL运行架构
Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、执行。Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule)对Tree进行绑定、优化等处理过程。Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分构成:
Core: 负责处理数据的输入和输出,如获取数据,查询结果输出成DataFrame等
Catalyst: 负责处理整个查询过程,包括解析、绑定、优化等
Hive: 负责对Hive数据进行处理
Hive-ThriftServer: 主要用于对hive的访问
1.1 TreeNode
逻辑计划、表达式等都可以用tree来表示,它只是在内存中维护,并不会进行磁盘的持久化,分析器和优化器对树的修改只是替换已有节点。
TreeNode有2个直接子类,QueryPlan和Expression。QueryPlam下又有LogicalPlan和SparkPlan. Expression是表达式体系,不需要执行引擎计算而是可以直接处理或者计算的节点,包括投影操作,操作符运算等
1.2 Rule & RuleExecutor
Rule就是指对逻辑计划要应用的规则,以到达绑定和优化。他的实现类就是RuleExecutor。优化器和分析器都需要继承RuleExecutor。每一个子类中都会定义Batch、Once、FixPoint. 其中每一个Batch代表着一套规则,Once表示对树进行一次操作,FixPoint表示对树进行多次的迭代操作。RuleExecutor内部提供一个Seq[Batch]属性,里面定义的是RuleExecutor的处理逻辑,具体的处理逻辑由具体的Rule子类实现。
整个流程架构图:
二 Spark SQL运行原理
2.1 使用SessionCatalog保存元数据
在解析SQL语句之前,会创建SparkSession,或者如果是2.0之前的版本初始化SQLContext,SparkSession只是封装了SparkContext和SQLContext的创建而已。会把元数据保存在SessionCatalog中,涉及到表名,字段名称和字段类型。创建临时表或者视图,其实就会往SessionCatalog注册
2.2 解析SQL,使用ANTLR生成未绑定的逻辑计划
当调用SparkSession的sql或者SQLContext的sql方法,我们以2.0为准,就会使用SparkSqlParser进行解析SQL. 使用的ANTLR进行词法解析和语法解析。它分为2个步骤来生成Unresolved LogicalPlan:
# 词法分析:Lexical Analysis,负责将token分组成符号类
# 构建一个分析树或者语法树AST
2.3 使用分析器Analyzer绑定逻辑计划
在该阶段,Analyzer会使用Analyzer Rules,并结合SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
2.4 使用优化器Optimizer优化逻辑计划
优化器也是会定义一套Rules,利用这些Rule对逻辑计划和Exepression进行迭代处理,从而使得树的节点进行和并和优化
2.5 使用SparkPlanner生成物理计划
SparkSpanner使用Planning Strategies,对优化后的逻辑计划进行转换,生成可以执行的物理计划SparkPlan.
2.6 使用QueryExecution执行物理计划
此时调用SparkPlan的execute方法,底层其实已经再触发JOB了,然后返回RDD
SparkSql运行原理详细解析
传统关系型数据库中 ,最基本的sql查询语句由projecttion (field a,field b,field c) , datasource (table A) 和 fieter (field a >10) 三部分组成。 分别对应了sql查询过程中的result , datasource和operation ,也就是按照result ——> datasource ——> operation 的顺序来描述,如下图所示:
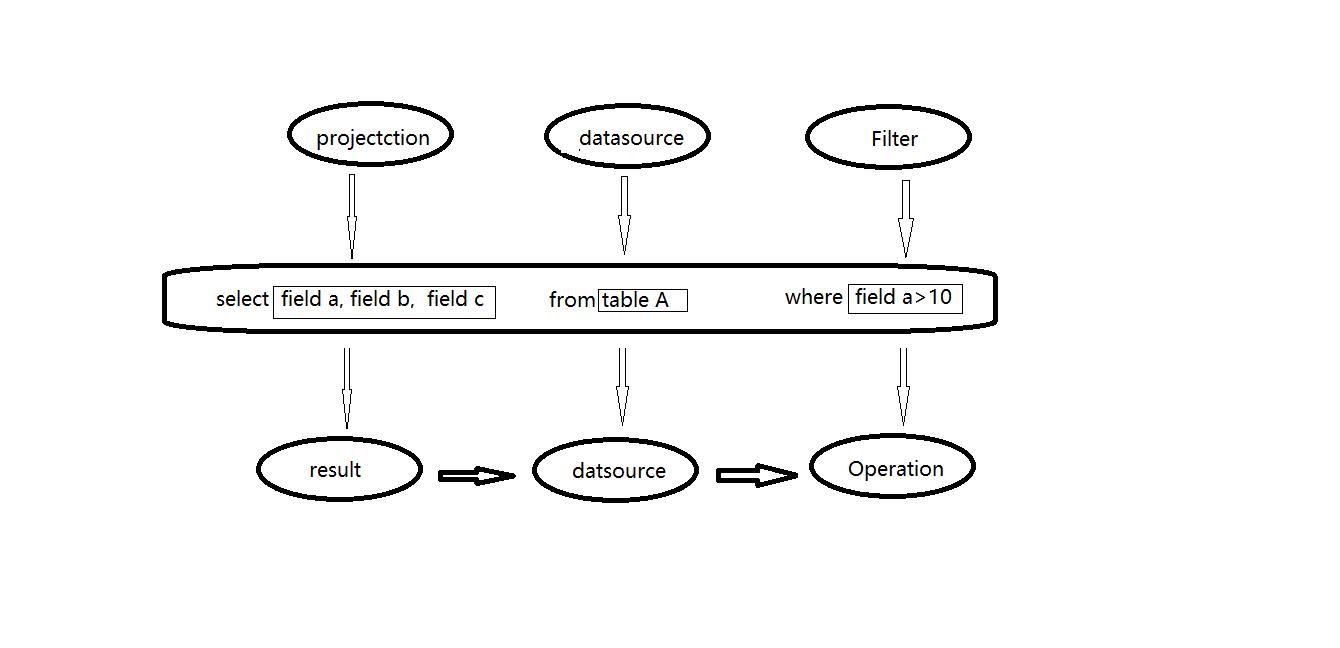
但是sql实际执行过程是按照operation——> datasource——>result 的顺序来执行的这与sql语法正好相反,具体的执行过程如下:
1 . 语法和词法解析:对写入的sql语句进行词法和语法解析(parse),分辨出sql语句在哪些是关键词(如select ,from 和where),哪些是表达式,哪些是projection ,哪些是datasource等,判断SQL语法是否规范,并形成逻辑计划。
2 .绑定:将SQL语句和数据库的数据字典(列,表,视图等)进行绑定(bind),如果相关的projection和datasource等都在的话,则表示这个SQL语句是可以执行的。
3 .优化(optimize):一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划。
4 .执行(execute):执行前面的步骤获取最有执行计划,返回查询的数据集。
SparkSQL的运行架构:
Spark SQL对SQL语句的处理和关系型数据库采用了类似的方法,sparksql先会将SQL语句进行解析(parse)形成一个Tree,然后使用Rule对Tree进行绑定,优化等处理过程,通过模式匹配对不同类型的节点采用不同操作。而sparksql的查询优化器是catalyst,它负责处理查询语句的解析,绑定,优化和生成物理执行计划等过程,catalyst是sparksql最核心部分。
Spark SQL由core,catalyst,hive和hive-thriftserver4个部分组成。
- core: 负责处理数据的输入/输出,从不同的数据源获取数据(如RDD,Parquet文件和JSON文件等),然后将结果查询结果输出成Data Frame。
- catalyst: 负责处理查询语句的整个处理过程,包括解析,绑定,优化,生成物理计划等。
- hive: 负责对hive数据的处理。
- hive-thriftserver:提供client和JDBC/ODBC等接口。
运行原理原理分析:
1.使用SesstionCatalog保存元数据
在解析sql语句前需要初始化sqlcontext,它定义sparksql上下文,在输入sql语句前会加载SesstionCatalog,初始化sqlcontext时会把元数据保存在SesstionCatalog中,包括库名,表名,字段,字段类型等。这些数据将在解析未绑定的逻辑计划上使用。
2.使用Antlr生成未绑定的逻辑计划
Spark2.0版本起使用Antlr进行词法和语法解析,Antlr会构建一个按照关键字生成的语法树,也就是生成的未绑定的逻辑计划。
3.使用Analyzer绑定逻辑计划
在这个阶段Analyzer 使用Analysis Rules,结合SessionCatalog元数据,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
4.使用Optimizer优化逻辑计划
Opetimize(优化器)的实现和处理方式同Analyzer类似,在该类中定义一系列Rule,利用这些Rule对逻辑计划和Expression进行迭代处理,达到树的节点的合并和优化。
5.使用SparkPlanner生成可执行计划的物理计划
SparkPlanner使用Planning Strategies对优化的逻辑计划进行转化,生成可执行的物理计划。
6.使用QueryExecution执行物理计划
Spark SQL原理详解及优化器
一.简介
从Spark 1.3开始,Spark SQL正式发布。而之前的另一个基于Spark的SQL开源项目Shark随之停止更新,基于Spark的最佳SQL计算就是Spark SQL。Spark SQL是Spark的一个模块,专门用于处理结构化数据。Spark SQL与Spark核心及其他模块之间的关系如下:

Spark SQL是用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。与Spark SQL交互的方法有很多种,包括SQL和Dataset API。计算结果时,将使用相同的执行引擎,而与用的表达计算API或语言无关。这种同一意味着开发人员可以轻松地在不同的API之间来回切换,从而提供最自然的方式表达给定的转换。
二.Dataset & DataFrame
数据集时数据的分布式集合。数据集是Spark 1.6中添加的新接口,它具有RDD的优点【强类型输入,使用强大的Lambda函数的能力】和Spark SQL的优化执行引擎的优点。数据集可以从JVM对象中构造,然后使用功能性的转换【操作map、flatMap、filter等】。Dataset API在Scala和Java中都可使用。Python不支持Dataset API。但是由于Python的动态特性,Dataset API的许多优点已经可用。R语言与之类似。
DataFrame从概念上讲,它等效于关系数据库中的表或R/Python中的数据框,但是在后台进行了更丰富的优化,可以从多种来源构造DataFrame。例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。DataFrame API在Scala,Java,Python和R中都可以使用。在Scala和Java中,DataFrame表示由Row构成的数据集。在Scala API中,DataFrame只是类型Dataset[Row]的别名。而在Java API中,用户需要使用Dataset<Row>来代表DataFrame。
官方解释:
Datasets and DataFrames
A Dataset is a distributed collection of data. Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine. A Dataset can be constructed from JVM objects and then manipulated using functional transformations (map, flatMap, filter, etc.). The Dataset API is available in Scala and Java. Python does not have the support for the Dataset API. But due to Python’s dynamic nature, many of the benefits of the Dataset API are already available (i.e. you can access the field of a row by name naturally row.columnName). The case for R is similar.
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. The DataFrame API is available in Scala, Java, Python, and R. In Scala and Java, a DataFrame is represented by a Dataset of Rows. In the Scala API, DataFrame is simply a type alias of Dataset[Row]. While, in Java API, users need to use Dataset<Row> to represent a DataFrame.
spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能。当然主要对类SQL的支持。
DataFrame 的函数
Action 操作
1、 collect() ,返回值是一个数组,返回dataframe集合所有的行
2、 collectAsList() 返回值是一个java类型的数组,返回dataframe集合所有的行
3、 count() 返回一个number类型的,返回dataframe集合的行数
4、 describe(cols: String*) 返回一个通过数学计算的类表值(count, mean, stddev, min, and max),这个可以传多个参数,中间用逗号分隔,如果有字段为空,那么不参与运算,只这对数值类型的字段。例如df.describe("age", "height").show()
5、 first() 返回第一行 ,类型是row类型
6、 head() 返回第一行 ,类型是row类型
7、 head(n:Int)返回n行 ,类型是row 类型
8、 show()返回dataframe集合的值 默认是20行,返回类型是unit
9、 show(n:Int)返回n行,,返回值类型是unit
10、 table(n:Int) 返回n行 ,类型是row 类型
dataframe的基本操作
1、 cache()同步数据的内存
2、 columns 返回一个string类型的数组,返回值是所有列的名字
3、 dtypes返回一个string类型的二维数组,返回值是所有列的名字以及类型
4、 explan()打印执行计划 物理的
5、 explain(n:Boolean) 输入值为 false 或者true ,返回值是unit 默认是false ,如果输入true 将会打印 逻辑的和物理的
6、 isLocal 返回值是Boolean类型,如果允许模式是local返回true 否则返回false
7、 persist(newlevel:StorageLevel) 返回一个dataframe.this.type 输入存储模型类型
8、 printSchema() 打印出字段名称和类型 按照树状结构来打印
9、 registerTempTable(tablename:String) 返回Unit ,将df的对象只放在一张表里面,这个表随着对象的删除而删除了
10、 schema 返回structType 类型,将字段名称和类型按照结构体类型返回
11、 toDF()返回一个新的dataframe类型的
12、 toDF(colnames:String*)将参数中的几个字段返回一个新的dataframe类型的,
13、 unpersist() 返回dataframe.this.type 类型,去除模式中的数据
14、 unpersist(blocking:Boolean)返回dataframe.this.type类型 true 和unpersist是一样的作用false 是去除RDD
DataFrame它不是spark sql提出来的,而是早期在R、Pandas语言就已经有了的
DataSet: A DataSet is a distributed collection of data. (分布式的数据集)
DataFrame:A DataFrame is a DataSet organized into named columns.
以列(列名,列类型,列值)的形式构成的分布式的数据集,按照列赋予不同的名称
三.整体架构
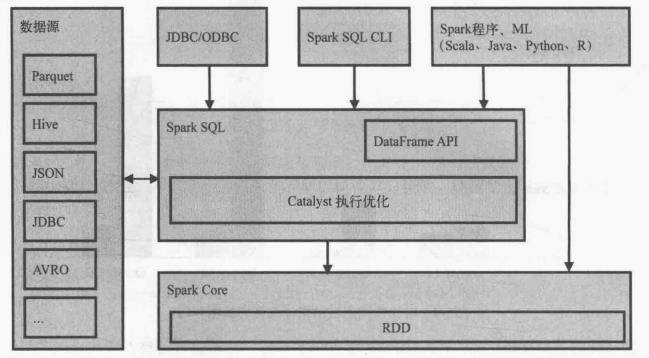
注意:Spark SQL是Spark Core之上的一个模块,所有SQL操作最终都通过Catalyst翻译成类似的Spark程序代码被Spark Core调度执行,其过程也有Job、Stage、Task的概念。
四.全局临时视图
Spark SQL中的临时视图是有会话作用域的,如果创建它的会话终止,它将消失。如果要在所有会话中共享一个临时视图并保存活动状态,直到Spark应用程序终止,则需要创建全局临时视图。全局临时视图与系统保留的数据库global_temp相关联,必须使用限定名称来引用它,代码例子如下:
df.createGlobalTempView("people")
// 全局临时视图与系统保留的数据库global_temp
spark.sql("select * from global_temp.people").show()
// 全局临时视图垮会话
spark.newSession().sql("select * from global_temp.people").show()
五.创建数据集
数据集与RDD相似,但是它们不是使用Java或Kryo进行序列化,而是使用专门的Encoder对对象进行序列化以进行网络处理或传输。虽然编码器和标准序列化都负责将对象转换为字节,但是编码器是动态生成的代码,并使用一种格式,该格式允许Spark执行许多操作,例如过滤,排序和哈希处理,而无需将字节反序列化为对象。

object DataSetDeml {
//设置日志级别
Logger.getLogger("org").setLevel(Level.WARN)
// 放在引用的函数外部
case class Person(name : String, age : Long)
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("Spark SQL").master("local[2]").getOrCreate()
// 数据集直接的转换
import spark.implicits._
// 使用样例类创建数据集
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).show()
}
}
执行结果:
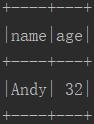

六.与RDD互操作
Spark SQL支持两种将现有RDD转换为数据集的方法。第一种方法使用反射来推断包含特定对象类型的RDD的架构。这种基于反射的方法可以使代码更简洁,并且当编写Spark应用程序时已经了解架构时,可以很好地工作。
创建数据集的第二种方法是通过编程界面,该界面允许构造模式,然后将其应用于现有的RDD。尽管此方法较为冗长,但可以在运行时才知道列及其类型的情况下构造数据集。
1.使用反射
object DataFrameDeml {
//设置日志级别
Logger.getLogger("org").setLevel(Level.WARN)
// 放在引用的函数外部
case class Technology(name : String, level : Long, age : Long)
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("Spark SQL").master("local[2]").getOrCreate()
// 数据集直接的转换
import spark.implicits._
val technology = spark.sparkContext
.textFile("D:\\\\software\\\\spark-2.4.4\\\\data\\\\sql\\\\dataframe.txt")
.map(_.split(","))
.map(row => Technology(row(0), row(1).toLong, row(2)toLong))
.toDF()
technology.show()
// 注册临时视图
technology.createOrReplaceTempView("technology")
// SQL查询
val level_2 = spark.sql("select name,age from technology where level = 2")
level_2.show()
// 指定编码器
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
val result = level_2.map(row => row.getValuesMap[Any](List("name", "age")))
result.show(false)
}
}
执行结果:



2.使用模式
val userData = Array(
"2015,11,www.baidu.com", "2016,14,www.google.com",
"2017,13,www.apache.com", "2015,21,www.spark.com",
"2016,32,www.hadoop.com", "2017,18,www.solr.com",
"2017,14,www.hive.com"
)
val userDataRDD = sc.parallelize(userData) // 转化为RDD
val userDataType = userDataRDD.map(line => {
val Array(age, id, url) = line.split(",")
Row(age, id.toInt, url)
})
val structTypes = StructType(Array(
StructField("age", StringType, true),
StructField("id", IntegerType, true),
StructField("url", StringType, true)
))
// RDD转化为DataFrame
val userDataFrame = sqlContext.createDataFrame(userDataType,structTypes)
七.Catalyst执行优化器
1 Catalyst最主要的数据结构是树,所有的SQL语句都会用树结构来存储,树中的每个节点都有一个类,以及0或多个子节点。Scala中定义的新的节点类型都是TreeNode这个类的子类,这些对象是不可变的。
2 Catalyst另外一个重要的概念是规则,基本上,所有的优化都是基于规则的。
3 执行过程
1 分析阶段
分析逻辑树,解决引用。
使用Catalyst规则和Catalog对象来跟踪所有数据源中的表,以解决所有未辨识的属性。
2 逻辑优化
3 物理计划
Catalyst会生成很多计划,并基于成本进行对比。接受一个逻辑计划作为输入,生产一个或多个物理计划。
4 代码生成
将Spark SQL代码编译成Java字节码。
以上是关于spark sql架构和原理——和Hive类似 dataframe无非是内存中的table而已 底层原始数据存储可以是parquet hive json avro等的主要内容,如果未能解决你的问题,请参考以下文章