Linux 命令合集(二):查看文件及内容处理命令
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 命令合集(二):查看文件及内容处理命令相关的知识,希望对你有一定的参考价值。
参考技术A 例1: cat -n:对所有行进行编号:例2. cat -b:对所有非空行进行编号
例4.cat >cat.log<<EOF:将标准输入的内容写入到文件中;输入EOF结束
例一:显示文件的前五个字符
例二:不显示符合条件的列
例:按1M大小分割文件并指定分割后的文件名
例一:
例二:
例:忽略每行开始处的空白字符,对第二域按数字大小进行排序
正则表达式
grep支持的字符和字符集合
例一:显示meminfo文件中以不区分大小的s开头的行
例二:显示/etc/passwd中,以r开头的字符而后跟了任意单个字符的行
例四:显示/etc/passwd中,r后跟了o,o只出现2次的行
例五:显示meminfo文件中以一个数字开头并以一个与开头数字相同的数字结尾的行
例六:匹配ABC类IP地址即 1.0.0.1---223.255.255.254
例七:匹配手机号码:手机号码是1[3|4|5|8]后面接9位数字的
例一:将大写字符转换为小写字符
例二:删除指定范围的字符
例三:删除指定范围字符的补集
more(less):分页显示文件内容
head(tail):显示文件内容头部
join:将两个文件中,制定栏位内容相同的行连接起来
iconv:转换文件编码格式
dos2unix:将dos文件格式转换为Unix格式
diff(vimdiff):比较文件差异
rev:反向输出文件内容
Linux 入门记录:十七Linux 文本/文件处理命令
一、文件浏览
cat 查看文件内容 more 以翻页形式查看文件内容(只能向下翻页) less 以翻页形式查看文件内容(可以上下翻页) head 查看文件的头几行(默认10行) tail 查看文件的尾几行(默认10行)
二、正则匹配打印行
命令 grep 用来全局匹配正则表达式并打印所在行:
grep \'mingc\' /etc/passwd 在该文件中匹配mingc的用户信息并打印所在行 find / -user mingc | grep ".*\\.png$" 查找mingc的所有png文件(管道操作)
常用参数:
-i 搜索时忽略大小写 -n 显示结果所在行数 -v 输出不匹配该正则的行(类似于一个取反操作) -An 在输出的时候包含结果所在行之后的指定n行 -Bn 在输出的时候包含结果所在行之前的指定n行
三、文本切割打印字段
命令 cut 常用来切割文本行、打印某些字段:
cut -d:fl /etc/passwd 打印passwd文件中冒号分割的第1个字段(用户名)(列出来多行的用户名) grep mingc /etc/passwd | cut -d: -f3 打印mingc的用户信息汇总冒号分割的第3个字段(uid)
常用参数:
-d 指定分割字符(默认Tab) -f 显示特定序号的字段(从1开始) -c 显示特定范围字符(从第几个到第几个)
示例:
grep mingc /etc/passwd | cut -d: -f3 打印mingc的用户信息中冒号分割的第3个字段(uid) grep mingc /etc/passwd | cut -d: -f6,7 打印mingc的用户主目录和登录Shell grep mingc /etc/passwd | cut -c1-5 打印mingc的用户信息中第1~5个字符 grep mingc /etc/passwd | cut -c1- 打印mingc的用户信息中第1个字符之后的所有字符 grep mingc /etc/passwd | cut -c-5 打印mingc的用户信息中第5个字符之前的所有字符
四、文本统计
命令 wc 用于统计文件的行数、单词数、字符数等:
wc test.md
不带参数时默认输出一行,字段格式为:
行数 单词数 字符数 文件名
常用参数:
-l 只统计行数 -w 只统计单词数 -c 只统计字节数 -m 只统计字符数
五、文本排序
命令 sort 用于对文件内容进行排序(也可以对STDIN进行排序):
sort filename
常用参数:
-r 逆向(倒序)排序 -n 基于数字排序 -f 忽略大小写 -u 去重复(剔除重复行) -t<分割符> 指定分隔符(一般配合-k参数使用,单纯分割毫无意义) -k n 当指定分割符时,按照第n个字段进行排序(序号n从1开始)
-r、-n、-t、-k 参数可以配合使用:
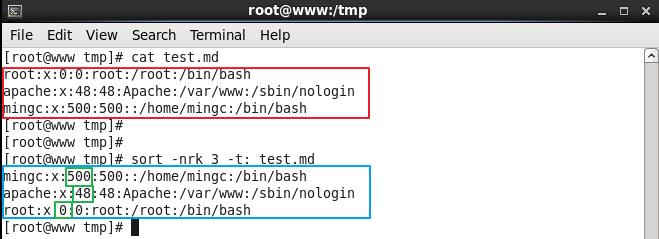
上图中,把 test.md 文件内容的每行按照冒号分割、基于数字对第3个字段进行逆向排序。
六、剔除重复行
命令 sort -u 可以剔除文件内容重复行,但副作用是进行了排序。
命令 uniq 可以剔除文件内容(相邻的)重复行:

七、文本比较
命令 diff 用来比较两个文件的区别:
diff test1.md test2.md
常用参数:
-i 忽略大小写 -b 忽略空格字符 -u 统一显示比较信息(一般用来生成patch文件)
示例:
diff -u old.md new.md > update.patch 把文件的更新信息生成到补丁文件
八、拼写检查
命令 aspell 用来显示检查英文拼写:
aspell check filename aspell list < filename
(CentOS 6.9 64位系统里似乎没有这个命令,也不常用,不详述)
九、字符转换
命令 tr 用于从标准输入对字符进行转换处理。如果处理来自文件的输入,需要重定向。
删除关键字:
tr -d \'keyword\' < filename
转换大小写:
tr \'a-z\' \'A-Z\' < filename
十、流式编辑——搜索替换
sed 命令是一种可以配合正则表达式使用的流式编辑工具。处理文件流时,把当前处理的行存储在临时缓冲区,称“模式空间”(pattern space),然后处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有发生改变,除非使用重定向存储输出。sed 命令主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
语法:
sed [options] \'command\' file(s) sed [options] -f scriptfile file(s)
常用参数 options:
-e<script> 指定一个script来处理文本 -f<script> 指定一个script来处理文本 -n 仅显示处理后的结果
常用命令 command:
d 删除行 D 删除第一行 s 替换指定字符 h 拷贝内容到缓冲区 H 追加内容到缓冲区 g 获取缓冲区的内容,替换当前文本 G 获取缓冲区的内容,追加到当前文本后面 p 打印行 P 打印第一行 q 退出sed
示例:
sed \'s/linux/unix/g\' filename s表示搜索替换,linux替换为unix,g表示全局替换,filename目标文件 sed \'l,50s/linux/unix/g\' filename 1到50行进行全局替换 sed -e \'s/linux/unix/g\' -e \'s/ming/mingc/g\' filename -e参数替换多个 sed -f script filename 指定一个script来处理文件
相关链接:sed 命令 - Linux 命令大全
以上是关于Linux 命令合集(二):查看文件及内容处理命令的主要内容,如果未能解决你的问题,请参考以下文章