python gbk 编码:'gbk'codec can't decode byte 0x81 in position 18
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python gbk 编码:'gbk'codec can't decode byte 0x81 in position 18相关的知识,希望对你有一定的参考价值。
UnicodeDecodeError:'gbk'codec can't decode byte 0x81 in position 18:illegal multibyte sequen。我尝试着从一个word 文档中读取文字 结果就出现这种情况。。。怎么解决啊 求高手指导
是因为python实现爬虫遇到编码问题:error:UnicodeEncodeError: 'gbk' codec can't encode character '\\xXX' in position XX。具体解决办法:
改变标准输出,添加代码。
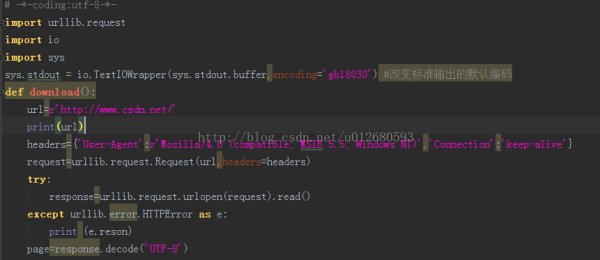
1、str转bytes叫encode,bytes转str叫decode。
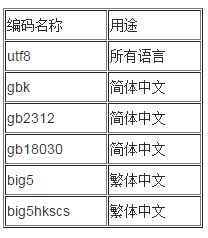
2、常用的中文编码名称
不过word文档是有结构的二进制文件,并非文本文件,最好用com接口操纵,你这种处理方法是错误的追问
麻烦棒我改下可以吗?刚开始学,有很多东西还不懂。。。谢谢了。。。。
参考技术B python3打开文件:
openfile = open(filename,'r',encoding = 'utf-8') 参考技术C .decode('gbk','ignore')追问
python3.3里好像有没有string.decode()这个内建方法了吧??
filename = open('hello.docx','r')
for eachline in filename:
print(eachline)
Python3文本编码错误:UnicodeDecodeError: 'gbk' codec can't decode byte
在一次使用python3读取文件时出现了一下错误信息
UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte
这是由于python在编解码过程中出现了错误,在python3中所有的字符编码都是Unicode编码,而在要读取的文件中存在中文,这个中文字符超出了GBK编码的表示范围,GBK编码不能对其进行解码,所以报错。
经过一番百度,找到下列解决方法:
1、打开文件时设置编码,如:open(‘1.txt’,encoding=’utf-8’)
2、若出现了超出GBK编码表示范围的字符,可以选择编码范围更广的‘gb18030’,open(‘1.txt’,encoding=’gb18030’)
3、文中出现了连‘gb18030’也无法编码的字符,可以使用‘ignore’属性进行忽略,open(‘1.txt’,encoding=’gb18030’,errors=‘ignore’)
4、还有一种常见解决方法为open(‘1.txt’).read().decode(‘gb18030’,’ignore’)
5、可以把 open 的方式变为二进制,open(filename,’rb’)
以上是关于python gbk 编码:'gbk'codec can't decode byte 0x81 in position 18的主要内容,如果未能解决你的问题,请参考以下文章