如何用Python开发一个简单的Webkit浏览器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Python开发一个简单的Webkit浏览器相关的知识,希望对你有一定的参考价值。
在这篇教程中,我们会用 Python 的 PyQt 框架编写一个简单的 web 浏览器。关于 PyQt ,你可能已经有所耳闻了,它是 Qt 框架下的一系列 Python 组件,而 Qt(发音类似“cute”)是用来开发 GUI 的 C++ 框架。严格来讲, Qt 也可用于开发不带图形界面的程序,但是开发用户界面应该是 Qt 框架最为广泛的应用了。Qt 的主要优势是可以开发跨平台的图形界面程序,基于 Qt 的应用能够借助于各平台的原生性在不同类的设备上运行,而无须修改任何代码库。
Qt 附带了 webkit 的接口,你可以直接使用 PyQt 来开发一个基于 webkit 的浏览器。
我们本次教程所开发的浏览器可以完成如下功能:
加载用户输入的url
显示在渲染页面过程中发起的所有请求
允许用户在页面中执行自定义的 javascript 脚本
牛刀小试
让我们从最简单的 PyQt 的 Webkit 用例开始吧:输入 url,打开窗口并在窗口中加载页面。
这个例子十分短小,连 import 语句和空行在内也只有 13 行代码。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
import sys
from PyQt4.QtWebKit import QWebView
from PyQt4.QtGui import QApplication
from PyQt4.QtCore import QUrl
app = QApplication(sys.argv)
browser = QWebView()
browser.load(QUrl(sys.argv[1]))
browser.show()
app.exec_()
当你通过命令行将 url 传给脚本时,程序会加载 url 并且在窗口中显示加载完成的页面。
现在,看似你已经有一个“命令行浏览器”啦!至少比 python 的 requests 模块强多了,甚至比 Lynx 还略高一筹,因为我们的浏览器还可以加载 JavaScript 脚本呢。但是目前为止还没有跟 Lynx 拉开差距,因为在启用浏览器的时候只能通过命令行传入 url。那么,必然需要通过某种方式把需要加载的 url 传入浏览器。没错,就是地址栏!
添加地址栏
其实地址栏的实现非常简单,我们只需要在窗口顶端加一个输入框就够了。用户在文本框中输入 url 之后,浏览器就会加载这个地址。下面,我们将用到 QLineEdit 控件来实现输入框。鉴于我们的浏览器现在有地址栏和浏览器显示框两部分,因此还要给我们的应用增加一个网格布局。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
import sys
from PyQt4.QtGui import QApplication
from PyQt4.QtCore import QUrl
from PyQt4.QtWebKit import QWebView
from PyQt4.QtGui import QGridLayout, QLineEdit, QWidget
class UrlInput(QLineEdit):
def __init__(self, browser):
super(UrlInput, self).__init__()
self.browser = browser
# add event listener on "enter" pressed
self.returnPressed.connect(self._return_pressed)
def _return_pressed(self):
url = QUrl(self.text())
# load url into browser frame
browser.load(url)
if __name__ == "__main__":
app = QApplication(sys.argv)
# create grid layout
grid = QGridLayout()
browser = QWebView()
url_input = UrlInput(browser)
# url_input at row 1 column 0 of our grid
grid.addWidget(url_input, 1, 0)
# browser frame at row 2 column 0 of our grid
grid.addWidget(browser, 2, 0)
# main app window
main_frame = QWidget()
main_frame.setLayout(grid)
main_frame.show()
# close app when user closes window
sys.exit(app.exec_())
到这里,我们已经有一个浏览器的雏形啦!看上去和当年的 Google Chrome 还有几分相像呢,毕竟两者采用了相同的渲染引擎。现在,你可以在输入框中输入 url ,程序便会将地址传入浏览器,接着渲染出所有的 html 页面和 JavaScript 脚本并展示出来。
添加开发工具
一个浏览器最有趣也最重要的部分是什么?当然是各种各样的开发工具了!一个没有开发者控制台的浏览器怎么能算是浏览器呢?所以,我们的 Python 浏览器当然也要有一些开发者工具才行。
现在,我们就来添加一些类似于 Chrome 的开发者工具中 “Network” 标签的功能吧!这个功能就是简单地追踪浏览器引擎在加载页面的时候所执行的所有请求。在浏览器主页面的下方,我们将通过一个表来显示这些请求。简单起见,我们只会记录登录的 url、返回的状态码和响应的内容类型。
首先我们要通过 QTableWidget 组件创建一个表格,表头包括需要存储的字段名称,表格可以根据每次新插入的记录来自动调整大小。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class RequestsTable(QTableWidget):
header = ["url", "status", "content-type"]
def __init__(self):
super(RequestsTable, self).__init__()
self.setColumnCount(3)
self.setHorizontalHeaderLabels(self.header)
header = self.horizontalHeader()
header.setStretchLastSection(True)
header.setResizeMode(QHeaderView.ResizeToContents)
def update(self, data):
last_row = self.rowCount()
next_row = last_row + 1
self.setRowCount(next_row)
for col, dat in enumerate(data, 0):
if not dat:
continue
self.setItem(last_row, col, QTableWidgetItem(dat))
想要追踪所有请求的话,我们还需要对 PyQt 的内部构件有更深入的了解。了解到,Qt 提供了一个 NetworkAccessManager类作为 API 接口,通过调用它可以监控应用加载页面时所执行的请求。我们需要自己编写一个继承自 NetworkAccessManager 的子类,添加必要的事件监听器,然后使用我们自己编写的 manager 来通知 webkit 视图执行相应的请求。
首先我们需要以 NetworkAccessManager 为基类创建我们自己的网络访问管理器。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Manager(QNetworkAccessManager):
def __init__(self, table):
QNetworkAccessManager.__init__(self)
# add event listener on "load finished" event
self.finished.connect(self._finished)
self.table = table
def _finished(self, reply):
"""Update table with headers, status code and url.
"""
headers = reply.rawHeaderPairs()
headers = str(k):str(v) for k,v in headers
content_type = headers.get("Content-Type")
url = reply.url().toString()
# getting status is bit of a pain
status = reply.attribute(QNetworkRequest.HttpStatusCodeAttribute)
status, ok = status.toInt()
self.table.update([url, str(status), content_type])
在这里需要提醒大家的是, Qt 的某些实现并不像想象中那么简单明了,比如说从响应中获取状态码就十分繁琐。首先,你得把请求对象的类属性作为参数传入 response 的方法 .attribute() 中,.attribute() 方法的返回值是 QVariant 类型而非 int 类型。接着,需要调用内置函数 .toInt() 将其转换成一个包含两个元素的元组,最终得到响应的状态码。
现在,我们终于有了一个记录请求的表和一个监控网络的 manager,接下来只要把他们聚拢起来就可以了。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
if __name__ == "__main__":
app = QApplication(sys.argv)
grid = QGridLayout()
browser = QWebView()
url_input = UrlInput(browser)
requests_table = RequestsTable()
manager = Manager(requests_table)
# to tell browser to use network access manager
# you need to create instance of QWebPage
page = QWebPage()
page.setNetworkAccessManager(manager)
browser.setPage(page)
grid.addWidget(url_input, 1, 0)
grid.addWidget(browser, 2, 0)
grid.addWidget(requests_table, 3, 0)
main_frame = QWidget()
main_frame.setLayout(grid)
main_frame.show()
sys.exit(app.exec_())
现在,运行浏览器程序,在地址栏键入 url,就可以看到在主页面下方的记录表中记录下的所有请求。
如果你有兴趣的话,还可以为浏览器添加很多新的功能:
通过content-type添加筛选功能
添加记录表的排序功能
添加计时器
高亮显示出错的请求(比如说把错误信息置为红色)
显示出更为具体的请求内容,比如说完整的头信息、响应内容、请求方法等。
增加一个重复发送请求并加载出来的选项。比如说用户可以点击在记录表中的请求来重试请求。
其实还有太多的功能可以继续完善和改进,你可以一一尝试一下,这会是一个非常有趣而且收获良多的学习过程。但是如果想把这些功能都说完,估计都能写一本书了。所以限于篇幅,本文就不一一介绍了,感兴趣的朋友可以参考其他书籍和网上教程。
增加解析自定义 JavaScript 脚本的功能
我们终于迎来最后一个功能了!就是解析在页面中包含的 JavaScript 脚本。
基于我们之前已经打下的基础,要完成这个功能非常简单。我们只需要在添加一个 QLineEdit 组件,把它和页面联系起来,然后调用 evaulateJavaScript 方法就可以了。
Python
1
2
3
4
5
6
7
8
9
class JavaScriptEvaluator(QLineEdit):
def __init__(self, page):
super(JavaScriptEvaluator, self).__init__()
self.page = page
self.returnPressed.connect(self._return_pressed)
def _return_pressed(self):
frame = self.page.currentFrame()
result = frame.evaluateJavaScript(self.text())
下面是这个功能的示例。看,我们的开发者工具已经整装待发了!
Python
1
2
3
4
5
6
7
8
9
10
11
if __name__ == "__main__":
# ...
# ...
page = QWebPage()
# ...
js_eval = JavaScriptEvaluator(page)
grid.addWidget(url_input, 1, 0)
grid.addWidget(browser, 2, 0)
grid.addWidget(requests_table, 3, 0)
grid.addWidget(js_eval, 4, 0)
现在唯一缺少的就是在页面中不能执行 Python 脚本。你可以开发自己的浏览器,提供对 JavaScript 和 Python 的支持,这样其他开发者就可以针对你的浏览器开发应用了。
后退、前进和其他页面操作
我们在前面已经使用了 QWebPage 对象来开发浏览器,当然作为一个合格的浏览器,我们也需要为终端用户提供一些重要功能。Qt 的网页对象支持很多不同操作,我们可以把它们全都添加到浏览器中。
现在我们可以先尝试着添加“后退”、“前进”和“刷新”这几个操作。你可以在界面上添加这些操作按钮,简单起见,这里只加一个文本框来执行这些动作。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class ActionInputBox(QLineEdit):
def __init__(self, page):
super(ActionInputBox, self).__init__()
self.page = page
self.returnPressed.connect(self._return_pressed)
def _return_pressed(self):
frame = self.page.currentFrame()
action_string = str(self.text()).lower()
if action_string == "b":
self.page.triggerAction(QWebPage.Back)
elif action_string == "f":
self.page.triggerAction(QWebPage.Forward)
elif action_string == "s":
self.page.triggerAction(QWebPage.Stop)
和之前一样,我们要创建一个 ActionInputBox 的实例,把参数传入页面对象并把输入框对象添加到页面中。
For reference here’s code for final result 示例代码看这里
[1]: Graphical User Interface,图形用户界面,又称图形用户接口,是指采用图形方式显示的计算机操作用户界面。
[2]: WebKit是一个开源的浏览器引擎,与之相对应的引擎有 Gecko(Mozilla Firefox 等使用)和 Trident(也称 MSHTML ,IE 使用)。
Python
import sys
from PyQt4.QtWebKit import QWebView
from PyQt4.QtGui import QApplication
from PyQt4.QtCore import QUrl
app = QApplication(sys.argv)
browser = QWebView()
browser.load(QUrl(sys.argv[1]))
browser.show()
app.exec_()
import sys
from PyQt4.QtWebKit import QWebView
from PyQt4.QtGui import QApplication
from PyQt4.QtCore import QUrl
app = QApplication(sys.argv)
browser = QWebView()
browser.load(QUrl(sys.argv[1]))
browser.show()
app.exec_()
当你通过命令行将 url 传给脚本时,程序会加载 url 并且在窗口中显示加载完成的页面。
现在,看似你已经有一个“命令行浏览器”啦!至少比 python 的 requests 模块强多了,甚至比 Lynx 还略高一筹,因为我们的浏览器还可以加载 JavaScript 脚本呢。但是目前为止还没有跟 Lynx 拉开差距,因为在启用浏览器的时候只能通过命令行传入 url。
如何用socket构建一个简单的Web Server
背景现代社会网络应用随处可见,不管我们是在浏览网页、发送电子邮件还是在线游戏都离不开网络应用程序,网络编程正在变得越来越重要
目标
了解web server的核心思想,然后自己构建一个tiny web server,它可以为我们提供简单的静态网页
最终效果
完整的事例代码可以查看这里
如何运行
python3 index.py注意
我们假设你已经学习过Python的系统IO、网络编程、Http协议,如果对此不熟悉,可以点击这里的Python教程进行学习,可以点击这里的Http协议进行学习,事例基于Python 3.7.2编写。
TinyWeb实现
首先我们给出TinyWebServer的主结构
import socket
# 创建socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定地址和端口
server.bind(("127.0.0.1", 3000))
server.listen(5)
while True:
# 等待客户端请求
client, addr = server.accept()
# 处理请求
process_request(client, addr)上面代码的核心逻辑是socket等待客户端请求,一旦接受到客户端请求就处理请求。
接下来我们主要工作就是实现process_request函数,我们都知道Http协议,Http请求主要包含4部分请求行、请求头、空行、请求体,于是我们可以抽象process_request的过程如下:
读取请求行--->读取请求头--->读取请求体--->处理请求--->关闭请求
具体的Python代码如下所示:
def process_request(client, addr):
try:
# 获取请求行
request_line = read_request_line(client)
# 获取请求头
request_headers = read_request_headers(client)
# 获取请求体
request_body = read_request_body(
client, request_headers[b"content-length"])
# 处理客户端请求
do_it(client, request_line, request_headers, request_body)
except BaseException as error:
# 错误处理
handle_error(client, error)
finally:
# 关闭客户端请求
client.close()为什么我们不用单独解析空行,因为空行是用来表示整个http请求头的结束,除此之外空行对我们来说没有什么作用,关于如何解析Http消息,首先我们先来看一下Http消息结构:
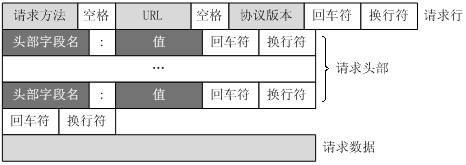
从上面的消息结构我们可以看出,要解析http消息,其中有一个关键的步骤是从socket中读取行,我们可以不断地从socket中读取直到遇到\r\n,这样我们就可以读取到完整的行
def read_line(socket):
recv_buffer = b‘‘
while True:
recv_buffer += recv(socket, 1)
if recv_buffer.endswith(b"\r\n"):
break
return recv_buffer上面的recv只是对socket.recv的一个包装,具体代码如下:
def recv(socket, count):
if count > 0:
recv_buffer = socket.recv(count)
if recv_buffer == b"":
raise TinyWebException("socket.rect调用失败!")
return recv_buffer
return b""在上面的封装中我们主要是处理了socket.recv返回错误和count小于0的异常情况,然后我们自己定义了一个TinyWebException用来表示我们的错误,TinyWebException的代码如下:
class TinyWebException(BaseException):
pass解析请求行:
请求行的解析从上面的结构中我们知道只要从请求数据中读取第一行,然后通过空格把他们分开就可以了,具体代码如下所示:
def read_request_line(socket):
"""
读取http请求行
"""
# 读取行并把\r\n替换成空字符,最后以空格分离
values = read_line(socket).replace(b"\r\n", b"").split(b" ")
return dict(
# 请求方法
b‘method‘: values[0],
# 请求路径
b‘path‘: values[1],
# 协议版本
b‘protocol‘: values[2]
)解析请求头:
请求头的解析要稍微复杂一点,它要不停得读取行,直到遇到单独的\r\n行结束,具体代码如下:
def read_request_headers(socket):
"""
读取http请求头
"""
headers = dict()
line = read_line(socket)
while line != b"\r\n":
keyValuePair = line.replace(b"\r\n", b"").split(b": ")
# 统一header中的可以为小写,方便后面使用
keyValuePair[0] = keyValuePair[0].decode(
encoding="utf-8").lower().encode("utf-8")
if keyValuePair[0] == b"content-length":
# 如果是cotent-length我们需要把结果转化为整数,方便后面读取body
headers[keyValuePair[0]] = bytesToInt(keyValuePair[1])
else:
headers[keyValuePair[0]] = keyValuePair[1]
line = read_line(socket)
# 如果heander中没有content-length,我们就手动把cotent-length设置为0
if not headers.__contains__(b"content-length"):
headers[b"content-length"] = 0
return headers解析请求体:
请求体的读取相对也简单,只要连续读取conetnt-length个bytes
def read_request_body(socket, content_length):
"""
读取http请求体
"""
return recv(socket, content_length)完成了Http数据解析以后我们需要实现核心的do_it,它主要是基于Http数据处理请求,我们在上面说过,tiny web server主要是实现了静态资源的读取,读取资源首先我们要定位资源,资源的定位主要是基于path的,在解析path的时候,我们用到了urllib.parse模块的urlparse功能,只要我们解析到了具体的资源,我们直接向浏览器输出响应就可以了。在输出具体的代码之前,我们需要简单说明一个Http消息响应的格式,HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文,下面给出一个简单的事例: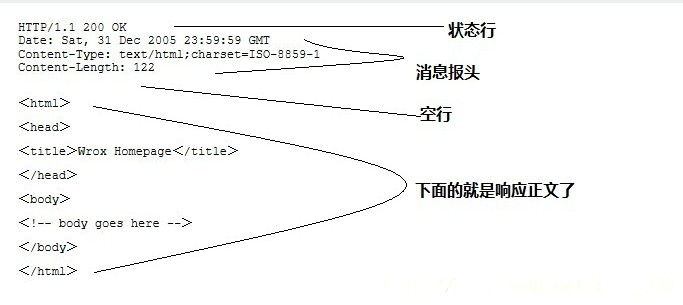
def do_it(socket, request_line, request_headers, request_body):
"""
处理http请求
"""
# 生成静态资源的目标地址,在这里我们所有的静态文件都统一放在static目录下面
parse_result = urlparse(request_line[b"path"])
current_dir = os.path.dirname(os.path.realpath(__file__))
file_path = os.path.join(current_dir, "static" +
parse_result.path.decode(encoding="utf-8"))
# 如果静态资源存在就向客户端提供静态文件
if os.path.exists(file_path):
serve_static(socket, file_path)
else:
# 静态文件不存在,向客户展示404页面
serve_static(socket, os.path.join(current_dir, "static/404.html"))do_it最核心的逻辑是serve_static,serve_static主要就是实现了读取静态文件并以Htt的响应格式返回给客户端,下面是serve_static的主要代码
def serve_static(socket, path):
# 检查是否有path读的权限和具体path对应的资源是否是文件
if os.access(path, os.R_OK) and os.path.isfile(path):
# 文件类型
content_type = static_type(path)
# 文件大小
content_length = os.stat(path).st_size
# 拼装Http响应
response_headers = b"HTTP/1.0 200 OK\r\n"
response_headers += b"Server: Tiny Web Server\r\n"
response_headers += b"Connection: close\r\n"
response_headers += b"Content-Type: " + content_type + b"\r\n"
response_headers += b"Content-Length: %d\r\n" % content_length
response_headers += b"\r\n"
# 发送http响应头
socket.send(response_headers)
# 以二进制的方式读取文件
with open(path, "rb") as f:
# 发送http消息体
socket.send(f.read())
else:
raise TinyWebException("没有访问权限")在serve_static中首先我们需要判断我们是否有文件的读全权,并且我们指定的资源是文件,而不是文件夹,如果不是合法文件我们直接提示没有访问权限,我们还需要直到文件的格式,因为客户端需要通过content-type来决定如何处理资源,然后我们需要文件大小,用来确定content-length,文件格式主要是通过后缀名简单判断,我们单独提供了static_type来生成content-type,文件的大小只要通过Python的os.stat获取就可以,最后我们只要把所有信息拼装成Http Response就可以了。
def static_type(path):
if path.endswith(".html"):
return b"text/html; charset=UTF-8"
elif path.endswith(".png"):
return b"image/png; charset=UTF-8"
elif path.endswith(".jpg"):
return b"image/jpg; charset=UTF-8"
elif path.endswith(".jpeg"):
return b"image/jpeg; charset=UTF-8"
elif path.endswith(".gif"):
return b"image/gif; charset=UTF-8"
elif path.endswith(".js"):
return b"application/javascript; charset=UTF-8"
elif path.endswith(".css"):
return b"text/css; charset=UTF-8"
else:
return b"text/plain; charset=UTF-8"完整的tiny web server 代码
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
import socket
from urllib.parse import urlparse
import os
class TinyWebException(BaseException):
pass
def recv(socket, count):
if count > 0:
recv_buffer = socket.recv(count)
if recv_buffer == b"":
raise TinyWebException("socket.rect调用失败!")
return recv_buffer
return b""
def read_line(socket):
recv_buffer = b‘‘
while True:
recv_buffer += recv(socket, 1)
if recv_buffer.endswith(b"\r\n"):
break
return recv_buffer
def read_request_line(socket):
"""
读取http请求行
"""
# 读取行并把\r\n替换成空字符,最后以空格分离
values = read_line(socket).replace(b"\r\n", b"").split(b" ")
return dict(
# 请求方法
b‘method‘: values[0],
# 请求路径
b‘path‘: values[1],
# 协议版本
b‘protocol‘: values[2]
)
def bytesToInt(bs):
"""
把bytes转化为int
"""
return int(bs.decode(encoding="utf-8"))
def read_request_headers(socket):
"""
读取http请求头
"""
headers = dict()
line = read_line(socket)
while line != b"\r\n":
keyValuePair = line.replace(b"\r\n", b"").split(b": ")
# 统一header中的可以为小写,方便后面使用
keyValuePair[0] = keyValuePair[0].decode(
encoding="utf-8").lower().encode("utf-8")
if keyValuePair[0] == b"content-length":
# 如果是cotent-length我们需要把结果转化为整数,方便后面读取body
headers[keyValuePair[0]] = bytesToInt(keyValuePair[1])
else:
headers[keyValuePair[0]] = keyValuePair[1]
line = read_line(socket)
# 如果heander中没有content-length,我们就手动把cotent-length设置为0
if not headers.__contains__(b"content-length"):
headers[b"content-length"] = 0
return headers
def read_request_body(socket, content_length):
"""
读取http请求体
"""
return recv(socket, content_length)
def send_response():
print("send response")
def static_type(path):
if path.endswith(".html"):
return b"text/html; charset=UTF-8"
elif path.endswith(".png"):
return b"image/png; charset=UTF-8"
elif path.endswith(".jpg"):
return b"image/jpg; charset=UTF-8"
elif path.endswith(".jpeg"):
return b"image/jpeg; charset=UTF-8"
elif path.endswith(".gif"):
return b"image/gif; charset=UTF-8"
elif path.endswith(".js"):
return b"application/javascript; charset=UTF-8"
elif path.endswith(".css"):
return b"text/css; charset=UTF-8"
else:
return b"text/plain; charset=UTF-8"
def serve_static(socket, path):
# 检查是否有path读的权限和具体path对应的资源是否是文件
if os.access(path, os.R_OK) and os.path.isfile(path):
# 文件类型
content_type = static_type(path)
# 文件大小
content_length = os.stat(path).st_size
# 拼装Http响应
response_headers = b"HTTP/1.0 200 OK\r\n"
response_headers += b"Server: Tiny Web Server\r\n"
response_headers += b"Connection: close\r\n"
response_headers += b"Content-Type: " + content_type + b"\r\n"
response_headers += b"Content-Length: %d\r\n" % content_length
response_headers += b"\r\n"
# 发送http响应头
socket.send(response_headers)
# 以二进制的方式读取文件
with open(path, "rb") as f:
# 发送http消息体
socket.send(f.read())
else:
raise TinyWebException("没有访问权限")
def do_it(socket, request_line, request_headers, request_body):
"""
处理http请求
"""
# 生成静态资源的目标地址,在这里我们所有的静态文件都统一放在static目录下面
parse_result = urlparse(request_line[b"path"])
current_dir = os.path.dirname(os.path.realpath(__file__))
file_path = os.path.join(current_dir, "static" +
parse_result.path.decode(encoding="utf-8"))
# 如果静态资源存在就向客户端提供静态文件
if os.path.exists(file_path):
serve_static(socket, file_path)
else:
# 静态文件不存在,向客户展示404页面
serve_static(socket, os.path.join(current_dir, "static/404.html"))
def handle_error(socket, error):
print(error)
error_message = str(error).encode("utf-8")
response = b"HTTP/1.0 500 Server Internal Error\r\n"
response += b"Server: Tiny Web Server\r\n"
response += b"Connection: close\r\n"
response += b"Content-Type: text/html; charset=UTF-8\r\n"
response += b"Content-Length: %d\r\n" % len(error_message)
response += b"\r\n"
response += error_message
socket.send(response)
def process_request(client, addr):
try:
# 获取请求行
request_line = read_request_line(client)
# 获取请求头
request_headers = read_request_headers(client)
# 获取请求体
request_body = read_request_body(
client, request_headers[b"content-length"])
# 处理客户端请求
do_it(client, request_line, request_headers, request_body)
except BaseException as error:
# 打印错误信息
handle_error(client, error)
finally:
# 关闭客户端请求
client.close()
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(("127.0.0.1", 3000))
server.listen(5)
print("启动tiny web server,port = 3000")
while True:
client, addr = server.accept()
print("请求地址:%s" % str(addr))
# 处理请求
process_request(client, addr)
最后想说的
上面的tiny web server只是实现了很简单的功能,在实际的应用中比这复杂得多,这里只是体现了web server的核心思想
以上是关于如何用Python开发一个简单的Webkit浏览器的主要内容,如果未能解决你的问题,请参考以下文章