matplotlib可视化番外篇bar()--带误差棒的堆积柱状图
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了matplotlib可视化番外篇bar()--带误差棒的堆积柱状图相关的知识,希望对你有一定的参考价值。
参考技术A 相关函数:matplotlib.pyplot.bar()
在 barh()篇 堆积图部分粗略的写过一些,本节在那部分基础上补充对每一节柱状图添加误差棒,实现的方法类似 并列带误差棒的柱状图 ,对plt.bar()函数添加xerr或者yerr,然后对堆积在上面的柱状图添加bottom参数的数据信息。
最简实现:
实现效果:
[Python从零到壹] 番外篇之可视化利用D3库实现CSDN博客每日统计效果(类似github)
欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
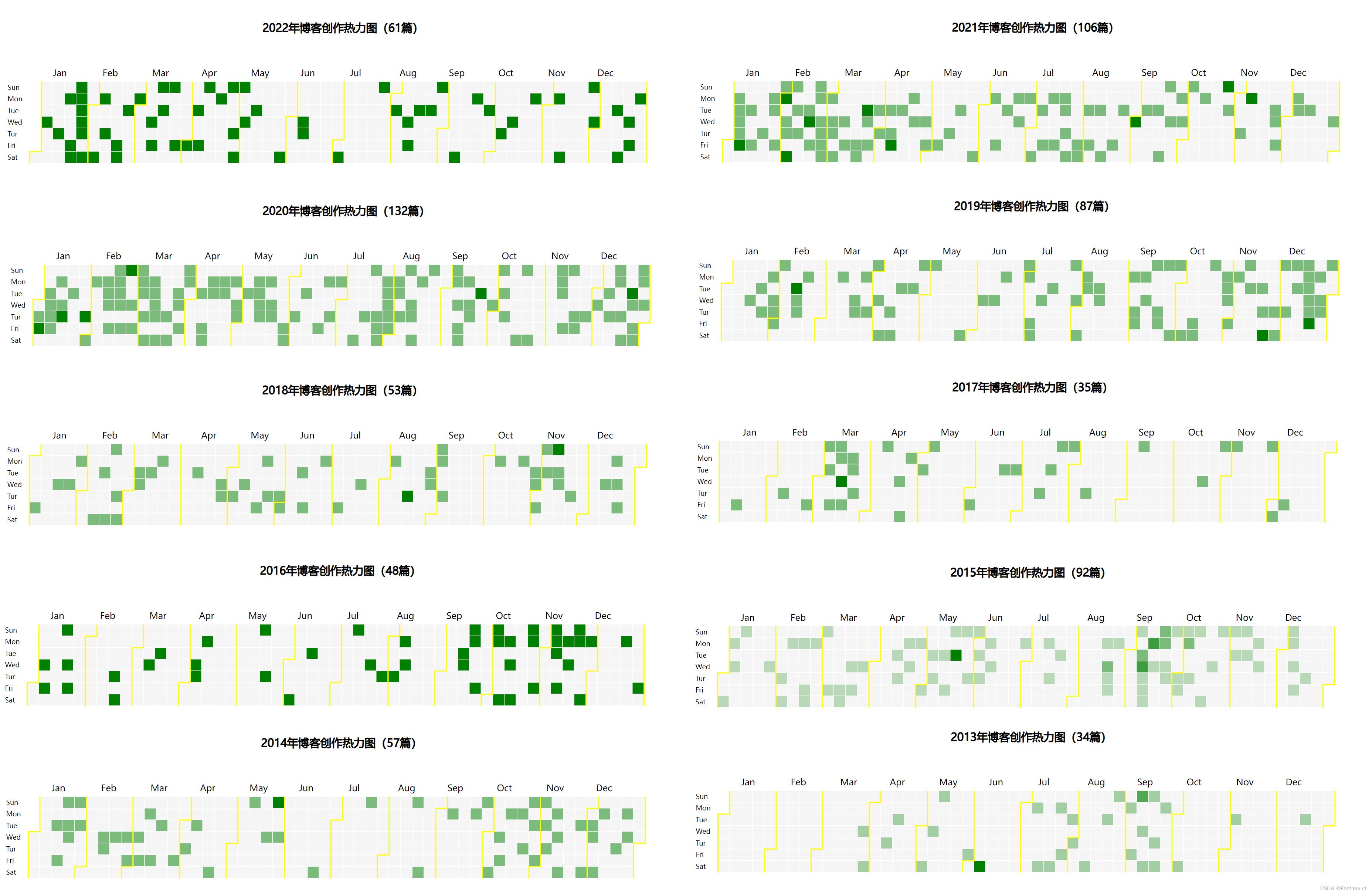
本文属于番外篇,主要介绍Python可视化分析,利用Python采集每年发表博客的数据,再利用D3实现类似于Github的每日贡献统计,显示效果如下图所示,也是回答读者之前的疑惑。这十多年在CSDN坚持分享,也是一笔宝贵的财务啊!希望文章对您有所帮助,如果有不足之处,还请海涵。
文章目录

该部分代码在作者Github的番外篇中可以下载,下载地址如下:
- https://github.com/eastmountyxz/Python-zero2one
- 开源600多页电子书:https://github.com/eastmountyxz/HWCloudImageRecognition
本文参考zjw666作者的D3代码,在此感谢,其地址如下:
前文赏析:(尽管该部分占大量篇幅,但我舍不得删除,哈哈!)
第一部分 基础语法
- [Python从零到壹] 一.为什么我们要学Python及基础语法详解
- [Python从零到壹] 二.语法基础之条件语句、循环语句和函数
- [Python从零到壹] 三.语法基础之文件操作、CSV文件读写及面向对象
第二部分 网络爬虫
- [Python从零到壹] 四.网络爬虫之入门基础及正则表达式抓取博客案例
- [Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
- [Python从零到壹] 六.网络爬虫之BeautifulSoup爬取豆瓣TOP250电影详解
- [Python从零到壹] 七.网络爬虫之Requests爬取豆瓣电影TOP250及CSV存储
- [Python从零到壹] 八.数据库之MySQL基础知识及操作万字详解
- [Python从零到壹] 九.网络爬虫之Selenium基础技术万字详解(定位元素、常用方法、键盘鼠标操作)
- [Python从零到壹] 十.网络爬虫之Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)
第三部分 数据分析和机器学习
- [Python从零到壹] 十一.数据分析之Numpy、Pandas、Matplotlib和Sklearn入门知识万字详解(1)
- [Python从零到壹] 十二.机器学习之回归分析万字总结全网首发(线性回归、多项式回归、逻辑回归)
- [Python从零到壹] 十三.机器学习之聚类分析万字总结全网首发(K-Means、BIRCH、层次聚类、树状聚类)
- [Python从零到壹] 十四.机器学习之分类算法三万字总结全网首发(决策树、KNN、SVM、分类算法对比)
- [Python从零到壹] 十五.文本挖掘之数据预处理、Jieba工具和文本聚类万字详解
- [Python从零到壹] 十六.文本挖掘之词云热点与LDA主题分布分析万字详解
- [Python从零到壹] 十七.可视化分析之Matplotlib、Pandas、Echarts入门万字详解
- [Python从零到壹] 十八.可视化分析之Basemap地图包入门详解
- [Python从零到壹] 十九.可视化分析之热力图和箱图绘制及应用详解
- [Python从零到壹] 二十.可视化分析之Seaborn绘图万字详解
- [Python从零到壹] 二十一.可视化分析之Pyechart绘图万字详解
- [Python从零到壹] 二十二.可视化分析之OpenGL绘图万字详解
- [Python从零到壹] 二十三.十大机器学习算法之决策树分类分析详解(1)
- [Python从零到壹] 二十四.十大机器学习算法之KMeans聚类分析详解(2)
- [Python从零到壹] 二十五.十大机器学习算法之KNN算法及图像分类详解(3)
- [Python从零到壹] 二十六.十大机器学习算法之朴素贝叶斯算法及文本分类详解(4)
- [Python从零到壹] 二十七.十大机器学习算法之线性回归算法分析详解(5)
- [Python从零到壹] 二十八.十大机器学习算法之SVM算法分析详解(6)
- [Python从零到壹] 二十九.十大机器学习算法之随机森林算法分析详解(7)
- [Python从零到壹] 三十.十大机器学习算法之逻辑回归算法及恶意请求检测应用详解(8)
- [Python从零到壹] 三十一.十大机器学习算法之Boosting和AdaBoost应用详解(9)
- [Python从零到壹] 三十二.十大机器学习算法之层次聚类和树状图聚类应用详解(10)
第四部分 Python图像处理基础
- [Python从零到壹] 三十三.图像处理基础篇之什么是图像处理和OpenCV配置
- [Python从零到壹] 三十四.OpenCV入门详解——显示读取修改及保存图像
- [Python从零到壹] 三十五.图像处理基础篇之OpenCV绘制各类几何图形
- [Python从零到壹] 三十六.图像处理基础篇之图像算术与逻辑运算详解
- [Python从零到壹] 三十七.图像处理基础篇之图像融合处理和ROI区域绘制
- [Python从零到壹] 三十八.图像处理基础篇之图像几何变换(平移缩放旋转)
- [Python从零到壹] 三十九.图像处理基础篇之图像几何变换(镜像仿射透视)
- [Python从零到壹] 四十.图像处理基础篇之图像量化处理
- [Python从零到壹] 四十一.图像处理基础篇之图像采样处理
- [Python从零到壹] 四十二.图像处理基础篇之图像金字塔向上取样和向下取样
第五部分 Python图像运算和图像增强
- [Python从零到壹] 四十三.图像增强及运算篇之图像点运算和图像灰度化处理
- [Python从零到壹] 四十四.图像增强及运算篇之图像灰度线性变换详解
- [Python从零到壹] 四十五.图像增强及运算篇之图像灰度非线性变换详解
- [Python从零到壹] 四十六.图像增强及运算篇之图像阈值化处理
- [Python从零到壹] 四十七.图像增强及运算篇之腐蚀和膨胀详解
- [Python从零到壹] 四十八.图像增强及运算篇之形态学开运算、闭运算和梯度运算
- [Python从零到壹] 四十九.图像增强及运算篇之顶帽运算和底帽运算
- [Python从零到壹] 五十.图像增强及运算篇之图像直方图理论知识和绘制实现
- [Python从零到壹] 五十一.图像增强及运算篇之图像灰度直方图对比分析万字详解
- [Python从零到壹] 五十二.图像增强及运算篇之图像掩膜直方图和HS直方图
- [Python从零到壹] 五十三.图像增强及运算篇之直方图均衡化处理
- [Python从零到壹] 五十四.图像增强及运算篇之局部直方图均衡化和自动色彩均衡化处理
- [Python从零到壹] 五十五.图像增强及运算篇之图像平滑(均值滤波、方框滤波、高斯滤波)
- [Python从零到壹] 五十六.图像增强及运算篇之图像平滑(中值滤波、双边滤波)
- [Python从零到壹] 五十七.图像增强及运算篇之图像锐化Roberts、Prewitt算子实现边缘检测
- [Python从零到壹] 五十八.图像增强及运算篇之图像锐化Sobel、Laplacian算子实现边缘检测
- [Python从零到壹] 五十九.图像增强及运算篇之图像锐化Scharr、Canny、LOG实现边缘检测
第六部分 Python图像识别和图像高阶案例
- [Python从零到壹] 六十.图像识别及经典案例篇之基于阈值及边缘检测的图像分割
- [Python从零到壹] 六十一.图像识别及经典案例篇之基于纹理背景和聚类算法的图像分割
- [Python从零到壹] 六十二.图像识别及经典案例篇之基于均值漂移算法和分水岭算法的图像分割
- [Python从零到壹] 六十三.图像识别及经典案例篇之图像漫水填充分割应用
第七部分 NLP与文本挖掘
第八部分 人工智能入门知识
第九部分 网络攻防与AI安全
第十部分 知识图谱构建实战
扩展部分 人工智能高级案例
作者新开的“娜璋AI安全之家”将专注于Python和安全技术,主要分享Web渗透、系统安全、人工智能、大数据分析、图像识别、恶意代码检测、CVE复现、威胁情报分析等文章。虽然作者是一名技术小白,但会保证每一篇文章都会很用心地撰写,希望这些基础性文章对你有所帮助,在Python和安全路上与大家一起进步。
一.博客数据采集
首先介绍博客数据采集方法,为保护CSDN原创,这里仅以方法为主。建议读者结合自己的方向去抓取文本知识。
1.数据采集
核心扩展包:
- import requests
- from lxml import etree
核心流程:
- 解决headers问题
- 解决翻页问题
- 审查元素分析DOM树结构
- 定位节点采用Xpath分析
- 分别采集标题、URL、时间、阅读和评论数量
审查元素如下图所示:

对应HTML代码如下:
<div class="article-list">
<div class="article-item-box csdn-tracking-statistics">
<h4 class="">
<a href="https://blog.csdn.net/Eastmount/article/details/124587047">
<span class="article-type type-1 float-none">原创</span>
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 (2)keras构建多头自注意力(Transformer)模型
</a>
</h4>
<p class="content">
本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。
前一篇文章利用Keras构建深度学习模型并实现了情感分析。这篇文章将介绍
Transformer基础知识,并通过Keras构建多头自注意力(Transformer)模型,
实现IMDB电影影评数据情感分析。基础性文章,希望对您有所帮助!...
</p>
<div class="info-box d-flex align-content-center">
<p>
<span class="date">2022-08-28 18:35:44</span>
<span class="read-num"><img src="" alt="">2852</span>
<span class="read-num"><img src="" alt="">4</span>
</p>
博客均是按照如下div进行布局。

该部分的关键代码如下:
# coding:utf-8
# By:Eastmount
import requests
from lxml import etree
#设置浏览器代理,它是一个字典
headers =
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \\
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
num = 2
url = 'https://xxxx/list/' + str(num)
#向服务器发出请求
r = requests.get(url = url, headers = headers).text
#解析DOM树结构
count = 0
html_etree = etree.HTML(r)
div = html_etree.xpath('//*[@class="article-list"]/div')
for item in div:
#标题
value = item.xpath('./h4/a/text()')
title = value[1].strip()
count += 1
print(title)
#时间
blog_time = item.xpath('./div/p/span[1]/text()')
print(blog_time)
print("博客总数:", count)
输出结果如下图所示:

如果需要进一步提取时间,则修改的代码如下所示:
#向服务器发出请求
r = requests.get(url = url, headers = headers).text
#解析DOM树结构
count = 0
title_list = []
time_list = []
year_list = []
html_etree = etree.HTML(r)
div = html_etree.xpath('//*[@class="article-list"]/div')
for item in div:
#标题
value = item.xpath('./h4/a/text()')
title = value[1].strip()
count += 1
print(title)
title_list.append(title)
#日期和时间
data = item.xpath('./div/p/span[1]/text()')
data = str(data[0])
#print(data)
#提取日期
year = data.split("-")[0]
month = data.split("-")[1]
day = data.split("-")[2].split(" ")[0]
blog_time = str(year) + "-" + month + "-" + day
print(blog_time, year)
time_list.append(blog_time)
year_list.append(year)
print("博客总数:", count)
输出结果如下图所示,每页共计40篇博客。

2.翻页采集数据
博客翻页主要通过循环实现,下图展示了翻页的网址。
此时增加翻页后的代码如下所示:
# coding:utf-8
# By:Eastmount
import requests
from lxml import etree
#设置浏览器代理,它是一个字典
headers =
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \\
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
num = 1
count = 0
title_list = []
time_list = []
year_list = []
while num<=18:
url = 'https://xxx/list/' + str(num)
#向服务器发出请求
r = requests.get(url = url, headers = headers).text
#解析DOM树结构
html_etree = etree.HTML(r)
div = html_etree.xpath('//*[@class="article-list"]/div')
for item in div:
#标题
value = item.xpath('./h4/a/text()')
title = value[1].strip()
count += 1
print(title)
title_list.append(title)
#日期和时间
data = item.xpath('./div/p/span[1]/text()')
data = str(data[0])
#提取日期
year = data.split("-")[0]
month = data.split("-")[1]
day = data.split("-")[2].split(" ")[0]
blog_time = str(year) + "-" + month + "-" + day
print(blog_time, year)
time_list.append(blog_time)
year_list.append(year)
num += 1
print("博客总数:", count)
print(len(title_list), len(time_list), len(year_list))
输出结果如下图所示,作者711篇博客均采集完成。

3.数据按年份存储
将所有博客时间存储至列表中,再按年份统计每天的发表次数,最终存储至Json文件,按照如下格式。

第一步,生成一年的所有日期,以2021年为例。
import arrow
#判断闰年并获取一年的总天数
def isLeapYear(years):
#断言:年份不为整数时抛出异常
assert isinstance(years, int), "请输入整数年,如 2018"
#判断是否是闰年
if ((years % 4 == 0 and years % 100 != 0) or (years % 400 == 0)):
days_sum = 366
return days_sum
else:
days_sum = 365
return days_sum
#获取一年的所有日期
def getAllDayPerYear(years):
start_date = '%s-1-1' % years
a = 0
all_date_list = []
days_sum = isLeapYear(int(years))
print()
while a < days_sum:
b = arrow.get(start_date).shift(days=a).format("YYYY-MM-DD")
a += 1
all_date_list.append(b)
return all_date_list
all_date_list = getAllDayPerYear("2021")
print(all_date_list)
输出结果如下所示:
['2021-01-01', '2021-01-02', '2021-01-03', ..., '2021-12-29', '2021-12-30', '2021-12-31']

第二步,遍历一年所有日期发表博客的数量。
#--------------------------------------------------------------------------
#遍历一年所有日期发表博客的数量
k = 0
res =
while k<len(all_date_list):
tt = all_date_list[k]
res[tt] = 0
m = 0
while m<len(time_list):
tt_lin = time_list[m]
if tt==tt_lin:
res[tt] += 1
m += 1
k += 1
print("\\n------------------------统计结束-------------------------\\n")
print(res)
#统计发表博客数
count_blog = 0
for i in res.keys():
if res[i] > 0:
count_blog += res[i]
print(count_blog)
输出结果可以看到2021年作者发表博客106篇,并且形成该年的每日发表博客数。

第三步,存储至Json文件。
#--------------------------------------------------------------------------
#存储至Json文件
import json
print(type(res), len(res))
with open("data-2021.json", "w", encoding='utf-8') as f:
json.dump(res, f)
print("文件写入....")
最终生成结果如下图所示:


4.完整代码
完整代码如下所示,修改近十年的年份,将生成不同的博客数量。
- 2022年:61篇
- 2021年:106篇
- 2020年:132篇
- 2019年:87篇
- 2018年:53篇
- 2017年:35篇
- 2016年:48篇
- 2015年:92篇
- 2014年:57篇
- 2013年:34篇
# coding:utf-8
# By:Eastmount
import requests
from lxml import etree
#--------------------------------------------------------------------------
#采集CSDN博客数据
headers =
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \\
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
num = 1
count = 0
title_list = []
time_list = []
year_list = []
while num<=18:
url = 'https://xxx/list/' + str(num)
#向服务器发出请求
r = requests.get(url = url, headers = headers).text
#解析DOM树结构
html_etree = etree.HTML(r)
div = html_etree.xpath('//*[@class="article-list"]/div')
for item in div:
#标题
value = item.xpath('./h4/a/text()')
title = value[1].strip()
count += 1
#print(title)
title_list.append(title)
#日期和时间
data = item.xpath('./div/p/span[1]/text()')
data = str(data[0])
#提取日期
year = data.split("-")[0]
month = data.split("-")[1]
day = data.split("-")[2].split(" ")[0]
blog_time = str(year) + "-" + month + "-" + day
#print(blog_time, year)
time_list.append(blog_time)
year_list.append(year)
num += 1
print("博客总数:", count)
print(len(title_list), len(time_list), len(year_list))
#--------------------------------------------------------------------------
#生成一年所有日期
import arrow
#判断闰年并获取一年的总天数
def isLeapYear(years):
#断言:年份不为整数时抛出异常
assert isinstance(years, int), "请输入整数年,如 2018"
#判断是否是闰年
if ((years % 4 == 0 and years % 100 != 0) or (years % 400 == 0)):
days_sum = 366
return days_sum
else:
days_sum = 365
return days_sum
#获取一年的所有日期
def getAllDayPerYear(years):
start_date = '%s-1-1' % years
a = 0
all_date_list = [以上是关于matplotlib可视化番外篇bar()--带误差棒的堆积柱状图的主要内容,如果未能解决你的问题,请参考以下文章
Python-Matplotlib可视化(番外篇)——Matplotlib中的事件处理详解与实战
OpenCV-Python实战(番外篇)——OpenCVNumPy和Matplotlib直方图比较
[Python从零到壹] 番外篇之可视化利用D3库实现CSDN博客每日统计效果(类似github)