爬虫之抓取js生成的数据
Posted W的一天
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫之抓取js生成的数据相关的知识,希望对你有一定的参考价值。
有很多页面,当我们用request发送请求,返回的内容里面并没有页面上显示的数据,主要有两种情况,一是通过ajax异步发送请求,得到响应把数据放入页面中,对于这种情况,我们可以查看关于ajax的请求,然后分析ajax请求路径和响应,拿到想要的数据;另外一种就是js动态加载得到的数据,然后放入页面中。这两种情况下,对于用户利用浏览器访问时,都不会发现有什么异常,会迅速的得到完整页面。
其实我们之前学过一个selenium模块,通过操纵浏览器,然后拿到浏览器显示出来的数据,这种方式是可以拿到数据的,但本节是要分析如何找到那个js在控制数据的生成,及js发送请求的路径,从而我们可以向这个路径发送请求,直接就得到数据。
在之前的爬虫过程中,我最烦的就是关于js动态生成的数据,我根本无法找到是哪一个js实现的(因为js太多了),今天看了大佬的博客,瞬间感觉简单了很多,谢谢大佬,祭出大佬的博客:https://www.cnblogs.com/bobo-zhang/p/10561617.html
一、需求描述及页面分析
1,需求描述
基础页面路径:https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html
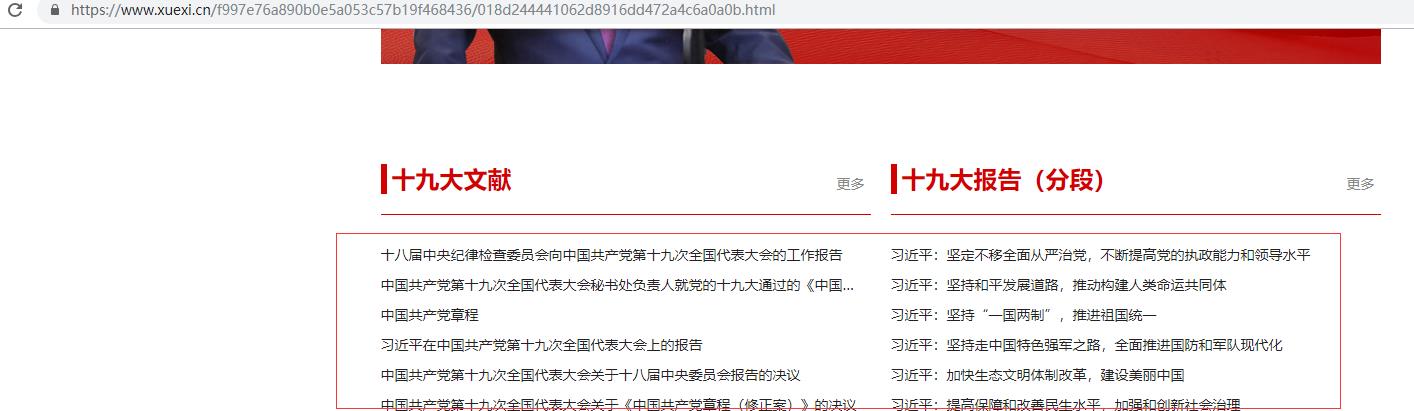
点击进入每个标题里面:
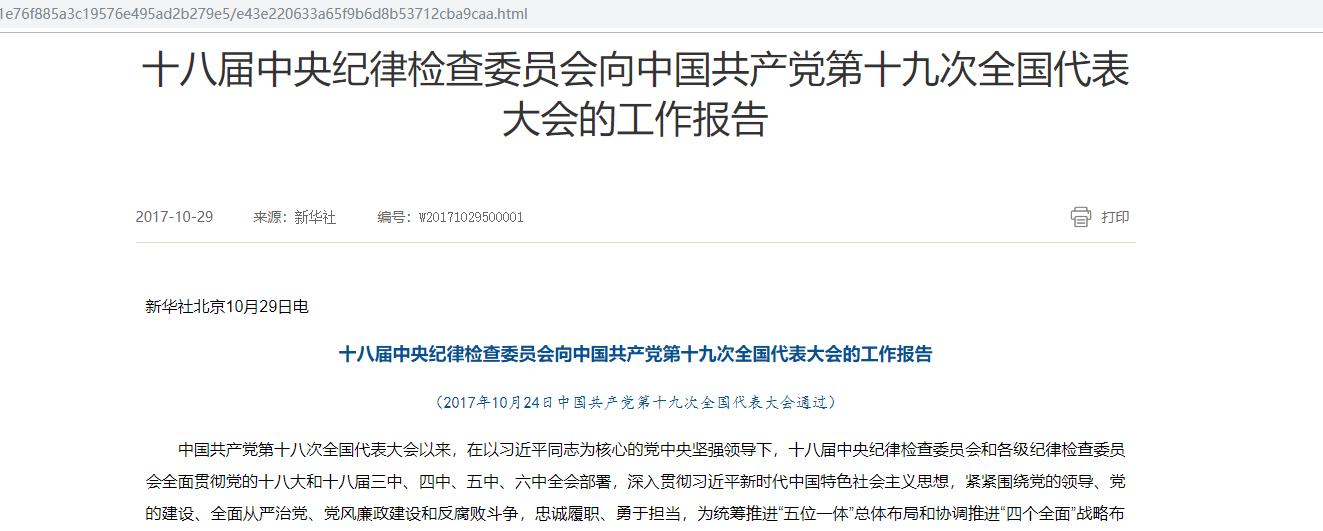
需求就是爬取每个标题下的新闻内容
2,页面分析
2.1 主页面
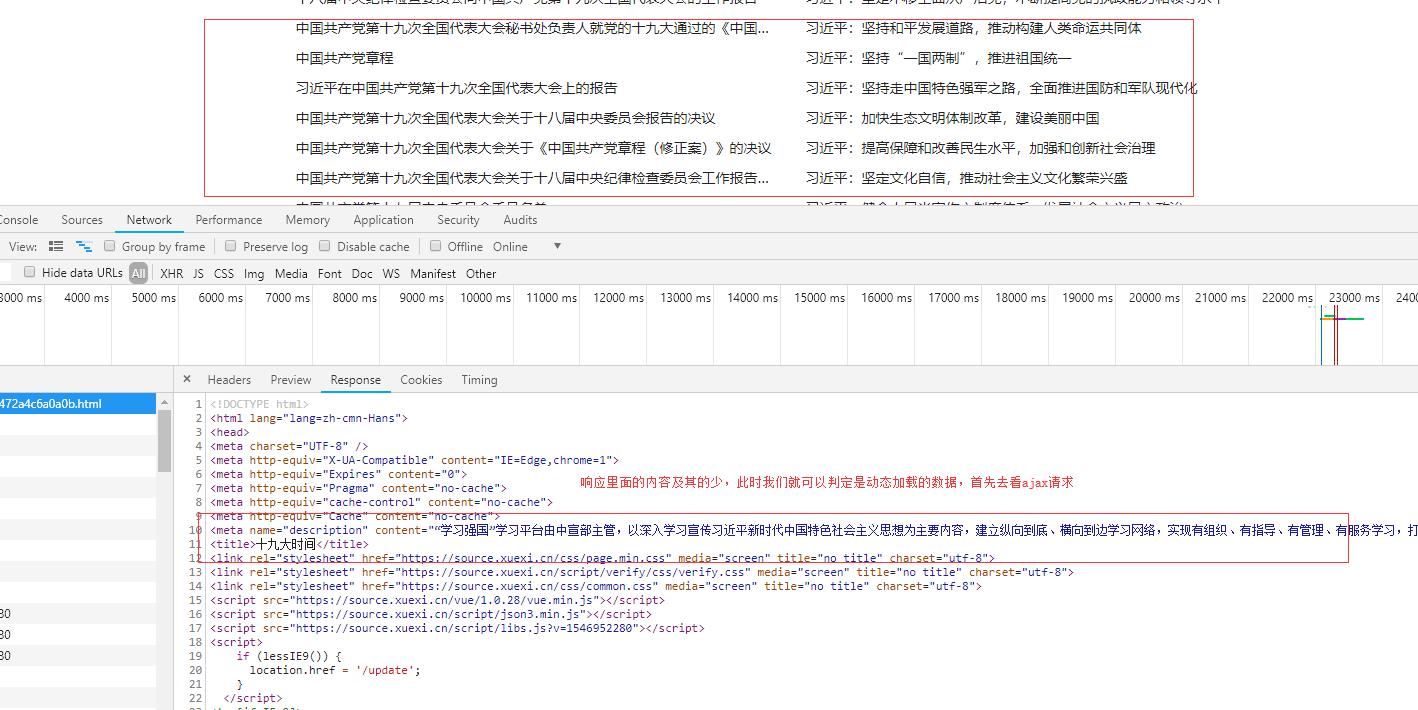
查看ajax请求:
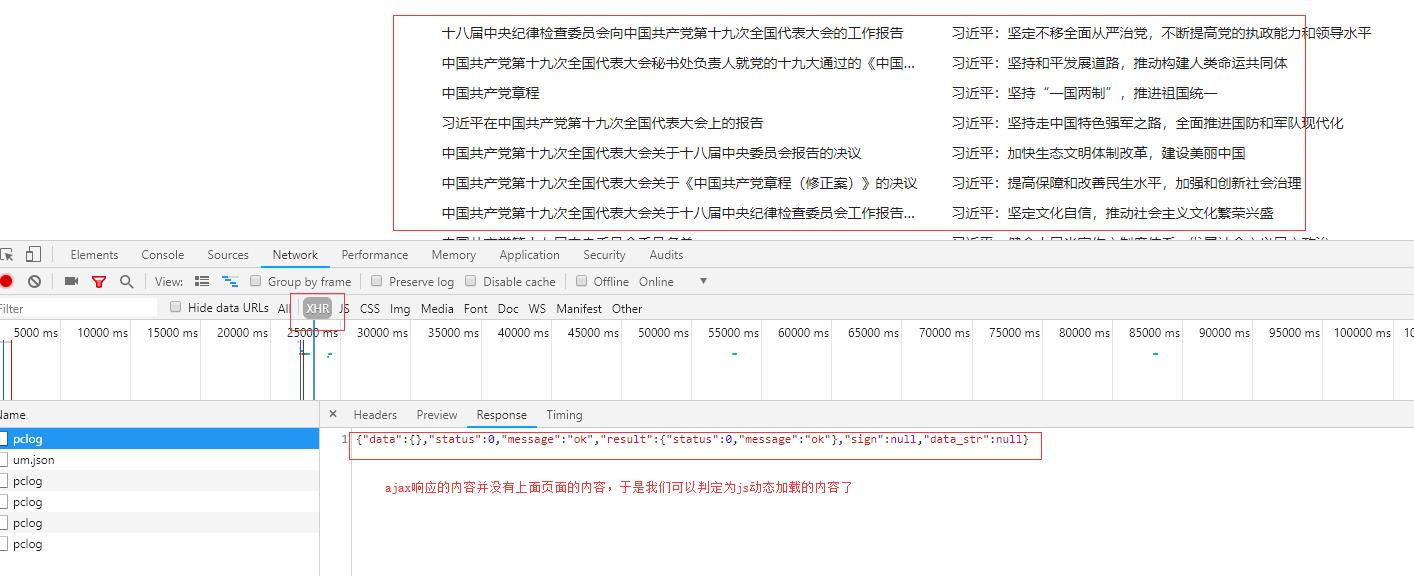
接下来我们就解析如何找出发送请求的js
二、查找发送请求的js

在响应的数据里,包含新闻标题,以及本条新闻的详情页路径,于是现在我们去访问详情页,以及分析详情页
访问详情页,查看详情页的响应,数据里面也没包含具体数据,那它就和主页面一样,接下来去看ajax:
ajax并没有新闻相关数据,所以不是利用ajax请求拿到数据的,那只有剩下js了,我们就去寻找是哪个js发送的请求来获取数据,步骤上面一致:

详情页数据的js请求路径:

详情页请求路径:

我们可以看到,详情页数据的请求路径在最后一个斜杠前面的路径和详情页的请求路径在最后一个斜杠前面都是一样的。于是我们可以这样:
第一步:拿到详情页的请求路径: url1=\'https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/e43e220633a65f9b6d8b53712cba9caa.html\' 第二步:把url1最后一个斜杠后面的内容替换掉 url2=\'https://www.xuexi.cn/%s/datae43e220633a65f9b6d8b53712cba9caa.js\'%(url1.split(\'/\')[3]) #把url1用‘/’分割,拿到第四部分,即索引为3,然后拼接进去既可 这样就构造好了一个详情页数据请求路径,然后直接去访问这个路径既可拿到数据,就不用去访问详情页了
以上是关于爬虫之抓取js生成的数据的主要内容,如果未能解决你的问题,请参考以下文章