让业务数据流动起来~
Posted Mr-Bruce
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让业务数据流动起来~相关的知识,希望对你有一定的参考价值。
前言
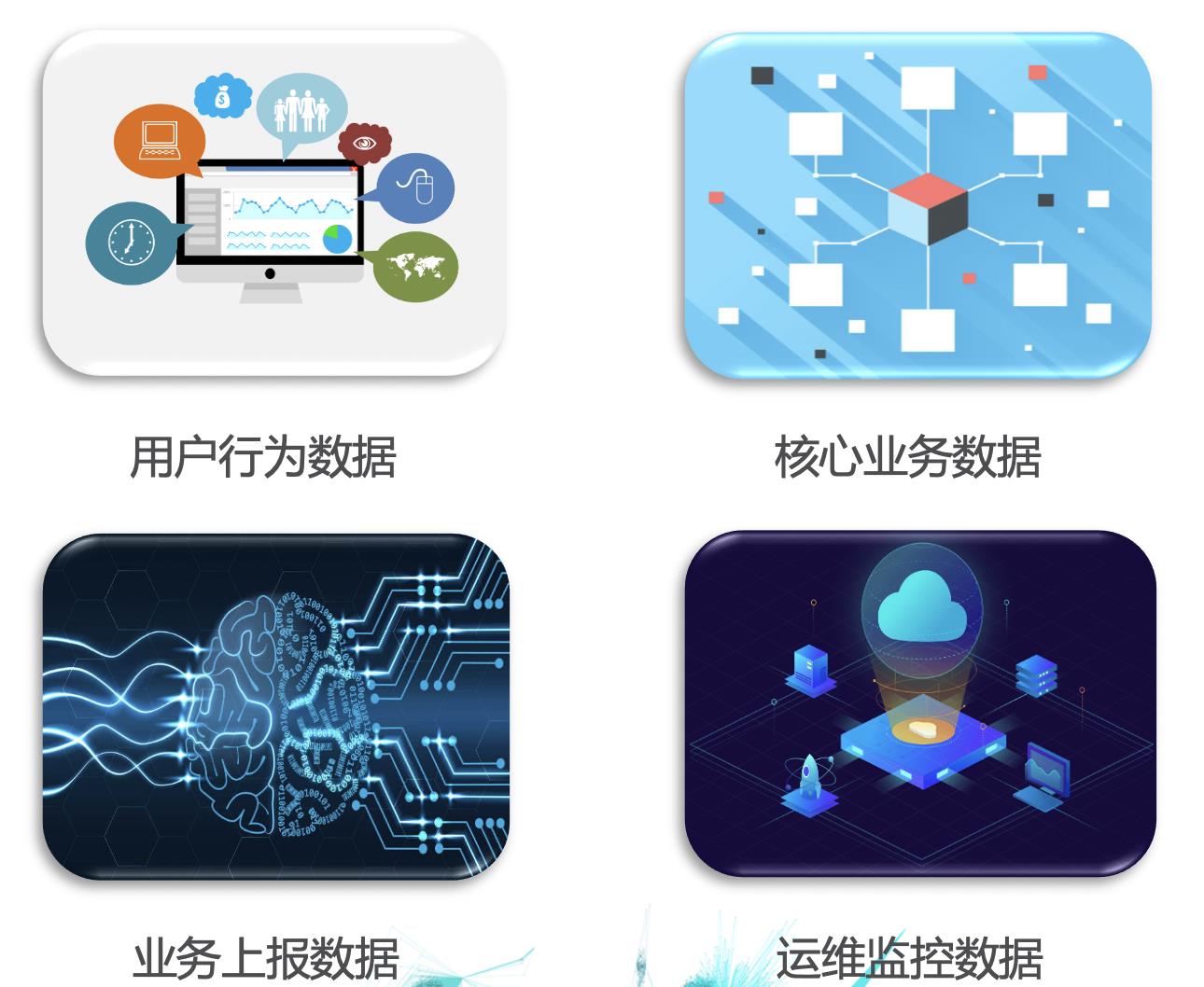
对于一个产品,甚至一个企业而言,基础的数据通常有四部分:用户行为数据、核心业务数据、业务上报数据和运维监控数据。
用户行为数据,主要是用户在前端(APP端、Web网页)的浏览与操作行为数据,用于追踪分析用户的使用方式,从而有针对性的优化产品、挖掘新需求。在某些场景下,后端的nginx日志也会被用来做这方面的分析,其包含了各个API的调用情况。核心业务数据,顾名思义,就是与业务本身息息相关的数据,通常以三范式的设计方式存储在关系型数据库中。比如电商系统的用户表、商品表、订单表等,工业网络安全系统中的公司表、设备表、策略表等。业务上报数据,是指由业务前端采集后主动上报到后端服务中的数据。比如建筑工地的塔式起重机系统,会实时上报各个传感器采集到的数据;网络安全UTM设备,会实时上报网络扫描的信息。运维监控数据,用于观察服务状态、触发相关告警、触发相关扩展策略等,从而确保整个服务的健康有效运作。这块数据包括两部分:来自基础设施的数据,比如机器的CPU使用率、每秒请求数、请求的响应时间等等;应用服务主动吐出来的数据,比如当前周期处理了多少数据、处理完一批数据花费了多少时间、还有多少报表在排队等等。
前三种数据都是与业务有着强相关性的,大多数企业都会基于这些基础数据做进一步的转换、处理,构建相应的数据仓库,为运营分析、数据挖掘、下一级业务系统等提供数据支撑。本文主要聊一聊与核心业务数据相关的事情,以mysql存储为例。
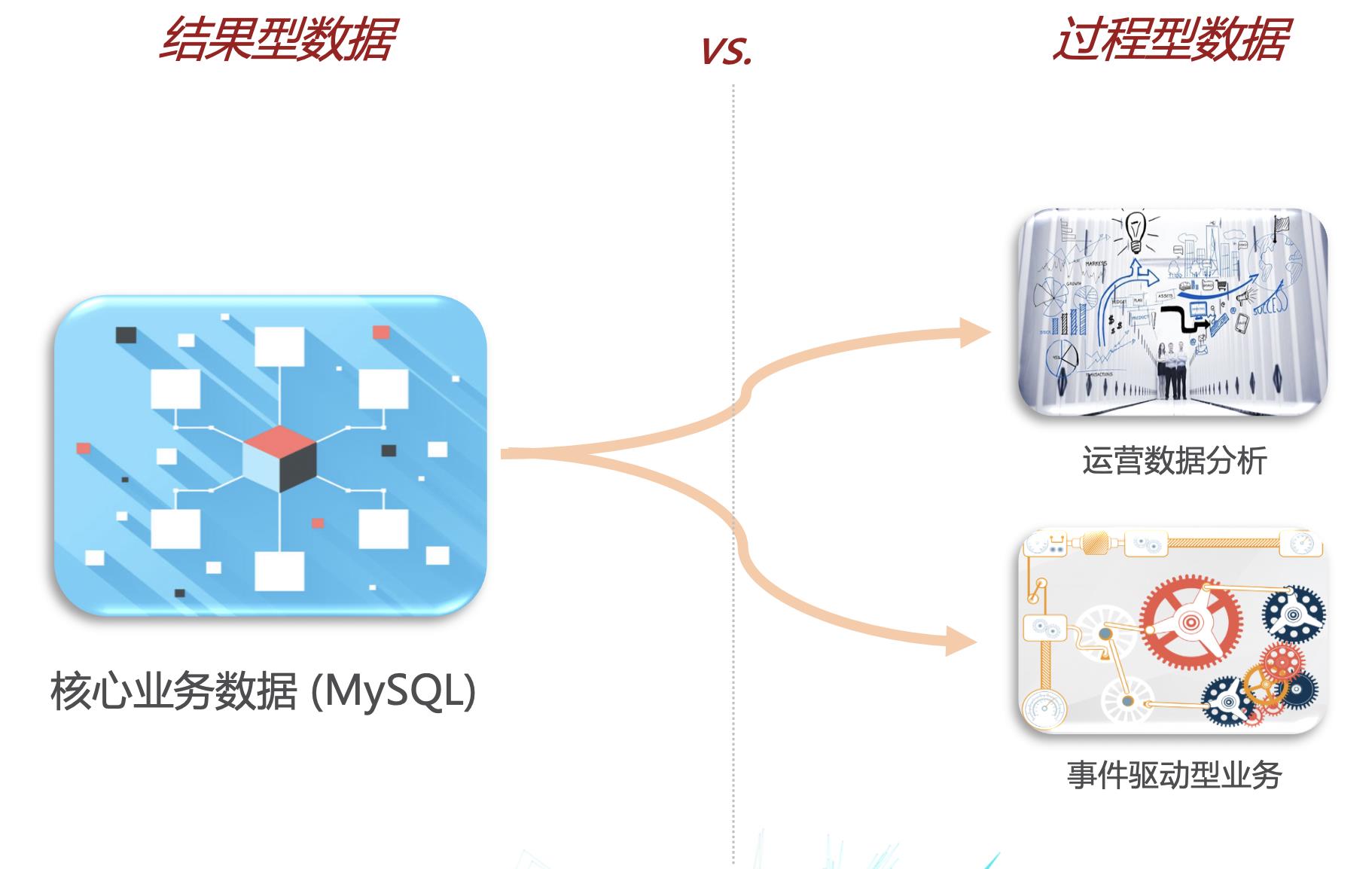
核心业务数据,除了支撑核心业务体系,通常还会衍生出两种使用方式:一种是运营数据分析,比如分析昨天新增了多少用户,来自哪些渠道;另一种是事件驱动型业务,比如用户下单成功后,需要根据这个事件触发相关的积分变化、定期提醒等业务。在这里面,核心业务数据是一种静态的结果型数据,而衍生出来的使用方式需要的是过程型数据。举例来说,假设在用户表中有一个nick_name字段,用户A在最近一周修改了五次昵称,那么,当前在MySQL中存储的nick_name的值就是最后一次修改的昵称,而现在我想分析一下过去一周有多少人修改了三次以上昵称,能做到吗?显然,仅仅依靠当前MySQL中存储的结果型数据是没法做的,因为我们缺少历史的过程型数据。
那么,该如何获取到过程型数据?传统的做法有两种:
- 定期扫描数据库,获取瞬时的状态信息并写入到时序型存储中。该方法需要提前根据相关需求准备脚本,灵活性较差,并且随着采集脚本越来越多,会对业务数据库造成较大压力。
- 数据双写,即在业务逻辑中,增加写入过程型数据到额外的时序型存储中。该方法对业务逻辑有倾入性,并且容易出现数据不一致的情况。
本文将探讨如何优雅的获取到过程型数据,即让业务数据流动起来。

MySQL Binary Log原理
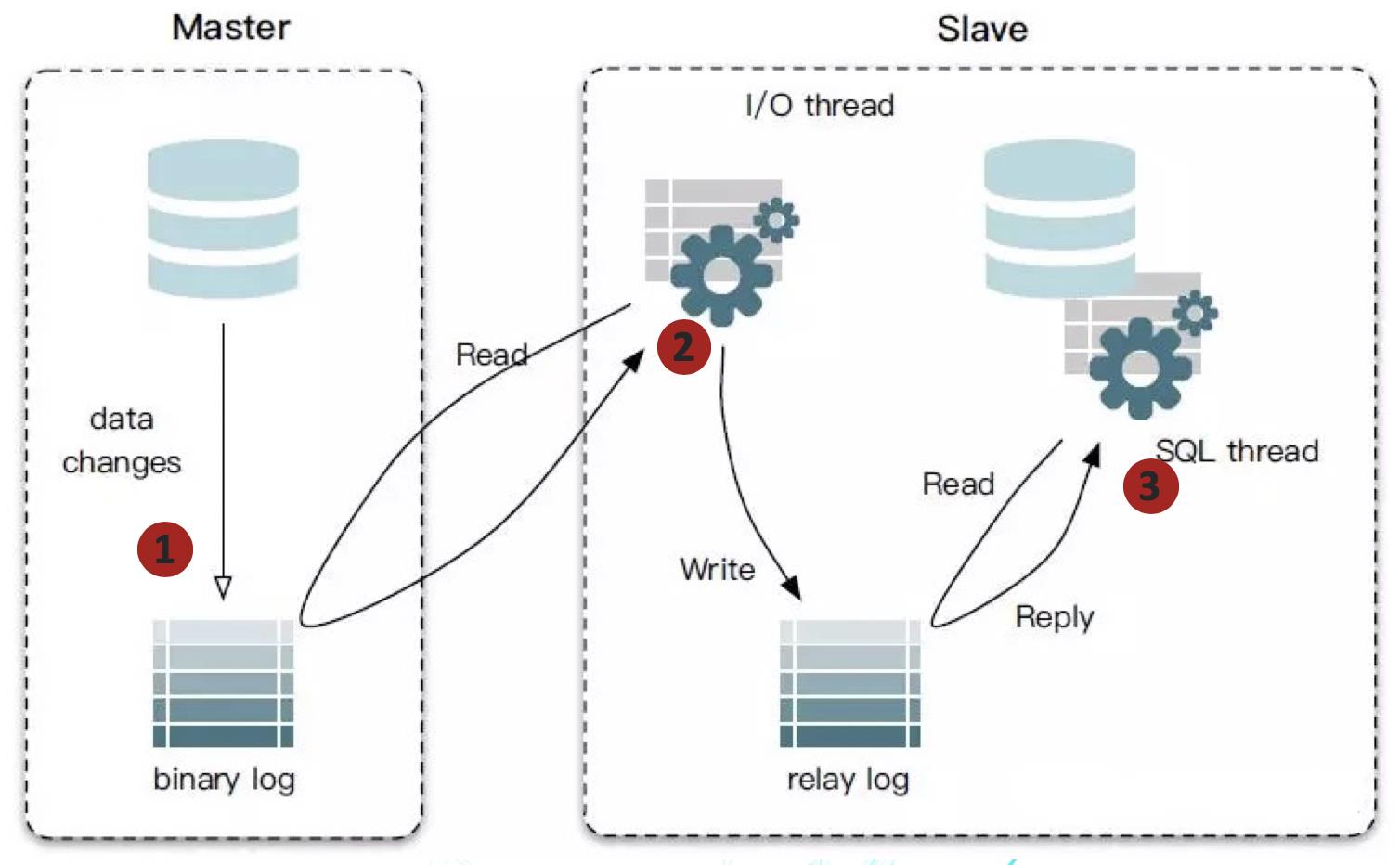
让我们从MySQL的Binary Log开始说起。MySQL 5.0以后,引入Binary Log(二进制日志),并通过此机制支持主从复制。Binary Log中存储的内容称为事件,每一个数据库更新操作(Insert、Update、Delete,不包括Select)都对应一个事件。主从复制,是指将一个MySQL服务器(Master) 的数据复制到一个或多个其他MySQL服务器(Slave)中,从而实现灾难恢复、水平扩展等功能。主从复制的流程如下图所示,主要包括三个步骤:
- Master在每次准备提交事务完成数据更新前,将更改记录到Binary Log中。
- Slave启动一个I/O线程来读取Master上Binary Log中的事件,并记录到Slave自己的Relay Log中。
- Slave启动一个SQL线程,负责从Relay Log中读取事件并执行,从而实现Slave中数据的更新。
在这里,Binary Log机制提供了一种通用的复制MySQL中存储数据的方法,而Slave只是一个MySQL自己实现的消费Binary Log的消费者。如果我们能自己实现一个类似Slave的程序,模拟Slave从Binary Log中拉取事件并解析,便可以拿到业务数据变化的过程型数据了。 这是一种优雅的、没有任何倾入性的解决方案。
Canal
对于这样的思路,已经有很多开源组件了,比如阿里巴巴的Canal,LinkedIn的Databus等等。本文主要以Canal来进行阐述。
如我们所需,Canal的主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费。基本工作原理为:
- Canal 模拟 MySQL Slave 的交互协议,伪装自己为MySQL Slave,向MySQL Master发送dump协议。
- MySQL Master收到dump请求,开始推送Binary Log给Slave(即Canal)。
- Canal解析Binary Log对象(原始为byte流)。

这里我们以一个简单的实验来说明Canal获取到的数据是什么样的。如下图所示,先对相应的RDS开启BinLog,创建Canal用户并赋予权限;然后以Docker方式运行Canal Server,开始同步BinLog;最后运行一个Python Client,从Canal Server中获取数据,并打印出来。我们先后做了三种DB操作:插入一条数据(Insert)、对其做修改(Update)、删除数据(Delete),每个操作之后,都会在Client端看到一条事件数据,里面包含了对应的事件类型、变化的具体数据等。

基于此,我们便可以近实时的获取到业务数据的变化,即过程型数据。通常情况下,我们会在Canal后面接一个Kafka,用于数据缓冲,而消费者可以根据自身需要从里面消费自己感兴趣的DB的相关事件。

结束语
本文探讨了通过Canal来获取核心业务数据对应的过程型数据,这是一种比较优雅、没有倾入性的通用的解决方案,读者可以根据自身业务需求做相应的使用。其实,这只是一种方式而已,核心的目的在于以优雅、通用的方式尽可能将所有有价值的数据保留下来。
(全文完,本文地址:https://bruce.blog.csdn.net/article/details/107295148 )
版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!
Bruce
2020/07/12 晚上
以上是关于让业务数据流动起来~的主要内容,如果未能解决你的问题,请参考以下文章