gfs和hdfs有啥区别?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了gfs和hdfs有啥区别?相关的知识,希望对你有一定的参考价值。
参考技术A HDFS 最早是根据 GFS(Google File System)的论文概念模型来设计实现的,但是也有一些区别。 参考技术B GFS:Google File SystemHDFS:Hadoop Distribute File System
首先,有一点要确认的是,作为GFS的一个最重要的实现,HDFS设计目标和GFS是高度一致的。在架构、块大小、元数据等的实现上,HDFS与GFS大致一致。但是,在某些地方,HDFS与GFS又有些不同。如:
1、 快照(Snapshot):
GFS中的快照功能是非常强大的,可以非常快的对文件或者目录进行拷贝,并且不影响当前操作(读/写/复制)。GFS中生成快照的方式叫copy-on-write。也就是说,文件的备份在某些时候只是将快照文件指向原chunk,增加对chunk的引用计数而已,等到chunk上进行了写操作时,Chunk Server才会拷贝chunk块,后续的修改操作落到新生成的chunk上。
而HDFS暂时并不支持快照功能,而是运用最基础的复制来完成。想象一下,当HBase上的数据在进行重新划分时(过程类似于hash平衡),HDFS需要对其中的所有数据(P/T级的)进行复制迁移,而GFS只需要快照,多不方便!
2、 记录追加操作(append):
在数据一致性方面,GFS在理论上相对HDFS更加完善。
a) GFS提供了一个相对宽松的一致性模型。GFS同时支持写和记录追加操作。写操作使得我们可以随机写文件。记录追加操作使得并行操作更加安全可靠。
b) HDFS对于写操作的数据流和GFS的功能一样。但是,HDFS并不支持记录追加和并行写操作。NameNode用INodeFileUnderConstruction属性标记正在进行操作的文件块,而不关注是读还是写。DataNode甚至看不到租约!一个文件一旦创建、写入、关闭之后就不需要修改了。这样的简单模型适合于Map/Reduce编程。
3、 垃圾回收(GC):
a) GFS垃圾回收采用惰性回收策略,即master并不会立即回收程序所删除的文件资源。 GFS选择以一种特定的形式标记删除文件(通常是将文件名改为一个包含时间信息的隐藏名字),这样的文件不再被普通用户所访问。Master会定期对文件的命名空间进行检查,并删除一段时间前的隐藏文件(默认3天)。
b) HDFS并没有采用这样的垃圾回收机制,而是采取了一种更加简单但是更容易实现的直接删除方式。
c) 应该说延迟回收和直接删除各有优势。延迟回收为那些“不小心“的删除操作留了后路。同时,回收资源的具体操作时在Master结点空闲时候完成,对GFS的性能有很好的提高。但是延迟回收会占用很大的存储空间,假如某些可恶的用户无聊了一直创建删除文件怎么办?
试分析下这种不同。有人说,GFS在功能上非常完善,非常强大,而HDFS在策略上较之简单些,主要是为了有利于实现。但实际上,GFS作为存储平台早已经被广泛的部署在Google内部,存储Google服务产生或者要处理的数据,同时用于大规模数据集的研究与开发工作。因此GFS并不仅仅是理论上的研究,而是具体实现。作为GFS的后辈与开源实现,HDFS在技术上应该是更加成熟的,不可能为了“偷懒”而简化功能。因此,简化说应该是不成立的。
个人认为,GFS与HDFS的不同是由于“专”与“通”的区别。众所周知,Hadoop是一个开源软件/框架,在设计之初就考虑到了用户(面向世界上的所有个人、企业)在需求上的差异,比如数据密集型(如淘宝的数据存储)、计算密集型(百度的PR算法)、混合型等等。而GFS在设计之初就对目标比较明确,都是Google的嘛,因此GFS可以对其主要功能进行性能上的优化。
说到这里,突然想起了某件事。曾经某个公司的Boss吹牛B:“我不关心J2EE,实际上在大公司里面用J2EE的很少,都有自己的一些框架。测试过了,我们在用自己开发的框架时候性能就是以前用J2EE的时候的7倍左右。”唬的我一跳一跳的,好牛啊!!后来想了一下,其实不是这个公司技术比SUN要强,而是J2EE是一个开源框架,其应用范围非常广,因此不能做到面面俱到。而他们公司自己开发的框架肯定是对其主要业务逻辑方面做了专门的优化和改进,甚至删除了或者弱化了许多对他们来说作用不大的模块。
貌似这个和GFS与HDFS的关系好像!!
从设计到实现:GFS和HDFS在复制上的设计及异同比较 | 分布式文件系统读书笔记
前面的理论部分介绍了何为复制、为何复制,几种基本复制方式。理论完了,这篇具体看看gfs、hdfs如何进行副本复制(主要关注数据写入过程)。
文 | 何文鑫
GFS的数据复制
先看gfs原文[1]
In Figure 2, we illustrate this process by following the control flow of a write through these numbered steps.
The client asks the master which chunkserver holds the current lease for the chunk and the locations of the other replicas. ...
The master replies with the identity of the primary and the locations of the other (secondary) replicas. ...
The client pushes the data to all the replicas. ...
Once all the replicas have acknowledged receiving the data, the client sends a write request to the primary. ... It applies the mutation to its own local state in serial number order.
The primary forwards the write request to all secondary replicas. Each secondary replica applies mutations in the same serial number order assigned by the primary.
The secondaries all reply to the primary indicating that they have completed the operation.
The primary replies to the client. Any errors encountered at any of the replicas are reported to the client. ... The client request is considered to have failed, ...
可以看出,gfs使用同步方式进行数据复制。
主要体现在:
The client pushes the data to all the replicas. ...
The secondaries all reply to the primary indicating that they have completed the operation.
整个数据写入的大概步骤:
首先,client从master上获取到需要保存replica的chunkserver列表,并且指定其中某个chunkserver为primary,其余chunkserver为secondaries(控制流中primary和secondaries具有不同的功能,见第三步)。
然后,client将数据以线性(linearly)、管道(pipelined)的方式推送到这些chunkserver上。chunkserver收到数据后暂存在LRU缓存中,等待控制流指令说明以何顺序落盘。所谓管道方式,即client只向一个chunkserver推送数据,chunkserver收到数据后,再将其推送到下一个chunkserver。
最后,所有数据在chunkserver上就位,client向primary发出写入指令,primary以自己的数据落盘顺序指导secondaries以一致的方式落盘。
值得注意的是,gfs清晰地将数据流(步骤3)与控制流(其余步骤)分离。
数据流与控制流分离,可以充分利用网络拓扑,最大化网络带宽,不必强行保持数据流与控制流的流向一致。
在控制流中,primay是关键节点,client与所有chunkserver的控制消息全部经由primary。因为控制消息长度短,primary的关键节点问题不大。
如果数据流也像控制流一样全部通过primary,则为了性能考虑,primary必须是到其他chunkserver距离总和最小的一个,这样要求master必须具备选择合适primary的能力。
从论文中描述的设计推断,master似乎不具备节点距离感知能力(比如,类似hdfs的机架感知能力)。因为,chunkserver的pipeline结构是由各个chunkserver自行计算得出,并没有由master统一计算得出。
这种分布到各个节点上的算法也许能更好地计算出最优的pipeline距离,因为每个节点最了解自己与其他节点的距离。
相关论文原文:
Suppose the client is pushing data to chunkservers S1 through S4. It sends the data to the closest chunkserver, say S1. S1 forwards it to the closest chunkserver S2 through S4 closest to S1, say S2. Similarly, S2 forwards it to S3 or S4, whichever is closer to S2, and so on. Our network topology is simple enough that “distances” can be accurately estimated from IP addresses.
因为无法看到gfs的具体实现,所以实现细节是否如此不得而知。
HDFS的数据复制
hdfs与gfs采用相同的复制方式:同步复制。
原文[2]:
When there is a need for a new block, the NameNode allocates a block with a unique block ID and determines a list of DataNodes to host replicas of the block. The DataNodes form a pipeline, the order of which minimizes the total network distance from the client to the last DataNode. Bytes are pushed to the pipeline as a sequence of packets. The bytes that an application writes first buffer at the client side. After a packet buffer is filled (typically 64 KB), the data are pushed to the pipeline.
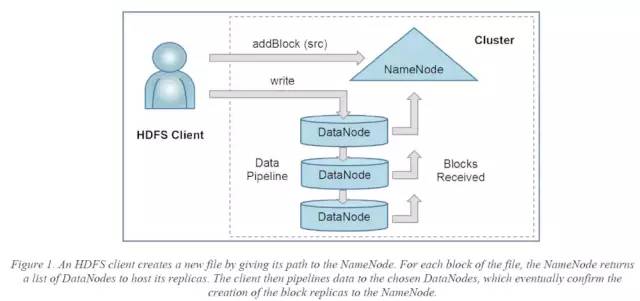
具体细节略有不同,hdfs不再将控制流与数据流分离,而是将数据传输以及变更顺序(mutation order)完全由client确定的pipeline决定[3]。
hdfs pipeline细节:
client通过与namenode通信,完全确定数据在datanode中的传输顺序
client发起pipeline的创建消息(t0~t1)
pipeline建立成功后,开始线性传输数据(t1~t2),同时数据也按照传输顺序(packet的序号)落盘
传输结束,关闭pipeline(t2~t3)
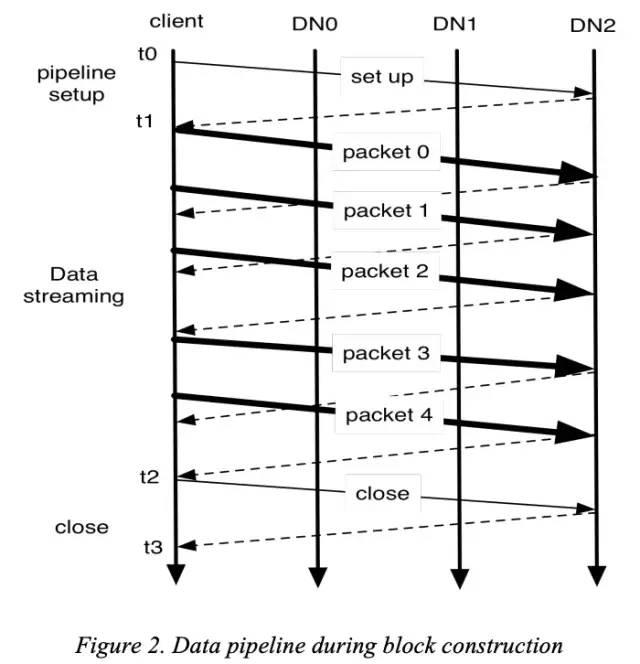
GFS与HDFS pipeline区别的思考
可以看出,hdfs的pipeline比gfs简化很多。gfs需要一个数据流和2*n+2个控制消息才能完成一个chunk的写入。而hdfs的pipeline,只需要一个数据流和少数几个控制消息就可以完成block的写入。
个人认为,hdfs的pipeline能够如此简化,主要归功于namenode能够通过机架感知信息在单个节点上计算出全局最佳的pipeline顺序。这使得client传输数据前,pipeline中的datanode顺序就已经确定,client可以很轻松的确定primary,即pipeline的第一个datanode。如此一来,控制流和数据流全部经由primary,就可以达到控制流与数据流的完美结合。整个流程中只有第一条和最后一条是纯粹的pipeline创建/关闭控制消息,中间消息全是数据消息,但同时又隐含控制功能:接收之后立即落盘。
虽然,hdfs的pipeline实现简单,但某些场景下表现不一定有gfs出色。比如,在机架信息不够准确、全面的情况下,namenode给出的pipeline顺序是否足够高效?
另外,gfs的pipeline可以支持多client同时append,顺序依然由primary决定。但hdfs的append操作如何实现,现有的pipeline机制知否支持,暂时还未知,待后续了解。
gfs和hdfs的设计已经通过字面意思理解完了,但如何与实现对应会在下篇文章中体现。
引用:
[1] The Google File System:
https://ai.google/research/pubs/pub51
[2] The Hadoop Distributed File System:
http://storageconference.us/2010/Papers/MSST/Shvachko.pdf
[3] Gfs vs hdfs - SlideShare:
https://www.slideshare.net/YuvalCarmel/gfs-vs-hdfs
(to be continued...)
「从设计到实现」系列文章:
长按二维码关注
以上是关于gfs和hdfs有啥区别?的主要内容,如果未能解决你的问题,请参考以下文章
使用 HDFS RAMDisk 和 Alluxio 有啥区别?