C语言读取UTF-8文本
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C语言读取UTF-8文本相关的知识,希望对你有一定的参考价值。
有一个文本文件是以UTF-8编码的,用C语言读入时出现错误,内容如下:
1 sheer /ʃiә/adj.完全的,十足的;陡峭的,垂直的;极薄的,透明的adv.垂直地,陡峭地vi.(off)急转向,偏离
2 comment /kɔment/n.评论,意见;注释
3 distress /dis'tres/n.忧虑,悲伤;不幸
如果把它保存成ASCII 编码的文本就可以正确读入,但那样音标就不能正确显示了:
1 sheer /?i?/adj.完全的,十足的;陡峭的,垂直的;极薄的,透明的adv.垂直地,陡峭地vi.(off)急转向,偏离
2 comment /k?ment/n.评论,意见;注释
3 distress /dis'tres/n.忧虑,悲伤;不幸
我想这是编码的问题,请请问怎么解决啊?
1个字节:0XXXXXXX
2个字节:110XXXXX 10XXXXXX /> 3个字节: 1110XXXX 10XXXXXX 10XXXXXX
4个字节:11110xxx 10XXXXXX 10XXXXXX 10XXXXXX
本文根据上面的字符串遍历的特点来确定一个字符串是否是UTF-8编码。应当注意的是,每个字节的UTF-8字符串的值具有一定的范围,而不是所有的值?是有效的UTF-8字符,但在一般应用足够长的字符串判断的情况下,更准确,是实现比较简单。具体的字节范围,可以发现在这本书的“Unicode解释”6.4.3。
布尔IsUTF8(const void *的pbuffer的,长尺寸)
布尔IsUTF8 = TRUE;
unsigned char型*开始=(无符号字符*)pbuffer的/无符号的char *结束=(unsigned char型)pbuffer的+大小;
(起点和终点)
(*开始<0X80)/ /(10000000):值小于0x80的ASCII的字符
开始+ +;
否则,如果(*启动<(0XC0))/ /(11000000):值吗? 0XC0之间的范围0x80无效的UTF-8字符
IsUTF8 = FALSE;
突破;
否则,如果(*开始(0XE0))/在2个字节的UTF-8字符/(11100000):
(开始> =结束 - 1)
突破;
((开始[1](0XC0) )= 80H时)
IsUTF8 = FALSE;
突破;
开始+ = 2;
否则,如果(*启动<(31:8))/ /(11110000):结束的3个字节的UTF-8字符
(“开始”> = - 2)
突破;。 .. />((开始[1](为0xC0))= 0x80的| |(启动[2](为0xC0))= 80H时)
IsUTF8 = FALSE;
休息
开始+ = 3;
IsUTF8 = FALSE;
突破;
回报IsUTF8;
UTF-UCS编码的16至16个单位。小于0x10000的UCS码,UTF-16编码是等于相应的UCS代码的16位无符号整数。对于不小于0x10000的UCS码,定义了一个算法。然而,实际使用的UCS2,或者UCS4的BMP必然小于0x10000,所以现在你可以认为UTF -16和UCS-2基本相同。 UCS-2是一种编码方案,UTF-16已被用于实际的传输,所以我们要考虑的字节顺序。本回答被提问者和网友采纳 参考技术B 不要用char,用w_char处理就可以了
如何读取CSV文件后合并内容
参考技术A两张表:ReaderInformation.csv,ReaderRentRecode.csv
ReaderInformation.csv: 
ReaderRentRecode.csv: 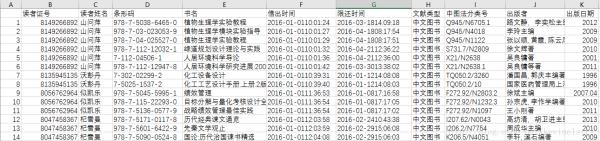
pandas读取csv文件,并进行csv文件合并处理:
# -*- coding:utf-8 -*-import csv as csvimport numpy as np# -------------# csv读取表格数据# -------------'''
csv_file_object = csv.reader(codecs.open('ReaderRentRecode.csv', 'rb'))
header = csv_file_object.next()
print header
print type(header)
print header[1]
data = []
for row in csv_file_object:
data.append(row)
data = np.array(data)
print data[0::, 0]
'''# -------------# pandas读取表格数据# -------------import pandas as pd
df = pd.read_csv('ReaderRentRecode.csv') # 读者借阅信息表'''
print df.head()
print '----------------'
print df[['读者证号', '读者姓名', '书名', '中图法分类号']] # 选取其中的四列
print '------------------------------------------------------------------'
print
'''dd = pd.read_csv('ReaderInformation.csv')'''
print dd.head()
print '----------------'
print dd[['读者证号', '读者性别', '读者单位', '读者类别']]
print '------------------------------------------------------------------'
print
'''data = pd.merge(df, dd, on=['读者证号', '读者姓名'], how='left') # pandas csv表左连接data = data[['读者证号', '读者姓名', '读者性别', '书名', '中图法分类号', '读者单位', '读者类别']]print dataprint '------------------------------------------------------------------'print# -------------# pandas写入表格数据# -------------data.to_csv(r'data.csv', encoding='gbk')123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354
合并后的csv文件:data.csv 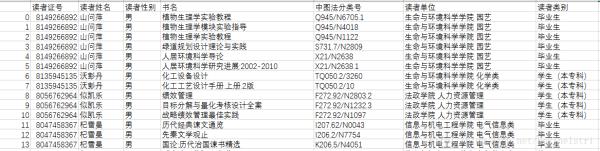
通过使用pandas的函数merge来进行两个表的左连接,最后得到相应的data.csv文件。
以上是关于C语言读取UTF-8文本的主要内容,如果未能解决你的问题,请参考以下文章