虚拟机上dpdk例程收发包为0怎么办
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了虚拟机上dpdk例程收发包为0怎么办相关的知识,希望对你有一定的参考价值。
参考技术A 对于vmware的配置中,有几个要点:首先是cpu的数量,理论上越多越好。至少要准备2个核才能跑得起大部分的dpdk 示例。网卡是需要用intel的千兆网卡。在新版本中的vmware默认是intel网卡。修改方法如下:
找到虚拟机配置文件(*.vmx).
比如:
[html] view plain copy
ethernet0.present= "TRUE"
在下面添加
[html] view plain copy
ethernet0.virtualDev= "e1000"本回答被提问者采纳
DPDK 网卡收包流程
Table of Contents
文章内容整理自:https://mp.weixin.qq.com/s/FiNhgi316iiIEBFkbIbKHg
1、Linux网络收发包流程
1.1 网卡与liuux驱动交互
NIC 在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是 rx ring buffer。它是由 NIC 和驱动程序共享的一片区域,事实上,rx ring buffer 存储的并不是实际的 packet 数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
- 1.驱动在内存中分配一片缓冲区用来接收数据包,叫做 sk_buffer;
- 2.将上述缓冲区的地址和大小(即接收描述符),加入到 rx ring buffer。描述符中的缓冲区地址是 DMA 使用的物理地址;
- 3.驱动通知网卡有一个新的描述符;
- 4.网卡从 rx ring buffer 中取出描述符,从而获知缓冲区的地址和大小;
- 5.网卡收到新的数据包;
- 6.网卡将新数据包通过 DMA 直接写到 sk_buffer 中。
《搞懂Linux零拷贝,DMA》https://rtoax.blog.csdn.net/article/details/108825666

1.2 linux驱动与内核协议栈交互
当 NIC 把数据包通过 DMA 复制到内核缓冲区 sk_buffer 后,NIC 立即发起一个硬件中断。CPU 接收后,首先进入上半部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,之后由它发起软中断,进入下半部分,开始消费 sk_buffer 中的数据,交给内核协议栈处理。
题外1: 中断处理逻辑
Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。特点快速执行;
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。特点延迟执行;
上半部分硬件中断会打断 CPU 正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个 CPU 都对应一个软中断内核线程,名字为 “ksoftirqd/CPU 编号”,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。
通过下面命令可以查询软件中断线程:
通过下面命令行可以查询软件中断或者硬件终端的运行情况。
- /proc/softirqs 提供了软中断的运行情况;
- /proc/interrupts 提供了硬中断的运行情况。
《《深入浅出DPDK》读书笔记(八):网卡性能优化(异步中断模式、轮询模式、混和中断轮询模式)》
题外2:中断的弊端
中断,cpu能快速响应网卡的请求,但是大量数据包需要发送时,中断处理会降低cpu效率。
为了解决这个问题,现在的内核及驱动都采用一种叫 NAPI(new API)的方式进行数据处理,其原理可以简单理解为 中断 + 轮询,在数据量大时,一次中断后通过轮询接收一定数量包再返回,避免产生多次中断。
NAPI的精髓是在poll方式 / 纯中断方式之间自由灵活的游走切换。具体介绍下面文章查看。
《为什么系统调用会消耗较多资源?系统调用的三种方法:软件中断(分析过程)、SYSCALL指令、vDSO(虚拟动态链接对象linux-vdso.so.1)》
2、linux发包流程
- 应用程序调用 Socket API(比如 sendmsg)发送网络包。由于这是一个系统调用,所以会陷入到内核态的套接字层中。套接字层会把数据包放到 Socket 发送缓冲区中。
- 网络协议栈从 Socket 发送缓冲区中,取出数据包;再按照 TCP/IP 栈,从上到下逐层处理。比如,传输层和网络层,分别为其增加 TCP 头和 IP 头,执行路由查找确认下一跳的 IP,并按照 MTU 大小进行分片。
- 分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的 MAC 地址。然后添加帧头和帧尾,放到发包队列中。这一切完成后,会有软中断通知驱动程序:发包队列中有新的网络帧需要发送。
- 驱动程序通过 DMA ,从发包队列中读出网络帧,并通过物理网卡把它发送出去。
2、DPDK 收发包流程
2.1 网卡DMA描述符环形队列
DMA(Direct Memory Access,直接存储器访问)是一种高速的数据传输方式,允许在外部设备和存储器之间直接读写数据。数据既不通过CPU,也不需要CPU干预。整个数据传输操作在DMA控制器的控制下进行。除了在数据传输开始和结束时做一点处理外,在传输过程中CPU可以进行其他的工作。
网卡DMA控制器通过环形队列(网卡描述符队列)与CPU交互。环形队列由一组控制寄存器和一块物理上连续的缓存构成。主要的控制寄存器有Base、Size、Head和Tail。通过设置Base寄存器,可以将分配的一段物理连续的内存地址作为环形队列的起始地址,通告给DMA控制器。同样通过Size寄存器,可以通告该内存块的大小。Head寄存器往往对软件只读,它表示硬件当前访问的描述符单元。而Tail寄存器则由软件来填写更新,通知DMA控制器当前已准备好被硬件访问的描述符单元。
以Intel® 82599网卡为例,一个描述符大小为16B,整个环形队列缓冲区的大小必须是网卡支持的最大Cache line(128B)的整数倍,所以描述符的总数是8的倍数。当然,环形队列的起始地址也需要对齐到最大Cacheline的大小。
性能优化点:
- 描述符环形队列的内存 必须是cacheline 对齐的,避免cache 一致性问题。
- IO带宽的效率,决定有多少数据包能进入cpu处理,应用层在PCIe TLP上的开销决定了有效的可利用带宽。宽带的瓶颈可能出现在PCIE总线上。
lDMA操作可以利用Intel®处理器的Direct Data IO(DDIO)技术,利用LLC缓存,从而减少对内存的访问。
2.2 dpdk 收包流程
一个网络报文从网卡接收到被应用处理,中间主要需要经历两个阶段:
- 阶段一:网卡通过其DMA硬件将收到的报文写入到收包队列中(入队)
- 阶段二:应用从收包队列中读取报文(出队)。
1、构造收包队列
X710网卡由函数i40e_dev_rx_queue_setup完成收包函数的初始化。
int i40e_dev_rx_queue_setup(struct rte_eth_dev *dev,
uint16_t queue_idx,
uint16_t nb_desc,
unsigned int socket_id,
const struct rte_eth_rxconf *rx_conf,
struct rte_mempool *mp);收包队列的结构体为i40e_rx_queue,该结构体里包含两个重要的环形队列rx_ring和sw_ring,两个都是动态申请的连续数组环形队列,两者大小一直,互相对应的。
- rx_ring和sw_ring的关系可以简单如下认为。
- rx_ring主要存储报文数据的物理地址,物理地址供网卡DMA使用,也称为DMA地址(硬件使用物理地址,将报文copy到报文物理位置上)。
sw_ring主要存储报文数据的虚拟地址,虚拟地址供应用使用(软件使用虚拟地址,读取报文)。
/* * Structure associated with each RX queue. */
struct i40e_rx_queue
struct rte_mempool *mp; /**< mbuf pool to populate RX ring */
volatile union i40e_rx_desc *rx_ring;/**< RX ring virtual address */
uint64_t rx_ring_phys_addr; /**< RX ring DMA address */
struct i40e_rx_entry *sw_ring; /**< address of RX soft ring */
uint16_t nb_rx_desc; /**< number of RX descriptors */
uint16_t rx_free_thresh; /**< max free RX desc to hold */
uint16_t rx_tail; /**< current value of tail */
uint16_t nb_rx_hold; /**< number of held free RX desc */
....
rx_ring 描述符队列
- pkt_addr:报文数据的物理地址,网卡DMA将报文数据通过该物理地址写入对应的内存空间。
- hdr_addr:报文的头信息,hdr_addr的最后一个bit为DD位,因为是union结构,即status_error的最后一个bit也对应DD位。
- DD位(Descriptor Done Status)用于标志标识一个描述符buf是否可用。
网卡每次来了新的数据包,就检查rx_ring当前这个buf的DD位是否为0,如果为0那么表示当前buf可以使用,就让DMA将数据包copy到这个buf中,然后设置DD为1。如果为1,那么网卡就认为rx_ring队列满了,直接会将这个包给丢弃掉,记录一次imiss。
对于应用而言,DD位使用恰恰相反,在读取数据包时,先检查DD位是否为1,如果为1,表示网卡已经把数据包放到了内存中,可以读取,读取完后,再放入一个新的buf并把对应DD位设置为0。如果为0,就表示没有数据包可读。
union i40e_16byte_rx_desc
struct
__le64 pkt_addr; /* Packet buffer address */
__le64 hdr_addr; /* Header buffer address */
read;
struct
struct
struct
union
__le16 mirroring_status;
__le16 fcoe_ctx_id;
mirr_fcoe;
__le16 l2tag1;
lo_dword;
union
__le32 rss; /* RSS Hash */
__le32 fd_id; /* Flow director filter id */
__le32 fcoe_param; /* FCoE DDP Context id */
hi_dword;
qword0;
struct
/* ext status/error/pktype/length */
__le64 status_error_len;
qword1;
wb; /* writeback */
;SW_RING
mbuf:报文mbuf结构指针,mbuf用于管理一个报文,主要包含报文相关信息和报文数据。
/*sw ring */
struct i40e_rx_entry
struct rte_mbuf *mbuf;
;2.启动
int
rte_eth_dev_start(uint16_t port_id)
struct rte_eth_dev *dev;
struct rte_eth_dev_info dev_info;
int diag;
int ret;
RTE_ETH_VALID_PORTID_OR_ERR_RET(port_id, -EINVAL);
dev = &rte_eth_devices[port_id];
RTE_FUNC_PTR_OR_ERR_RET(*dev->dev_ops->dev_start, -ENOTSUP);
if (dev->data->dev_started != 0)
RTE_ETHDEV_LOG(INFO,
"Device with port_id=%"PRIu16" already started\\n",
port_id);
return 0;
ret = rte_eth_dev_info_get(port_id, &dev_info);
if (ret != 0)
return ret;
/* Lets restore MAC now if device does not support live change */
if (*dev_info.dev_flags & RTE_ETH_DEV_NOLIVE_MAC_ADDR)
rte_eth_dev_mac_restore(dev, &dev_info);
diag = (*dev->dev_ops->dev_start)(dev);
if (diag == 0)
dev->data->dev_started = 1;
else
return eth_err(port_id, diag);
ret = rte_eth_dev_config_restore(dev, &dev_info, port_id);
if (ret != 0)
RTE_ETHDEV_LOG(ERR,
"Error during restoring configuration for device (port %u): %s\\n",
port_id, rte_strerror(-ret));
rte_eth_dev_stop(port_id);
return ret;
if (dev->data->dev_conf.intr_conf.lsc == 0)
RTE_FUNC_PTR_OR_ERR_RET(*dev->dev_ops->link_update, -ENOTSUP);
(*dev->dev_ops->link_update)(dev, 0);
rte_ethdev_trace_start(port_id);
return 0;
收包队列的启动主要是通过调用rte_eth_dev_start(dpdk rte_ethdev.h)函数完成,收包队列初始化的核心流程如下。
static int __rte_cold
ixgbe_alloc_rx_queue_mbufs(struct ixgbe_rx_queue *rxq)
struct ixgbe_rx_entry *rxe = rxq->sw_ring;
uint64_t dma_addr;
unsigned int i;
/* Initialize software ring entries */
for (i = 0; i < rxq->nb_rx_desc; i++)
volatile union ixgbe_adv_rx_desc *rxd;
struct rte_mbuf *mbuf = rte_mbuf_raw_alloc(rxq->mb_pool);
if (mbuf == NULL)
PMD_INIT_LOG(ERR, "RX mbuf alloc failed queue_id=%u",
(unsigned) rxq->queue_id);
return -ENOMEM;
mbuf->data_off = RTE_PKTMBUF_HEADROOM;
mbuf->port = rxq->port_id;
dma_addr =
rte_cpu_to_le_64(rte_mbuf_data_iova_default(mbuf));
rxd = &rxq->rx_ring[i];
rxd->read.hdr_addr = 0;
rxd->read.pkt_addr = dma_addr;
rxe[i].mbuf = mbuf;
return 0;
循环从mbuf pool中申请mbuf,从mbuf中得到报文数据对应的物理地址,物理地址存入rx_ring中,mbuf指针存入sw_ring中。其中通过rxd->read.hdr_addr = 0,完成了DD位设置为0。
一切ok后,就可以开始收包了。
3.收包
收包由网卡入队和应用出队两个操作完成。
3.1入队
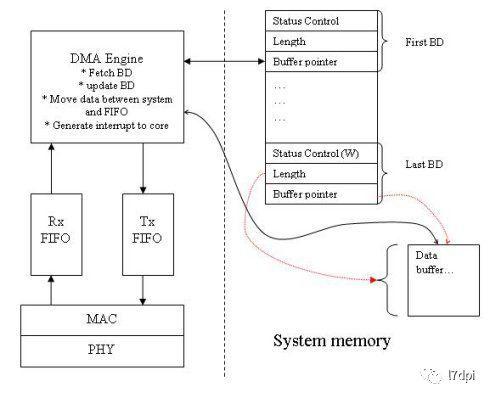
入队的操作是由网卡DMA来完成的,DMA(Direct Memory Access,直接存储器访问《搞懂Linux零拷贝,DMA》)是系统和网卡(外设)打交道的一种方式,该种方式允许在网卡(外部设备)和系统内存之间直接读写数据,这样能有效减轻CPU的工作。
网卡收到报文后,先存于网卡本地的buffer-Rx(Rx FIFO)中,然后由DMA通过PCI总线将报文数据写入操作系统的内存中,即数据报文完成入队操作。(PS:PCIe总线可能成为网卡带宽的瓶颈)
3.2.出队
static inline uint16_t
rte_eth_rx_burst(uint16_t port_id, uint16_t queue_id,
struct rte_mbuf **rx_pkts, const uint16_t nb_pkts)应用调用rte_eth_rx_burst(dpdk rte_ethdev.h)函数开始批量收包,最大收包数量由参数nb_pkts决定(比如设置为64)。其核心流程由ixgbe_recv_pkts(dpdk ixgbe_rxtx.c)实现,从收包队列rx_tail位置开始收,循环读取一个报文、填空一个报文(空报文数据),读取64个后,重新标记rx_tail的位置,完成出队操作,将收取的报文作返回供应用处理。代码简化如下。
struct rte_mbuf *rxm;
//从队列的tail位置开始取包
rx_id = rxq->rx_tail;
//循环获取nb_pkts个包
while (nb_rx < nb_pkts)
......
rxdp = &rx_ring[rx_id];
//检查DD位是否为1,是1则说明该位置已放入数据包,否则表示没有报文,退出
staterr=rxdp->wb.upper.status_error;
if(!(staterr&rte_cpu_to_le_32(IXGBE_RXDADV_STAT_DD)))
break;
rxd = *rxdp;
//申请一个mbuf(nmb),用于交换
nmb = rte_mbuf_raw_alloc(rxq->mb_pool);
//从sw_ring中读取一个报文mbuf(存入rxm)
rxe = &sw_ring[rx_id];
rxm = rxe->mbuf;
//往sw_ring中填空一个新报文mbuf(nmb)
rxe->mbuf = nmb;
//新mbuf对应的报文数据物理地址填入rx_ring对应位置,并将hdr_addr置0(DD位置0)
dma_addr =rte_cpu_to_le_64(rte_mbuf_data_dma_addr_default(nmb));
rxdp->read.hdr_addr = 0;
rxdp->read.pkt_addr = dma_addr;
//对读取mbuf的报文信息进行初始化
rxm->pkt_len = pkt_len;
rxm->data_len = pkt_len;
rxm->port = rxq->port_id;
......
//读取的报文mbuf存入rx_pkts
rx_pkts[nb_rx++] = rxm;
//重新标记rx_tail位置
rxq->rx_tail = rx_id;3、 PCIE 带宽调优
1)减少MMIO访问的频度。
高频度的寄存器MMIO访问,往往是性能的杀手。接收包时,尾寄存器(tail register)的更新发生在新缓冲区分配以及描述符重填之后。只要将每包分配并重填描述符的行为修改为滞后的批量分配并重填描述符,接收侧的尾寄存器更新次数将大大减少。DPDK是在判断空置率小于一定值后才触发重填来完成这个操作的。发送包时,就不能采用类似的方法。因为只有及时地更新尾寄存器,才会通知网卡进行发包。但仍可以采用批量发包接口的方式,填充一批等待发送的描述符后,统一更新尾寄存器。
(2)提高PCIe传输的效率。
每个描述符的大小是固定的,例如16Byte。每次读描述符或者写描述符都触发一次PCIe事务,显然净荷小,利用率低。如果能把4个操作合并成整Cache Line大小来作为PCIe的事务请求(PCIe净荷为64Byte),带宽利用率就能得到提升。另外,在发送方向,发送完成后回写状态到描述符。避免每次发送完成就写回,使用批量写回方式(例如,网卡中的RS bit),可以用一次PCIe的事务来完成批量(例如,32个为一组)的完成确认。
(3)尽量避免Cache Line的部分写。
DMA引擎在写数据到缓冲区的过程中,如果缓冲区地址并不是Cache Line对齐或者写入的长度不是整个Cache Line,就会发生Cache Line的部分写。Cache Line的部分写会引发内存访问read-modify-write的合并操作,增加额外的读操作,也会降低整体性能。所以,DPDK在Mempool中分配buffer的时候,会要求对齐到Cache Line大小。
4、软件调优
1、dpdk的轮询模式收包
《DPDK PMD( Poll Mode Driver)轮询模式驱动程序》
DPDK纯轮询模式是指收发包完全不使用中断处理的高吞吐率的方式;物理端口上的每一个收包队列,都会有一个对应的由收包描述符组成的软件队列来进行硬件和软件的交互,以达到收包的目的。
每一个收包队列,DPDK都会有一个对应的软件线程负责轮询里面的收包描述符的收包成功的标志。一旦发现某一个收包描述符的收包成功标志被硬件置位了,就意味着有一个包已经进入到网卡,并且网卡已经存储到描述符对应的缓冲内存块里面,这时候驱动程序会解析相应的收包描述符,提取各种有用的信息,然后填充对应的缓冲内存块头部。然后把收包缓冲内存块存放到收包函数提供的数组里面,同时分配好一个新的缓冲内存块给这个描述符,以便下一次收包。
每一个发包队列,DPDK都会有一个对应的软件线程负责设置需要发送出去的包,DPDK的驱动程序负责提取发包缓冲内存块的有效信息,例如包长、地址、校验和信息、VLAN配置信息等。DPDK的轮询驱动程序根据内存缓存块中的包的内容来负责初始化好每一个发包描述符,驱动程序会把每个包翻译成为一个或者多个发包描述符里能够理解的内容,然后写入发包描述符。其中最关键的有两个,一个就是标识完整的包结束的标志EOP (End Of Packet),另外一个就是请求报告发送状态RS (Report Status)。由于一个包可能存放在一个或者多个内存缓冲块里面,需要一个或者多个发包描述符来表示一个等待发送的包,EOP就是驱动程序用来通知网卡硬件一个完整的包结束的标志。每当驱动程序设置好相应的发包描述符,硬件就可以开始根据发包描述符的内容来发包,那么驱动程序可能会需要知道什么时候发包完成,然后回收占用的发包描述符和内存缓冲块。基于效率和性能上的考虑,驱动程序可能不需要每一个发包描述符都报告发送结果,RS就是用来由驱动程序来告诉网卡硬件什么时候需要报告发送结果的一个标志。
参考链接:
《FD.io VPP:探究分段场景下vlib_buf在收发包的处理》
《深入理解 Cilium 的 eBPF(XDP)收发包路径:数据包在Linux网络协议栈中的路径》
以上是关于虚拟机上dpdk例程收发包为0怎么办的主要内容,如果未能解决你的问题,请参考以下文章