词向量原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词向量原理相关的知识,希望对你有一定的参考价值。
参考技术A了解词向量要从语言模型说起,语言模型其实就是计算任意一个句子的概率。
经典的语言模型是n-gram模型,该模型假设每个词的生成仅仅依赖前面n个词,所以从大规模语料中统计每个词的概率和基于前面n词的条件概率,就可以计算出一个句子的概率。对于没有出现的条件概率,则采用平滑方法来估计。该方法的假设太强,没有考虑更多的上下文。而且训练需要大量语料,一般的统计也只到trigram。
后来出现了神经网络语言模型,该模型训练出语言模型的同时可以输出词向量。
也就是说所有词向量模型的目标都是训练一个语言模型,最大化训练数据中每个句子的概率,词向量作为参数一起训练,当语言模型训练好的时候,词向量也就有了。
2003年bengio推出了《A Neural Probabilistic Language Model》,对每个词采用分布式表示,即词向量表示,用一个三层的神经网络训练出一个好的语言模型。
第一层为词向量层,每个词都查表替换为词向量作为输入,第二层是一个tanh层(隐藏层),与第一层相连,第三层是一个softmax输出层,与第一层和第二层都相连。
该网络估计的是一个ngram片段的概率,输入层是n-1个词的词向量拼接而成的向量,输出是|V|个词的概率,对应一个|V|维向量。
假设词向量为m维,隐藏层节点数为h,词表大小为|V|,则
训练目标就是最大化所有ngram片段(n个连续词)的似然性,可以加正则项。
词向量也是参数,采用随机梯度下降法训练,训练结束后,语言模型有了,词向量也有了。
更多词向量模型可参考: Licstar的 Deep Learning in NLP (一)词向量和语言模型
与Bengio的模型相比,Word2Vec去掉了最耗时的非线性隐藏层的计算,改为简单的求和隐层,并提出了两种模型:
一种是CBOW模型,通过前后n个词(上下文)来预测当前词的概率,隐藏层对上下文词的词向量求和,所以节点数和词向量维度相同。
一种是Skip-gram模型,通过词w预测上下文范围内每个词的概率,所以Skip-gram 中的每个词向量表征了上下文的分布。
每种模型又有两种选择:层次softmax,或者Negative Sampling。
层次Softmax结合了哈夫曼编码,每个词的编码对应从树根到这个词的路径,路径每个节点计算出的概率的乘积就是当前预测词的概率。
层次softmax的思想其实借鉴了Hinton提出的层次log-bilinear模型,N元层次log-bilinear模型通过上下文预测下一个词w概率的方法为: 词w对应编码中每一位的条件概率的乘积
Negative Sampling的思想就是随机找些负样本,通过计算对比损失来优化,理论上叫作噪声对比估计(Noise Contrastive Estimation),损失函数为:
公式的推导可参考:
其他参考:
word2vec的数学原理——词向量基础及huffuman树
一、旧版本的神经网络表示词向量
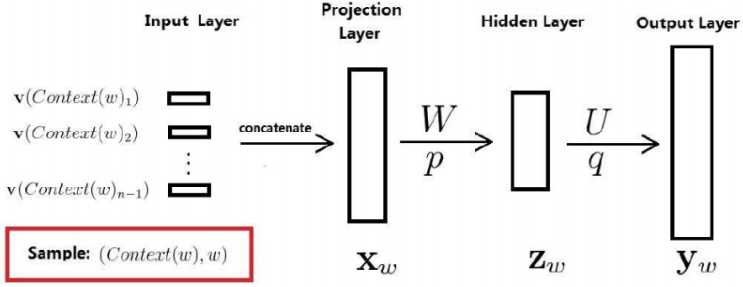
将每个词表示成$m$维的向量,用$v(w)$表示,整个网络分为4层,分别为输入层,投影层,隐藏层,输出层。
输入层:取一个大小为n的窗口表示输入,用1~(n-1)个词来预测第n个词的生成概率。
投影层:将每个词映射为m维向量,将这些词向量拼接为一个(n-1)m的长向量,作为投影层
隐藏层:隐藏层的节点根据需要可以进行调节
输出层:N维向量,表示预测为每个词的概率
前向传播的表达式为:
$z_{w}=tanh(Wx_{w}+p)$
$y_{w}=softmax(Uz_{w}+q)$
其中,输出表示由前面(n-1)各词,预测第n个词的概率,即$P(w|context(w))=y_{w}$
注意:这个网络的参数是由两部分组成的
1)词向量,每个词一开始的投影是随机的,最后由训练后确定。(这和普通的机器学习算法输入是确定的有很大区别)
2)神经网络的连接权重
二、huffman树及huffman编码
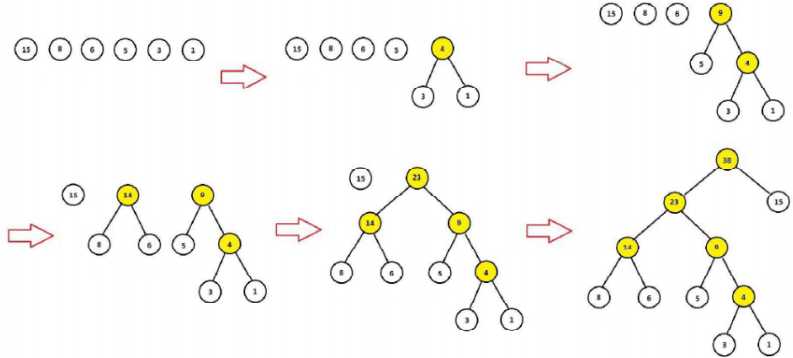
1、Huffman树的构造
根据词典每个词作为叶子节点,词的频次作为叶子节点的权重,向上构造huffman树,具体为:
1)将词典的N个词,看成N棵树的森林
2)将“根节点权值“最小的两棵树合并成一棵新树,原来的树视为新树的左右子树,新树的“根节点权值”为左右子树的“根节点权值”之和
3)重复2),直到森林中只剩下一棵树
整个Huffman树构建完成以后,叶节点的个数为N(词典大小),非叶节点的个数为N-1
以“我”,“喜欢”,“观看”,“巴西”,“足球”,“世界杯”为例,这组词的词频为:15,8,6,5,3,1
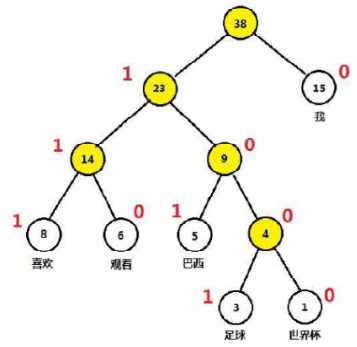
2、Huffman编码
对于一棵Huffman树,规定左子节点标记为1,右子节点标记为0,每个词的路径(根节点除外)对应的编码称为该词的Huffman编码,如:我——0,喜欢——111,观看——110,巴西——101,足球——1001,世界杯——1000
huffuman编码原先是用在数字通信领域,希望整段文本的编码长度越小越好,因此构建huffuman树,使得词频越多的字编码越短,词频越少的字编码越长。
以上是关于词向量原理的主要内容,如果未能解决你的问题,请参考以下文章