python 遍历文件夹PDF并转换成图片?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 遍历文件夹PDF并转换成图片?相关的知识,希望对你有一定的参考价值。
# -*- coding: utf-8 -*-
import sys, fitz
import os
import datetime
import re
def get_file_list(dir, file_type_list=['pdf','txt', 'csv', 'xlsx', 'xls'], file_list=[]):
'''获取指定文件夹下指定类型文件路径
:param dir: 文件夹路径
:param file_type_list: 文件类型
:param file_list: 文件列表 '''
for root, _, files in os.walk(dir):
for file in files:
file_type = file[file.rfind('.') + 1:]
if file_type in file_type_list:
file_list.append(os.path.join(root, file))
return file_list
def get_file_name(path_string):
"""获取文件名称,不含后缀"""
pattern = re.compile(r'([^<>/\\\|:""\*\?]+)\.\w+$')
data = pattern.findall(path_string)
if data:
return data[0]
def pyMuPDF_fitz(file_dir_path, out_file_path,file_type_list=['pdf','txt', 'csv', 'xlsx', 'xls']):
startTime_pdf2img = datetime.datetime.now()#开始时间
if not os.path.exists(out_file_path):#判断输出文件夹是否存在
os.makedirs(out_file_path) # 若不存在就创建
print("imagePath="+out_file_path)
file_paths = get_file_list(file_dir_path, file_type_list)#获取文件列表
n=0
t=0
for file in file_paths:
n=n+1
pdfDoc = fitz.open(file)
print("convert File="+file)
m=0
for pg in range(pdfDoc.pageCount):
page = pdfDoc[pg]
rotate = int(0)
# 每个尺寸的缩放系数为1.3,这将为我们生成分辨率提高2.6的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=72
zoom_x =2# 1.33333333 #(1.33333333-->1056x816) (2-->1584x1224)
zoom_y =2# 1.33333333
mat = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate)
pix = page.getPixmap(matrix=mat, alpha=False)
pix.writePNG(out_file_path+'/'+get_file_name(file)+'_images_%s.png' % pg)#将图片写入指定的文件夹内
m=m+1
t=t+1
print("convert File="+file,m,'pages finished.')
endTime_pdf2img = datetime.datetime.now()#结束时间
print('pdf2img时间=',(endTime_pdf2img - startTime_pdf2img).seconds,'秒, 共',n,'个文件已转换完成',t,'图片。')
if __name__ == "__main__":
pdfPath = './path'#相对路径
imagePath = './path/image'
pyMuPDF_fitz(pdfPath,imagePath, ['pdf'])
以上是完整代码,供需要的码迷使用
python实现网页/HTML截图并转PDF
通过Python,Node等服务端程序对现有网站或者HTML文件在不打开浏览器窗口的情况下进行截图,可以很方便的实现某些需求。如
- 实现办公自动化,将数据制作成<tr><td>表格或者图表后截图保存为PDF或图片,发送到通讯软件中
- GEO程序的开发,可以把地图和上面的自定义标记截图下来,以图片形式嵌入到自己应用中,这样就不需要集成地图SDK了
- 网站的定期自动化快照,可以保留网站变化历史
- 增强对浏览器和移动端的支持,对于无法渲染HTML5的浏览器,可以直接以图片代替
等等需求还有很多。下面介绍集中常用的方法。
方案一:Python+wkhtmltopdf
这个是百度出来最常见的方案,通过下载wkhtmltopdf/wkhtmltoimg工具,然后在python中进行跨进程调用,实现截图和保存为PDF,首先我们需要先上其官网下载Driver文件,其实就是一个Headless无窗口的虚拟浏览器,其内核为QtWebKit,类似早期苹果手机的Sarfari,对HTML5的支持较差
其官网为:https://wkhtmltopdf.org/downloads.html 支持Linux和Windows服务器,并且支持多种CPU的架构
1、保存为图片
import imgkit
import pdfkit
if __name__ == '__main__':
path_wkimg = r'C:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltoimage.exe' # 工具路径,需要替换为服务器的真实路径
cfg = imgkit.config(wkhtmltoimage=path_wkimg)
options =
'javascript-delay': '2000',
'height': '1500',
'width': '2000'
# 1、将html文件转为图片
imgkit.from_file(r'F:/map.html', 'map.jpg', config=cfg, options=options)
# 2、从url获取html,再转为图片
imgkit.from_url('https://html5test.com/', 'h5.jpg', config=cfg, options=options)
# 3、将字符串转为图片
imgkit.from_string('<h1>Hello!</h1>', 'hello.jpg', config=cfg)javascript-delay是等待js执行的时间,而不是等HTML都加载完直接截图,根据实际页面渲染时间来定
height和width是浏览器窗口的大小,可以超过显示器的实际大小(服务器上没有浏览器也无所谓),所以如果要截取整个页面,需要把height设置到和预估的网页高度一样。
如果不设置height,可以自动截取到页面底端,但是往往测算的会有问题,远远超出实际的大小,后文会有详细的测试
2、保存为PDF
import pdfkit
if __name__ == '__main__':
cfg = imgkit.config(wkhtmltoimage=path_wkimg)
options_pdf =
'javascript-delay': '15000',
'margin-bottom': '20mm',
'footer-line': None
path_wkpdf = r'C:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe' # 替换为服务器的真实路径
config = pdfkit.configuration(wkhtmltopdf=path_wkpdf)
url = 'https://html5test.com'
pdfkit.from_url(url, 'h5.pdf', configuration=config, options=options_pdf)
pdfkit.from_file('C:/echats.html', options=options_pdf,configuration=config,output_path='echarts.pdf')
方案二:Python+selenium
selenium是很火的Python前端自动化测试框架,通过指定chrome浏览器的Driver,可以在有窗口或Headless的情况下进行截图,但是无法转换为PDF,也无法自动截取全高度网页,必须指定窗口大小
有点是ChromeDriver可以在Headless或窗口模式下执行,只需要指定--headless参数即可。这样就可以在程序执行的时候观察实际效果。并且selenium还可以在页面上执行自定义js代码,用来滚动屏幕,非常好用
下载ChromeDriver的地址是:https://sites.google.com/chromium.org/driver/downloads?authuser=0
from selenium import webdriver
from selenium.common.exceptions import WebDriverException
if __name__ == '__main__':
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('window-size=1920x1080')
try:
driver = webdriver.Chrome(executable_path='chromedriver_win32/chromedriver.exe', options=options)
# driver.get("file:///C:/map.html")
driver.get('https://echarts.apache.org/examples/zh/editor.html?c=graph')
driver.execute_script("window.scrollTo(0,100)")# 执行自定义JS滚动屏幕,可以动态测出整个body的宽度和高度
driver.set_window_size(2000, 2000) # 写死一个屏幕宽度和高度,高度可以超出显示器的物理高度,可以用动态测量的值,参考https://blog.csdn.net/BobYuan888/article/details/108769274
time.sleep(5)
driver.get_screenshot_as_file("echarts.png")
driver.quit()
except WebDriverException as err:
print("截图失败")
print(err)在get方法中,可以写http,https的互联网地址,也可以写本地文件的相对路径
方案三:Node+Puppeteer
Puppeteer是谷歌亲儿子,由谷歌主导的前端测试框架,与selenium类似,在Node会自动下载一个谷歌的开发板,可以选择Headless或窗口模式,默认为Headless,既可以截图,又可以保存为PDF,并且相比selenum,可以准确的测出完整页面的高度,对截图非常友好
官网:https://developers.google.com/web/tools/puppeteer/get-started
npm -i puppeteerconst puppeteer = require('puppeteer');
async function getPicFromHTML()
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setViewport(
width: 1920,
height: 1080,
deviceScaleFactor: 1,
)
await page.goto('https://html5test.com',waitUntil:"networkidle0");
//输出图片
await page.screenshot( path: 'example2.png', fullPage:true );
//输出pdf
await page.emulateMediaType('screen');
await page.pdf(path:"test.pdf",margin:top:100,bottom:100,format:'A4',landscape:true)
await browser.close();
在截图时,使用fullPage参数可以准确的截取整个网页的图片,非常友好。PDF模式下,只需指定纸张大小,无需关心高度
测试
下面我们以wkhtmltopdf来测试一下,如html5测试网站的截图
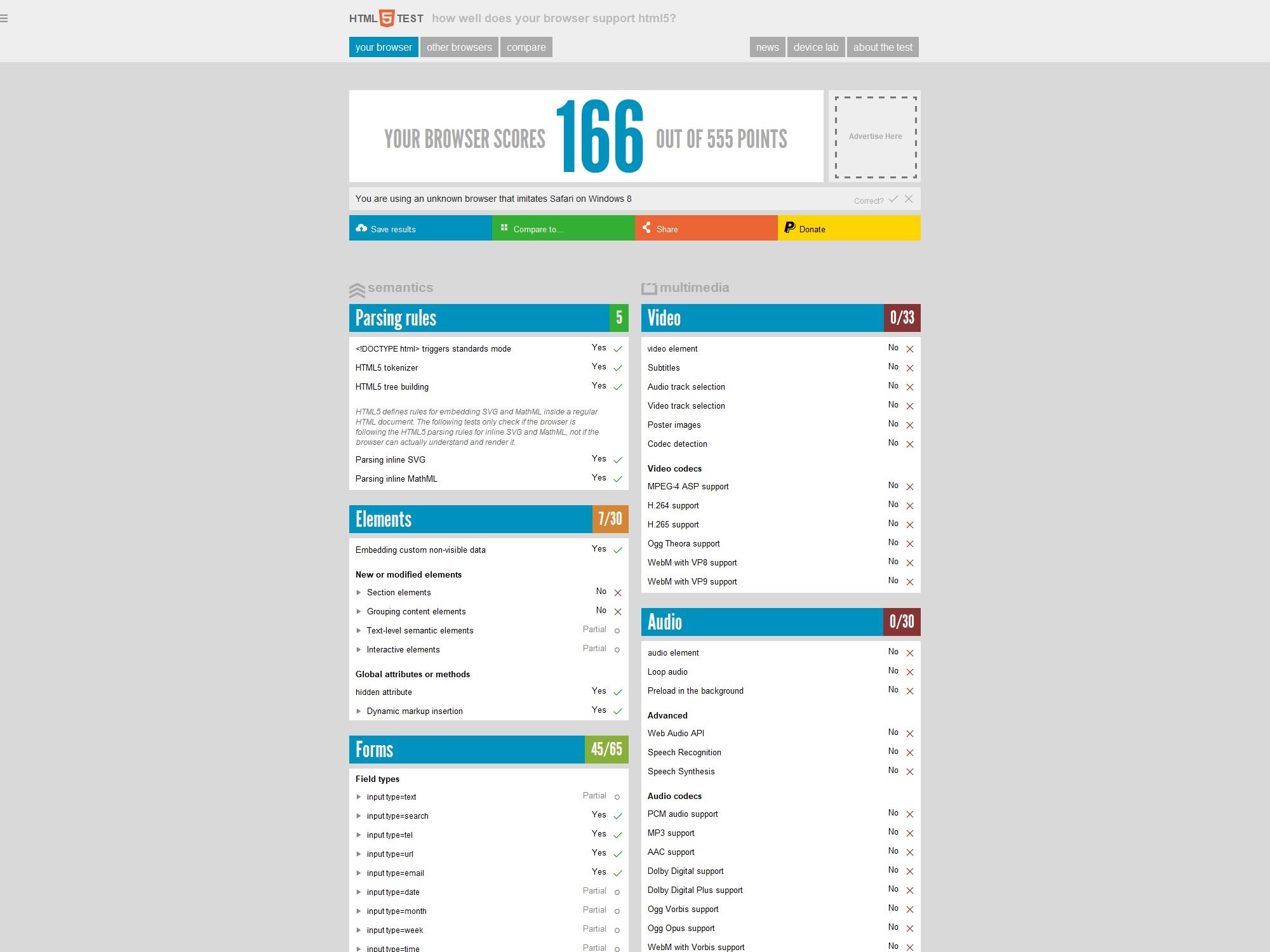
这个是指定height和width的最终截图,是不能截取整个页面的,分数166已经是低到了尘埃里,现在能用的浏览器往往在500分以上,就连微信自带的浏览器也是500+,钉钉自带浏览器400+
如果不指定height
options =
'javascript-delay': '8000',
'width': '2000'

会发现远超页面的实际大小,但是同样的问题,在保存为PDF的时候没有出现,高度刚刚好
再来测试一下对地图的支持,我们登陆高德开放平台自定义地图https://lbs.amap.com/tools/creater,浏览器打开实际的效果是这样子的,可以在地图上设置自己的标记,并生成HTML保存成文件
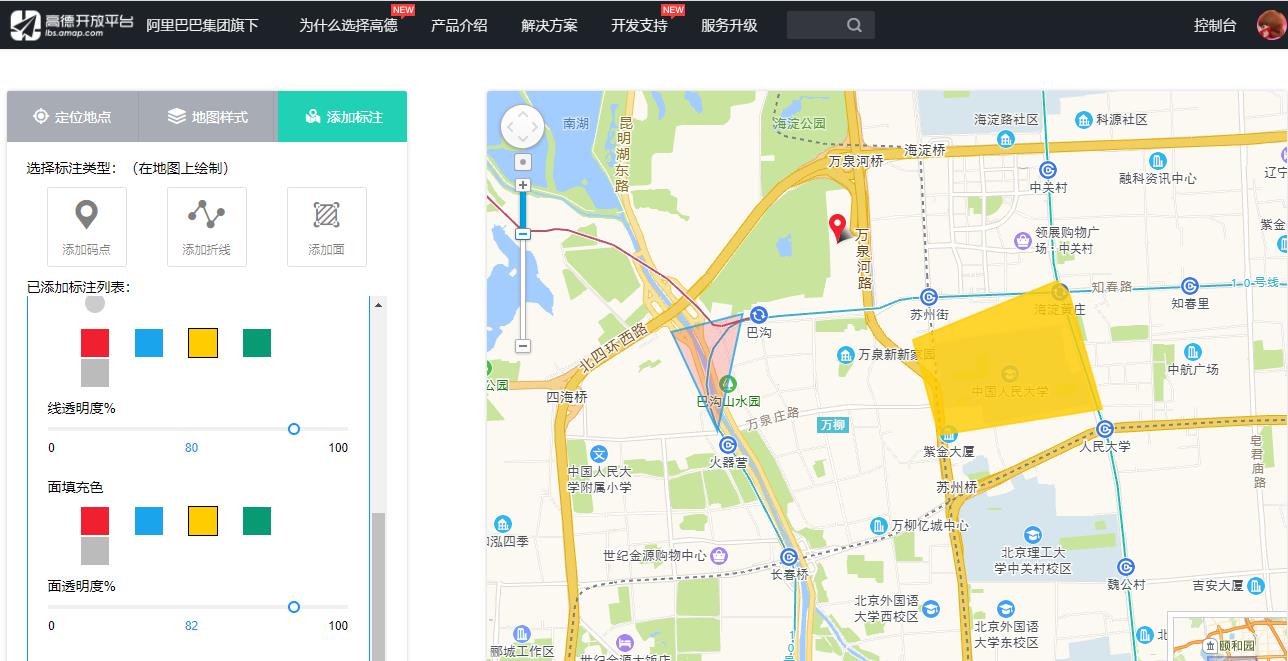
HTML如下
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="keywords" content="高德地图,DIY地图,高德地图生成器">
<meta name="description" content="高德地图,DIY地图,自己制作地图,生成自己的高德地图">
<title>高德地图 - DIY我的地图</title>
<style>
body margin: 0; font: 13px/1.5 "Microsoft YaHei", "Helvetica Neue", "Sans-Serif"; min-height: 960px; min-width: 600px;
.my-map margin: 0 auto; width: 800px; height: 640px; .my-map .icon background: url(http://a.amap.com/lbs-dev-yuntu/static/web/image/tools/creater/marker.png) no-repeat; .my-map .icon-cir height: 31px; width: 28px; .my-map .icon-cir-red background-position: -11px -5px;
.amap-containerheight: 100%;
.myinfowindowwidth: 240px;min-height: 50px;
.myinfowindow h5 height: 20px; line-height: 20px; overflow: hidden; font-size: 14px; font-weight: bold; width: 220px; text-overflow: ellipsis; word-break: break-all; white-space: nowrap;
.myinfowindow div margin-top: 10px; min-height: 40px; line-height: 20px; font-size: 13px; color: #6f6f6f;
</style>
</head>
<body>
<div id="wrap" class="my-map">
<div id="mapContainer"></div>
</div>
<script type="text/javascript" src="https://webapi.amap.com/maps?v=1.4.15&key=11sxxxxxxxxxxxxxxxxxxxxxxx"></script>
<script>
!function()
var infoWindow, map, level = 14,
center = lng: 116.302676, lat: 39.96818,
features = ["icon":"cir","color":"red","name":"未命名标注","desc":"未命名标注描述","lnglat":"Q":39.979098460047545,"R":116.29847035378219,"lng":116.29847,"lat":39.979098,"offset":"x":-9,"y":-31,"type":"Marker", "strokeWeight":2,"strokeColor":"#19A4EB","strokeOpacity":0.8,"fillColor":"#F0202F","fillOpacity":0.2,"name":"未命名标注","desc":"未命名标注描述","path":["Q":39.97456016252131,"R":116.29027352303268,"lng":116.290274,"lat":39.97456,"Q":39.973376209253196,"R":116.28417954415085,"lng":116.28418,"lat":39.973376,"Q":39.96686409967301,"R":116.28812775582077,"lng":116.288128,"lat":39.966864],"lnglat":"Q":39.96686409967301,"R":116.28812775582077,"lng":116.288128,"lat":39.966864,"type":"Polygon", "strokeWeight":2,"strokeColor":"#FFCC02","strokeOpacity":0.8,"fillColor":"#FFCC02","fillOpacity":0.82,"name":"未命名标注","desc":"未命名标注描述","path":["Q":39.972850001217346,"R":116.30490765541794,"lng":116.304908,"lat":39.97285,"Q":39.966600971094714,"R":116.30713925331833,"lng":116.307139,"lat":39.966601,"Q":39.968311288750215,"R":116.32112965554,"lng":116.32113,"lat":39.968311,"Q":39.97594141541203,"R":116.31829724282028,"lng":116.318297,"lat":39.975941,"Q":39.97673069024431,"R":116.31726727455856,"lng":116.317267,"lat":39.976731],"lnglat":"Q":39.97673069024431,"R":116.31726727455856,"lng":116.317267,"lat":39.976731,"type":"Polygon"];
function loadFeatures()
for(var feature, data, i = 0, len = features.length, j, jl, path; i < len; i++)
data = features[i];
switch(data.type)
case "Marker":
feature = new AMap.Marker( map: map, position: new AMap.LngLat(data.lnglat.lng, data.lnglat.lat),
zIndex: 3, extData: data, offset: new AMap.Pixel(data.offset.x, data.offset.y), title: data.name,
content: '<div class="icon icon-' + data.icon + ' icon-'+ data.icon +'-' + data.color +'"></div>' );
break;
case "Polyline":
for(j = 0, jl = data.path.length, path = []; j < jl; j++)
path.push(new AMap.LngLat(data.path[j].lng, data.path[j].lat));
feature = new AMap.Polyline( map: map, path: path, extData: data, zIndex: 2,
strokeWeight: data.strokeWeight, strokeColor: data.strokeColor, strokeOpacity: data.strokeOpacity );
break;
case "Polygon":
for(j = 0, jl = data.path.length, path = []; j < jl; j++)
path.push(new AMap.LngLat(data.path[j].lng, data.path[j].lat));
feature = new AMap.Polygon( map: map, path: path, extData: data, zIndex: 1,
strokeWeight: data.strokeWeight, strokeColor: data.strokeColor, strokeOpacity: data.strokeOpacity,
fillColor: data.fillColor, fillOpacity: data.fillOpacity );
break;
default: feature = null;
if(feature) AMap.event.addListener(feature, "click", mapFeatureClick);
function mapFeatureClick(e)
if(!infoWindow) infoWindow = new AMap.InfoWindow(autoMove: true,isCustom: false);
var extData = e.target.getExtData();
infoWindow.setContent("<div class='myinfowindow'><h5>" + extData.name + "</h5><div>" + extData.desc + "</div></div>");
infoWindow.open(map, e.lnglat);
map = new AMap.Map("mapContainer", center: new AMap.LngLat(center.lng, center.lat), level: level, keyboardEnable:true, dragEnable:true, scrollWheel:true, doubleClickZoom:true);
loadFeatures();
map.on('complete', function()
map.plugin(["AMap.ToolBar", "AMap.OverView", "AMap.Scale"], function()
map.addControl(new AMap.ToolBar(ruler: true, direction: true, locate: false)); map.addControl(new AMap.OverView(isOpen: true)); map.addControl(new AMap.Scale);
);
)
();
</script>
</body>
</html>截图效果如下

效果非常好,除了高度测算的不准以外,截图和转PDF都成功的把地图上的标记,水印都完整的截取下来了
下面再测试以下图标,下面以最近很火的echarts库为例,页面代码如下
<!--
THIS EXAMPLE WAS DOWNLOADED FROM https://echarts.apache.org/examples/zh/editor.html?c=tree-orient-bottom-top
-->
<!DOCTYPE html>
<html style="height: 100%">
<head>
<meta charset="utf-8">
</head>
<body style="height: 100%; margin: 0">
<div id="container" style="height: 100%"></div>
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/echarts@5/dist/echarts.min.js"></script>
<script type="text/javascript" src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<!-- Uncomment this line if you want to use gl extension
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/echarts-gl@2/dist/echarts-gl.min.js"></script>
-->
<!-- Uncomment this line if you want to echarts-stat extension
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/echarts-stat@latest/dist/ecStat.min.js"></script>
-->
<!-- Uncomment this line if you want to use map
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/echarts@5/map/js/china.js"></script>
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/echarts@5/map/js/world.js"></script>
-->
<!-- Uncomment these two lines if you want to use bmap extension
<script type="text/javascript" src="https://api.map.baidu.com/api?v=2.0&ak=<Your Key Here>"></script>
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/echarts@5/dist/extension/bmap.min.js"></script>
-->
<script type="text/javascript">
var dom = document.getElementById("container");
var myChart = echarts.init(dom);
var app = ;
var ROOT_PATH = 'https://cdn.jsdelivr.net/gh/apache/echarts-website@asf-site/examples';
var option;
myChart.showLoading();
$.get(ROOT_PATH + '/data/asset/data/flare.json', function (data)
myChart.hideLoading();
myChart.setOption(option =
tooltip:
trigger: 'item',
triggerOn: 'mousemove'
,
series:[
type: 'tree',
data: [data],
left: '2%',
right: '2%',
top: '20%',
bottom: '8%',
symbol: 'emptyCircle',
orient: 'BT',
expandAndCollapse: true,
label:
position: 'bottom',
rotate: 90,
verticalAlign: 'middle',
align: 'right'
,
leaves:
label:
position: 'top',
rotate: 90,
verticalAlign: 'middle',
align: 'left'
,
emphasis:
focus: 'descendant'
,
animationDurationUpdate: 750
]
);
);
if (option && typeof option === 'object')
myChart.setOption(option);
</script>
</body>
</html>
使用wkhtmltopdf输出pdf或截图,只有一个白色背景,什么都没有,说白了就是不支持echarts,估计与QtWebkit对HTML5支持太差有关,而selenium和Puppeteer使用chrome浏览器的开源最新chromium内核,对H5的支持非常好,截图效果如下:
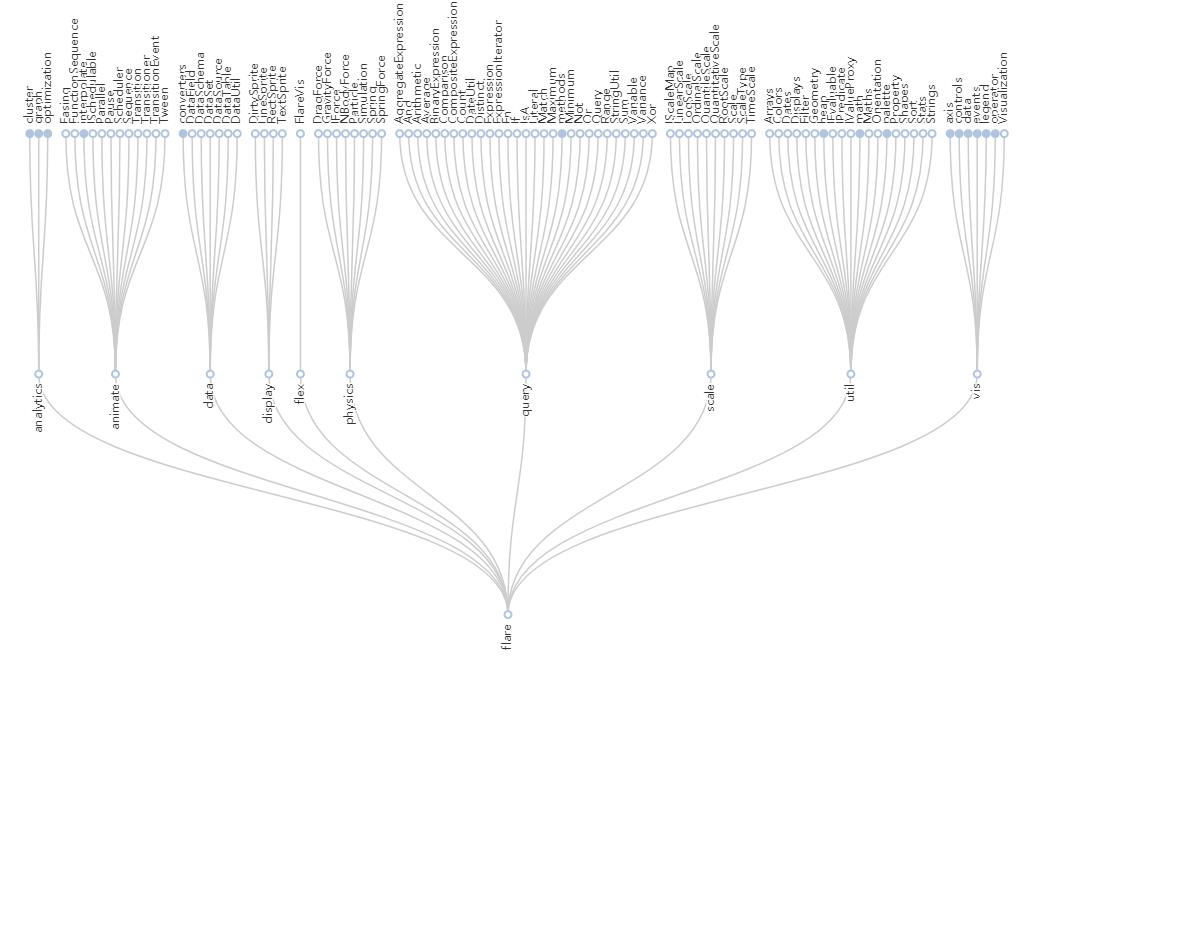
三个方案经过测试汇总如下
| 方案 | 窗口模式 | 后台模式 | 截图 | 截图完整页面 | HTML5支持性 | PDF完整页面 | 地图 | echarts | BootStrap | |
| wkhtmltopdf | 不支持 | 支持 | 支持 | 高度不准 | 166 | 支持 | 支持 | 支持 | 不支持 | 部分支持 |
| selenium | 支持 | 支持 | 支持 | 不支持 | 528 | 不支持 | —— | 支持 | 支持 | 支持 |
| Puppeteer | 支持 | 支持 | 支持 | 支持 | 528 | 支持 | 支持 | 支持 | 支持 | 支持 |
以上是关于python 遍历文件夹PDF并转换成图片?的主要内容,如果未能解决你的问题,请参考以下文章