大数据学习难吗?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习难吗?相关的知识,希望对你有一定的参考价值。
参考技术A 大数据学习有一定的难度,建议找一家专业的培训机构进行学习,推荐选择【达内教育】,该机构培养的学员专业技能强,职业素养好,在用人单位中拥有良好口碑。【大数据学习】内容如下:
1、Scala:Scala是一门多范式的编程语言,大数据开发重要框架Spark是采用Scala语言设计,大数据开发需掌握Scala编程基础知识。
2、Spark:Spark是专为大规模数据处理而设计的快速通用的计算引擎,其提供了一个全面、统一的框架用于管理各种不同性质的数据集和数据源的大数据处理的需求。
3、Azkaban:Azkaban是一个批量工作流任务调度器,可以利用Azkaban来完成大数据的任务调度,大数据开发需掌握Azkaban的相关配置及语法规则。感兴趣的话点击此处,免费学习一下
想了解更多有关大数据的相关信息,推荐咨询【达内教育】。该机构致力于面向IT互联网行业,培养软件开发工程师、测试工程师、UI设计师、网络营销工程师、会计等职场人才,拥有行业内完善的教研团队,强大的师资力量,确保学员利益,全方位保障学员学习;更是与多家企业签订人才培养协议,全面助力学员更好就业。达内IT培训机构,试听名额限时抢购。官网客服
 千锋互联IT培训
千锋互联IT培训2016-12-07·TA获得超过568个赞知道答主
 大数据在Java技术之上,学习的专业内容:
大数据在Java技术之上,学习的专业内容:Java语言基础:
Java开发介绍、熟悉Eclipse开发工具、Java语言基础、Java流程控制、Java字符串、Java数组与类和对象、数字处理类与核心技术、I/O与反射,多线程、Swing程序与集合类;
html、CSS与javascript:
PC端网站布局、HTML5+CSS3基础、WebAPP页面布局、原生javascript交互功能开发、Ajax异步交互、jQuery应用;
JavaWeb和数据库:
数据库、javaWeb开发核心、JavaWeb开发内幕;
Linux基础:
Linux安装与配置、系统管理与目录管理、用户与用户组管理、Shell编程、服务器配置、Vi编辑器与Emacs编辑器;
Hadoop生态体系:
Hadoop起源与安装、MapReduce快速入门、Hadoop分布式文件系统、Hadoop文件I/O详解、MapReduce工作原理、MapReduce编程开发、Hive数据仓库工具、开源数据库HBase、Sqoop与Oozie;
Spark生态体系:
Spark简介、Spark部署和运行、Spark程序开发、Spark编程模型、作业执行解析、Spark SQL与DataFrame、深入Spark Streaming、Spark MLlib与机器学习、GraphX与SparkR、spark项目实战、scala编程、Python编程;
Storm实时开发:
storm简介与基本知识、拓扑详解与组件详解、Hadoop分布式系统、spout详解与bolt详解、zookeeper详解、storm安装与集群搭建、storm-starter详解、开源数据库HBase、trident详解;
项目案例:
模拟双11购物平台、前端工程化与模块化应用; 参考技术B 相对其他的专业来说大数据并不简单,如果有Java的基础就不错的,学习起来就轻松点,希望你早日学有所成。 参考技术C 一、大数据现状分析
1.大数据发展趋势
2019年-2021年,将成为未来20年间大数据及人工智能最佳的产业资本并购整合窗口期,就像2003年-2006年互联网产业整合的窗口期一样。
大数据与人工智能相互依托,在政策层面已经上升为国家战略,而且迅速进入全面启动实施阶段;技术层面,大数据技术已经基本成熟,并且推动人工智能技术以惊人的速度进步;产业层面,智能安防、自动驾驶、医疗影像等都在加速落地。
2.人才市场需求大
据美国劳工局预测,2022年美国市场将需要约85万大数据方面的专业技术人员;而国内数据统计《大数据人才报告》显示,预测未来3到5年人才缺口将达到150万之多。
3.职位薪酬水平普遍较高
据统计,在美国大数据分析师平均每年薪酬在17.5万美元左右;而国内一线互联网公司,大数据分析师的薪酬水平普遍比同一级别的其他职位高20-30%,这也成为国内转岗人员往大数据转型的很重要的理由之一。
4.高校加大对大数据相关专业的设立
目前,全世界有近170所大学开设了大数据相关专业。近些年,国内教育部也积极采取措施,加强对大数据人才的培养,开设新专业如“数据科学与大数据技术”等。大军已经进入,全民开始行动了。2019年国内各大高校都将会开设大数据、人工智能专业。所以对于想加入大数据行业而言,我建议还是尽量早点学习相关知识,进入这个行业。
二、大数据相关岗位有哪些,发展趋势是什么?
1.大数据平台研发路线
职责:主要负责大数据技术的产品化,包括开源技术框架的研究、封装和开发
入门:系统性了解大数据技术体系(spark、hadoop、hbase等技术),通读一遍各技术框架的技术文档,知道每项技术能够解决什么问题,其实现原理,优缺点等;能够调用各技术框架API进行功能封装
进阶:能够优化开源框架性能及完善开源技术、作为开源社区的commiter
发展:数据平台研发架构师、数据平台产品经理
2.大数据开发路线
职责:也叫ETL工程师,主要负责使用大数据技术采集、处理、分析数据;
入门:同数据平台研发工程师,并熟练使用SQL、存储过程;
进阶:技术选型、技术架构设计、数据架构设计、平台性能调优
发展:数据架构师、大数据DBA
3.大数据算法路线
职责:俗称调参工程师,主要负责使用机器学习算法建模,处理业务需求,基于算法引擎封装算法工具。
入门:python语言,sklearn、tensorflow等算法引擎,熟悉决策树、SVM、朴素贝叶斯、神经网络等各种算法原理和适用场景;
进阶:业务建模、调参
发展:数据科学家
4.大数据可视化路线
职责:主要负责数据可视化应用开发
入门:各种数据可视化图表适用场景、echarts框架、vue、BI工具
进阶:数据应用可视化UIUE设计、大屏展现设计
发展:数据艺术家
业务类
1.大数据分析路线
岗位:主要负责结合业务问题,使用大数据分析、制作数据分析报告、规划数据应用
入门:熟悉各种分析图表、数据分析工具、具备数据分析报告撰写能力等
进阶:熟悉各种算法概念及使用场景、具备敏锐的业务思维、管理思维和应用规划能力
发展:数据咨询师、数据产品经理 参考技术D 大数据学习只能说不轻松,Java语言是大数据学习的基础,你有Java的基础,那么你学习起来就会很轻松。
正则表达式很难吗?其实也就那样!
 / 写在前面的话 /
/ 写在前面的话 /
Hello,元宵节过了,这个年也算是过完了,接下来就得看我们2019年的奋斗了,2019年JAP君会一直陪着大家一起学习!今天我们来学习一下号称最难学的正则表达式,正则表达式在我们写爬虫的时候确实是一个很好的帮手,因为有一些网站的数据可能并不是那么的规整或者数据太多,我们只需要部分数据的时候,此时我们就可以通过一些表达式来进行提取,正则表达式就是其中一种进行数据筛选的表达式。
/ 正则表达式之“原子” /
常见的原子类型有哪些?
1.普通字符作原子
2.非打印字符作原子
3.通用字符作为原子
4.原子表
1.普通字符作原子:
普通字符是编写正则表达式时最常见的原子了,包括所有的大写和小写字母字符、所有数字等。例如,a—z、A—Z、0—9。
说明:search函数是re模块里面的,第一个参数就是原子,第二个参数是需要解析的字符串。
s = "JAVAandPython"
# 普通字符作为原子
pattern = "and"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(4, 7), match='and'>说明:re.research返回的是一个match对象
2.非打印字符作为原子:
非打印字符,是一些在字符串中的格式控制符号,例如空格、回车及制表符号等。例如下表所示列出了正则表达式中常用的非打印字符及其含义。
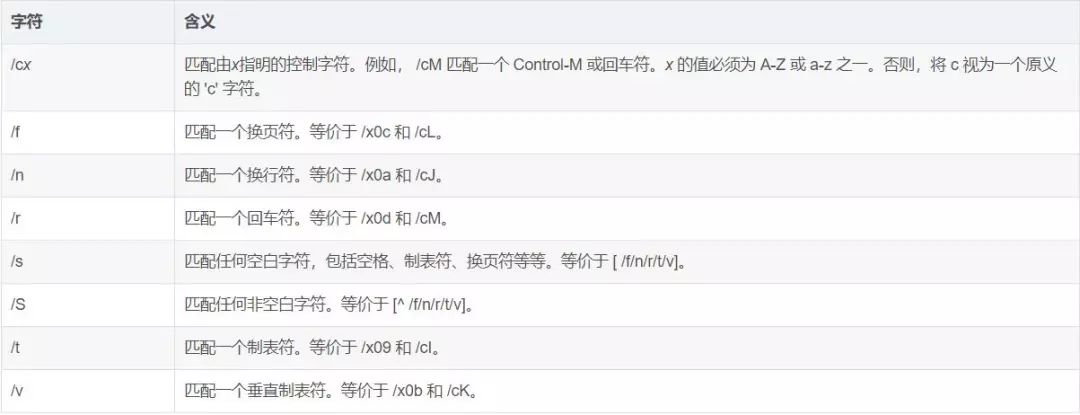
# 非打印字符作为原子
s = '''JAVAand
Python
'''
pattern = "\n"
m = re.search(pattern, s)
print(m)说明:这里我们使用了三引号来进行换行书写,s中是存在一个\n的
输出结果:
<_sre.SRE_Match object; span=(7, 8), match='\n'>3.通用字符作为原子
上面我们说的普通字符和非打印字符都是一个原子匹配一个字符,而通用字符是匹配一类字符,例如我们匹配数字时,不是匹配一个而是匹配这一类。
下面我给大家列举出一些:
\w:包含字母,数字,下划线
\W:除了字母,数字,下划线之外的
\d:十进制的数字
\D:除十进制的数字
\s:空白字符
\S:除空白字符
# 通用字符作为原子
s = 'JAVAand666python'
pattern = "\d\d\d\w"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(7, 11), match='666p'>4.原子表:
使用原子表“[]”就可以定义一组彼此地位平等的原子,且从原子表中仅选择一个原子进行匹配。
# 原子表
s = 'JAVAand666python'
pattern = "and[1234567]"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(4, 8), match='and6'>其实质就是从[]中选取符合原字符串的元素来进行匹配。
/ 正则表达式之“元字符”/
what is 元字符?所谓的元字符就是正则表达式中一些含有特殊意义的字符,如下表:

是不是看了之后还是有点懵逼?接下来,我给大家用代码一一实现一下
1. “ . ” 除了换行符外的任意一个字符
# 元字符 . 除了换行外任意一个字符
s = 'JAVAand666python'
pattern = "JAVA."
m = re.search(pattern, s)
print(m)
pattern = "JAVA..."
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 5), match='JAVAa'>
<_sre.SRE_Match object; span=(0, 7), match='JAVAand'>2. ^ 匹配输入字符串的开始位置
s = 'JAVAand666python'
pattern = "^JAVA."
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 5), match='JAVAa'>3. $ 输入字符串的结束位置
s = 'JAVAand666python'
pattern = ".python$"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(9, 16), match='6python'>4. * 匹配前子表达式的任意次
+ 匹配前子表达式的1次或者多次
? 匹配前子表达式的0次或者1次
s = 'JAVAand666python'
pattern = "JAVA.*"
m = re.search(pattern, s)
print(m)
s = 'JAVAand666python'
pattern = "JAVA.+"
m = re.search(pattern, s)
print(m)
s = 'JAVAand666python'
pattern = "JAVA.?"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 16), match='JAVAand666python'>
<_sre.SRE_Match object; span=(0, 16), match='JAVAand666python'>
<_sre.SRE_Match object; span=(0, 5), match='JAVAa'>5.{n} 匹配前子表达式恰好出现n次
{n,} 匹配前子表达式至少出现n次
{n,m} 匹配前子表达式至少出现n次,至多出现m次
s = 'JAVAanddddddd666python'
pattern = "JAVAand{3}"
m = re.search(pattern, s)
print(m)
s = 'JAVAanddddddd666python'
pattern = "JAVAand{3,}"
m = re.search(pattern, s)
print(m)
s = 'JAVAanddddddd666python'
pattern = "JAVAand{3,5}"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 9), match='JAVAanddd'>
<_sre.SRE_Match object; span=(0, 13), match='JAVAanddddddd'>
<_sre.SRE_Match object; span=(0, 11), match='JAVAanddddd'>OK,上面几个是比较常见的元字符。
/ 正则表达式之“模式修正符” /
虽然都说正则很难,其实基础上也不是特别难,只是大部分的东西需要死记硬背,接下来我们来扯一下模式修正符,这个非常简单,就几个简单的字母标点,但是也是需要我们记住的。
首先还是跟大家讲下模式修正符是个啥,它就是通过一些特定的符号去改正正则表达式的含义,从而达到一些特定的效果而且我没进行模式修正是不要去改变正则表达式的。
下表就是一些模式修正符:
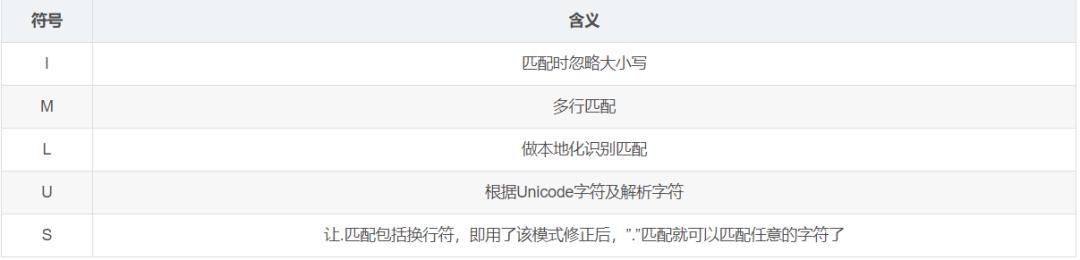
这里面比较重要的就是 I M S ,下面我就简单给大家用代码展示一个:
import re
s = "JAVAandPython666666"
pattern = 'java'
# 这里的第三个参数就是调用了我们的模式修正符,其他的也是一样的使用
m = re.search(pattern, s, re.I)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 4), match='JAVA'>从上面的代码和输出结果可以看出我们通过re.I 忽略掉了大小写。
再来看一个:
s = '''123java
asdasd
'''
pattern = '123.+'
# 这里的第三个参数就是调用了我们的模式修正符,其他的也是一样的使用
m = re.search(pattern, s, re.S)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 15), match='123java\nasdasd\n'>从结果中,我们可以看到它把\n也打印出来了。
/ 贪婪模式和懒惰模式 /
其实从字面意思上就可以看出,“贪婪模式”就是尽可能多的匹配,“懒惰模式”就是尽可能少的匹配。可能大家还是不知道这是个啥,还是直接上代码吧。
我们首先看一下贪婪模式:
s = '123JAVAandpypyPython'
pattern = '123.*py'
m = re.search(pattern, s, re.I)
print(m)我们来看看输出结果:
<_sre.SRE_Match object; span=(0, 16), match='123JAVAandpypyPy'>我们从代码和输出结果分析,可以看到它直到最后一个py才停止
我们再来看一下懒惰模式:
s = '123JAVAandpypyPython'
pattern = '123.*?py'
m = re.search(pattern, s, re.I)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 12), match='123JAVAandpy'>可以看到它匹配到第一个py时就停止了
总结:其实大家都可以发现,懒惰模式和贪婪模式就是一个问号的差别,贪婪模式是“.*”,懒惰模式是“.*?”。贪婪模式就是会一直“吃”到底,懒惰模式就是“吃”到第一个就不吃了,按照这样分析,可以发现贪婪模式所得到的结果是比较模糊的而懒惰模式得到的结果更加的精确。
/ 正则表达式的函数 /
接下来我们来看一下正则中的函数,这个是十分重要的。我就直接上代码。
import re
# 以下正则分成了两个小组,以小括号为单位
s = r'([a-z]+) ([a-z]+) ([a-z]+) ([a-z]+)'
# s.I表示忽略大小写
pattern = re.compile(s, re.I)
# match -从头开始匹配,但是search可以从任意处匹配
m = pattern.match("Hello World Kuls yes qweqwe")
# group(0)表示返回匹配成功的整个子串
s = m.group(0)
print(s)
# span(0)返回的是匹配成功的整个子串的跨度
a = m.span(0)
print(a)
# group(1)表示第一个匹配成功的子串
s = m.group(1)
print(s)
# span(1)表示第一个匹配成功的子串跨度
a = m.span(1)
print(a)
# groups()等价于group(1),group(2)
s = m.groups()
print(s)其实我在代码里面给大家讲解了每一个函数的作用,但是我还是把它扯出来吧,防止大家没看到。
match -从头开始匹配,但是search可以从任意处匹配
group(0)表示返回匹配成功的整个子串
span(0)返回的是匹配成功的整个子串的跨度
group(1)表示第一个匹配成功的子串
span(1)表示第一个匹配成功的子串跨度
groups()等价于group(1),group(2)
整个输出的结果也给大家看看:
Hello World Kuls yes
(0, 20)
Hello
(0, 5)
('Hello', 'World', 'Kuls', 'yes')另外还有两个比较重要的函数findall和finditer,两者相比,findall是最常用的。
import re
s = r'\d+'
# 全局匹配
pattern = re.compile(s)
m = pattern.findall("i am 18 years old and 185 high")
print(m)
# finditer
m = pattern.finditer("i am 18 years old and 185 high")
for i in m:
print(i.group())输出结果:
['18', '185']
18
185可以看到findall返回的是一个list列表
/ 一些常用的正则实例 /
这里给大家准备了一些经常用的正则实例,大家可以收藏收藏。
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
身份证号(15位、18位数字):^\d{15}|\d{18}$
中文字符的正则表达式:[\u4e00-\u9fa5]
• end •
关注我,你能变得更牛逼!
以上是关于大数据学习难吗?的主要内容,如果未能解决你的问题,请参考以下文章