消费者遗除是
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了消费者遗除是相关的知识,希望对你有一定的参考价值。
参考技术A kafka消费方式(1)pull(拉)模式:
consumer采用从broker中主动拉取数据。 Kafka采用了这种方式。
(2)push(推)模式:
Kafka没有采用这种方式,因为由broker决定消息发送速率,很难适应所有消费者的消费速率。
例如推送的速度是50m/s,Consumer1、Consumer2就来不及处理消息。
pull模式不足之处是,如果Kafka没有数据,消费者可能会陷入循环中,一直返回空数据。
kafka消费者工作流程
消费者总体工作流程
消费者组原理
Consumer Group(CG):消费者组,由多个consumer组成;形成一个消费者组的条件是所有消费者的groupid相同。
(1)消费者组
1)消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
2)消费者组之间互不影响;如果所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
3)如果向消费组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息。
(2)消费者组初始化流程
coordinator:辅助实现消费者组的初始化和分区的分配。
coordinator节点选择 = groupid的hashcode值%50( __consumer_offsets的分区数量)
例如: groupid的hashcode值 = 1,1% 50 = 1,那么__consumer_offsets 主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
(3)消费者组详细消费流程
fetch.min.bytes:每批次最小抓取大小,默认1字节;
fetch.max.wait.ms:一批数据最小值未达到的超时时间,默认为500ms;
fetch.max.bytes:每批次最大抓取大小,默认50m;
Max.poll.records:一次拉取数据返回消息的最大条数,默认500条;
sendFetches:发送消费请求;
FetchedRecords:从队列中抓取数据;
消费者重要参数
参数名称 描述
bootstrap.servers
向Kafka集群建立初始连接用到的host/port列表。
key.deserializer
指定接收消息的key和value的反序列化类型。一定要写全类名。
value.deserializer
指定接收消息的key和value的反序列化类型。一定要写全类名。
group.id
标记消费者所属的消费者组。
enable.auto.commit
默认值为true,消费者会自动周期性地向服务器提交偏移量。
auto.commit.interval.ms
如果设置了enable.auto.commit的值为true, 则该值定义了消费者偏移量向Kafka提交的频率,默认5s。
auto.offset.reset
当Kafka中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理?
earliest:自动重置偏移量到最早的偏移量。
latest:默认,自动重置偏移量为最新的偏移量。
none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。
offsets.topic.num.partitions
__consumer_offsets的分区数,默认是50个分区。
heartbeat.interval.ms
Kafka消费者和coordinator之间的心跳时间,默认3s。该条目的值必须小于session.timeout.ms,也不应该高于session.timeout.ms的 1/3。
session.timeout.ms
Kafka消费者和coordinator之间连接超时时间,默认45s。超过该值,该消费者被移除,消费者组执行再平衡。
max.poll.interval.ms
消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。
fetch.min.bytes
默认1个字节。消费者获取服务器端一批消息最小的字节数。
fetch.max.wait.ms
默认500ms。如果没有从服务器端获取到一批数据的最小字节数。该时间到,仍然会返回数据。
fetch.max.bytes
默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受message.max.bytes(broker config)or max.message.bytes (topic config影响。
max.poll.records
一次poll拉取数据返回消息的最大条数,默认是500条。
消费者API
独立消费者案例(订阅主题)
(1)需求:创建一个独立的消费者,消费first主题中的数据。
注意:在消费者API代码中必须配置消费者组id。命令行启动消费者不填写消费者组id会被自动填写随机的消费者组id。
(2)代码
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class ConsumerAPITopic
public static void main(String[] args)
//1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop01:9092,hadoop02:9092");
// 配置序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
//拉取数据打印
while (true)
//设置 1s 中消费一批数据
ConsumerRecords<String, String> polls = kafkaConsumer.poll(Duration.ofSeconds(1));
//打印消费到的数据
for (ConsumerRecord<String, String> poll:polls)
System.out.println(poll);
(3)测试
1)执行idea的程序
2)启动kafka的first生产者并输入数据
kafka_2.11-2.4.1]# bin/kafka-console-producer.sh
--broker-list hadoop01:9092 --topic first
3)查看idea控制台的数据
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 16, CreateTime = 1663480002009, serialized key size = -1, serialized value size = 5, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = hello)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 2, offset = 11, CreateTime = 1663480011502, serialized key size = -1, serialized value size = 5, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = kafka)
独立消费者案例(订阅分区)
(1)需求:创建一个独立消费者,消费first主题0号分区的数据
(2)代码
ConsumerAPIPartition
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class ConsumerAPIPartition
public static void main(String[] args)
// 创建kafka生产者的配置对象
Properties properties = new Properties();
// 给kafka配置对象添加配置信息
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop01:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
// 配置消费者组(必须),名字可以任意起
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
// 消费某个主题的某个分区数据
ArrayList<TopicPartition> topicPartitions = new ArrayList<>();
topicPartitions.add(new TopicPartition("first",0));
kafkaConsumer.assign(topicPartitions);
while (true)
ConsumerRecords<String, String> polls = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String,String> poll:polls)
System.out.println(poll);
CustomProducerCallBack
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducerCallBack
public static void main(String[] args) throws InterruptedException
/**
* 编写回调函数异步发送API代码
*/
//1.创建kafka生产者环境
Properties properties = new Properties();
//2.给kafka配置对象添加配置信息:bootstrap.server
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop01:9092,hadoop02:9092");
//key.value序列化:key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//3.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
//4.调用send方法,发送信息
for (int a = 0;a < 5; a++)
kafkaProducer.send(new ProducerRecord<>("first", "hello mykafka" + a), new Callback()
//在kafkaProducer接收到ack时调用,异步调用
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e)
if (e == null)
System.out.println("主题:"+ recordMetadata.topic() + "->"+"分区:"+recordMetadata.partition());
else
//出现异常打印
e.printStackTrace();
);
//延迟一会会看到数据发往不同的分区
Thread.sleep(2);
//5.关闭环境
kafkaProducer.close();
(3)测试
1)在idea执行ConsumerAPIPartition程序;
2)在idea执行CustomProducerCallBack程序;
3)观察控制台的信息
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 4, offset = 33, CreateTime = 1663497588537, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = hello mykafka0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 4, offset = 34, CreateTime = 1663497588573, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = hello mykafka1)
消费者组案例
(1)需求:测试同一个主题的分区数据,只能由一个消费者组中的一个消费者消费。
(2)代码
复制一份消费者的代码,在IDEA中同时启动,即可启动同一个消费者组中的两个消费者。
ConsumerAPITopic:消费者1
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class ConsumerAPITopic
public static void main(String[] args)
//1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop01:9092,hadoop02:9092");
// 配置序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
//拉取数据打印
while (true)
//设置 1s 中消费一批数据
ConsumerRecords<String, String> polls = kafkaConsumer.poll(Duration.ofSeconds(1));
//打印消费到的数据
for (ConsumerRecord<String, String> poll:polls)
System.out.println(poll);
ConsumerAPITopic2:消费者2
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class ConsumerAPITopic2
public static void main(String[] args)
//1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop01:9092,hadoop02:9092");
// 配置序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
//拉取数据打印
while (true)
//设置 1s 中消费一批数据
ConsumerRecords<String, String> polls = kafkaConsumer.poll(Duration.ofSeconds(1));
//打印消费到的数据
for (ConsumerRecord<String, String> poll:polls)
System.out.println(poll);
CustomProducerCallBack:生产者
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducerCallBack
public static void main(String[] args) throws InterruptedException
/**
* 编写回调函数异步发送API代码
*/
//1.创建kafka生产者环境
Properties properties = new Properties();
//2.给kafka配置对象添加配置信息:bootstrap.server
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop01:9092,hadoop02:9092");
//key.value序列化:key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//3.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
//4.调用send方法,发送信息
for (int a = 0;a < 5; a++)
kafkaProducer.send(new ProducerRecord<>("first", "kafka group" + a), new Callback()
//在kafkaProducer接收到ack时调用,异步调用
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e)
if (e == null)
System.out.println("主题:"+ recordMetadata.topic() + "->"+"分区:"+recordMetadata.partition());
else
//出现异常打印
e.printStackTrace();
);
//延迟一会会看到数据发往不同的分区
Thread.sleep(2);
//5.关闭环境
kafkaProducer.close();
(3)测试
1)启动执行消费者代码
2)启动执行生产者代码,在IDEA控制台即可看到两个消费者在消费不同分区的数据(如果只发生到一个分区,可以在发送时增加延迟代码 Thread.sleep(2);)
3)观察控制台信息
生产经验—分区的分配以及再平衡
一个consumer group中有多个consumer组成,一个topic有多个partition组成,现在的问题是到底由哪个consumer来消费哪个partition的数据。
Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。
可以通过配置参数partition.assignment.strategy修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时使用多个分区分配策略。
参数名称 描述
heartbeat.interval.ms
Kafka消费者和coordinator之间的心跳时间,默认是3s。该条目的值必须小于session.timeout.ms,也不应该高于session.timeout.ms的1/3。
session.timeout.ms
Kafka消费者和coordinator之间连接超时时间,默认45s。超过该值,该消费者被移除,消费者组执行再平衡。
max.poll.interval.ms
消费者处理消息的最大时长,默认是5分钟。超过该值该消费者被移除,消费者组执行再平衡。
partition.assignment.strategy
消费者分区分配策略,默认策略是Range+CooperativeSticky。Kafka可以同时使用多个分区分配策略。可以选择的策略包括:Range、RoundRobin、Sticky、CooperativeSticky。
Range以及再平衡
(1)Range分区策略原理
Range是对每个topic而言的。
首先对同一个topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
例:
假如现在有7个分区,3个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2。 7/3 = 2余1 ,除不尽,那么 消费者C0便会多消费1个分区。 若8/3=2余2,除不尽,那么C0和C1分别多消费一个。
通过partitions数/consumer数来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费1个分区。
注:如果只是针对1个topic而言,C0消费者多消费1个分区影响不是很大。但是如果有N多个topic,那么针对每个topic,消费者C0都将多消费1个分区,topic越多,C0消费的分区会比其他消费者明显多消费N个分区,容易产生数据倾斜。
(2)Range分区分配策略案例
锁销除锁粗化
锁销除
java中的锁销除是指JVM即时编译器在运行的时候,对一些代码要求同步、但是对被检测到不可能存在共享数据的竞争的锁进行消除。锁销除的主要的依据来源于逃逸机制分析的数据支持、如果判断到一段代码中、在堆上的所有的数据都不会逃逸出去被其它的线程访问到的时候,那么就可以把他们当作栈上的数据对待。栈是线程私有的,也就不会发生线程不安全的问题了。
来看:👇
这是看起来一段没有锁的代码

但是在JDK5之前字符串的加法操作会转换为StringBuilder对象连续的append()方法来操作、JDK5之后会转换为StringBuffer对象连续的append()方法来操作。StringBuilder和StringBuffer的append()方法区别😄:
来看源码:
StringBuilder调用的是父类的append方法:
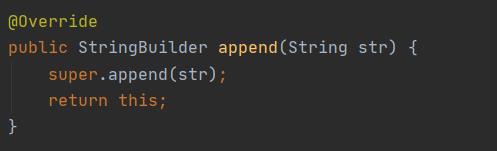
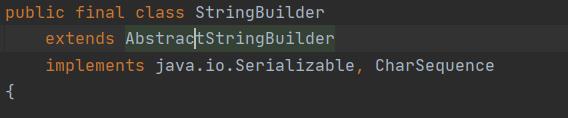
它的父类是AbstractStringBuilder
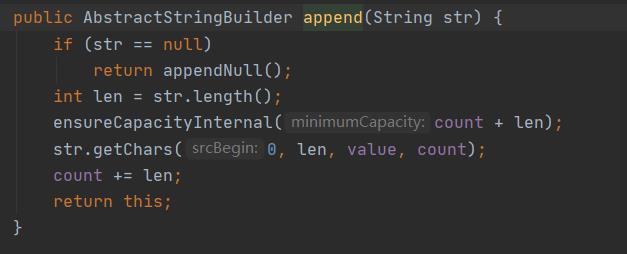
来看父类中的append()方法:
首先StringBuffer也是继承了AbstractStringBuilder类
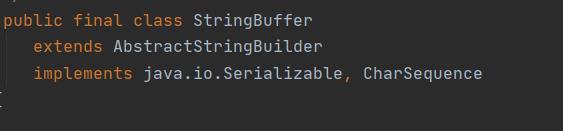
StringBuffer重写了父类AbstractStringBuilder的append()方法:👇
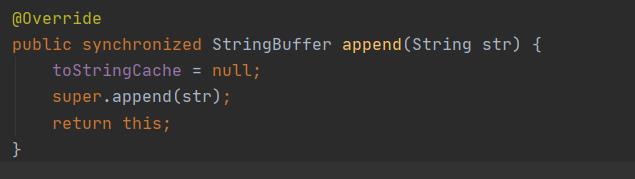
将append()方法变为同步的了。
上图的代码最后会转变为下面的操作:
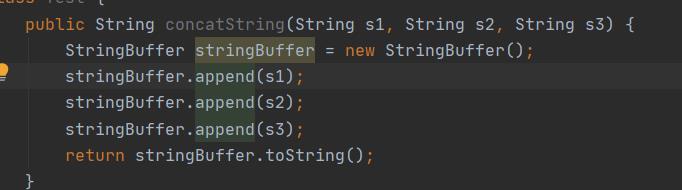
使用了synchronized关键来对方法的整体加锁。
在StringBuffer中都有一个同步块、锁的就是StringBuffer对象。虚拟机观察stringBuffer、在经过逃逸分析的时候发现它的动态作用域被限制在concatString()方法的内部。也就是说stringBuffer的所有的引用都不会逃到concatStrng()方法的外部、那也就是其它的线程无法访问到大、所以虽然这里有锁、但是可以被安全的消除掉。在解释执行的时候、这里任然会被加锁、但是经过服务器编译器的即时编译之后、这段代码就会忽略所有的同步的措施而直接执行。
锁粗化
写代码的时候、原则上会将锁的同步代码块的作用的范围限制的尽量的小、只有在共享数据的时候在实际的作用域中才进行同步、目的就是为了减少同步的操作的范围、使程序运行的效率变高。
在大多数的情况之下、这里的原则是正确的。但是如果一系列连续的操作都是对一个对象反复的加锁和解锁、比如加锁是在循环体之中的、那么就是没有线程的竞争、频繁的创建和销毁锁也会导致不必要的性能开销。
比如上面的方法、三个操作都是加锁的操作、那么我们也可以使用一把锁将三个append()方法加锁。
顺提 一下StringBuffer和StringBuilder的区别:
StringBuilder中的方法:
StringBuilder大多调用的是父类AbstractStringBuilder的方法
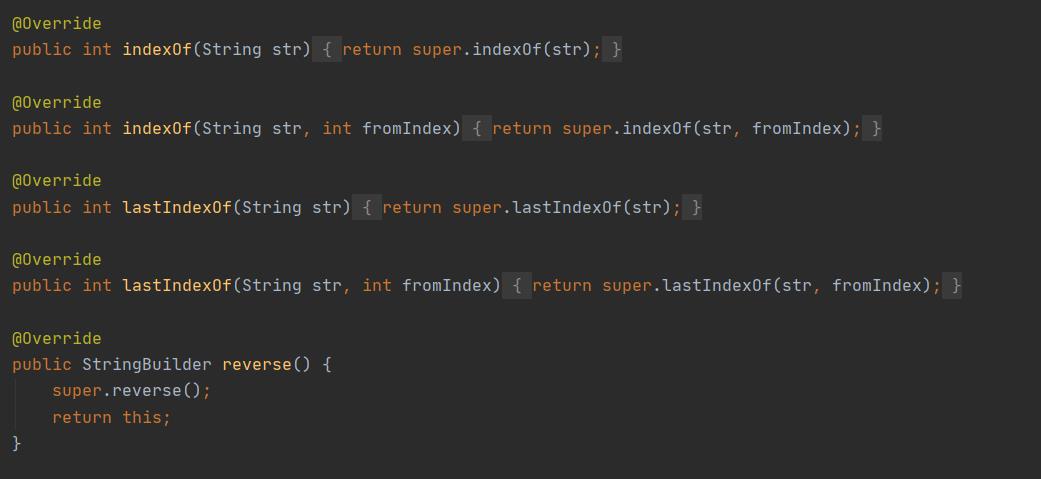
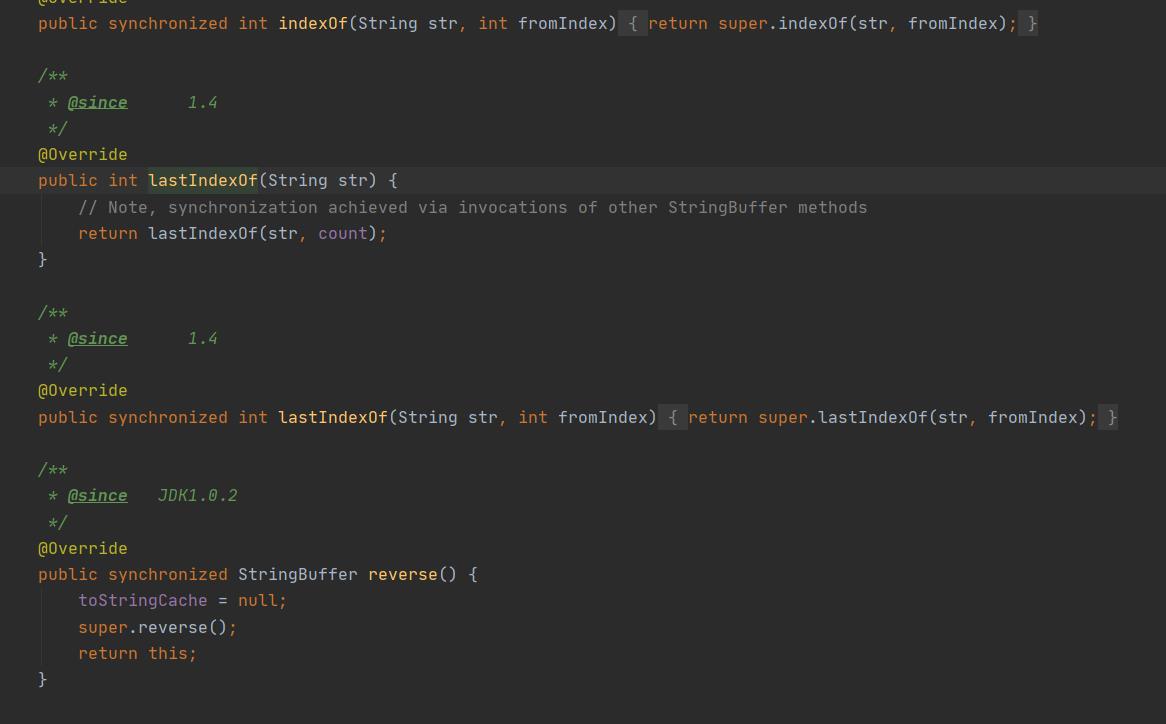
StringBuffer:
StringBuffer大多数的方法也是调用的是父类AbstractStringBuilder的方法、但是区别也是显而易见的、StringBuffer的调用父类方法的时候、大都被synchronized关键字修饰、也就是常说的StringBuffer是线程安全的。
以上是关于消费者遗除是的主要内容,如果未能解决你的问题,请参考以下文章